大数据(2) - Hadoop完全分布式的部署
** Hadoop介绍
** HDFS:分布式存储文件
角色:NameNode和DataNode
** YARN:分布式资源调度框架(Hadoop2.x以上才引用)
角色:ResourceManager和NodeManager
** MapReduce:分布式数据处理框架
一、下载hadoop拉到linux中,并解压到指定目录
tips:用smb把hadoop压缩包从window拉到linux时,请注意smb的登陆用户,会导致后面一堆坑,慎用root登陆smb。
(1)将压缩包拉到/home/admin/softwares/installtions/目录
(2) 解压到/home/admin/modules目录
tar -zxf hadoop-2.7.2.tar.gz -C /home/admin/modules/
二、配置环境变量
vim /etc/profile 在最下面添加 export HADOOP_HOME=/home/admin/modules/hadoop-2.7.2/bin
export PATH=$PATH:$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib:$HADOOP_COMMON_LIB_NATIVE_DIR" 保存退出后 source /etc/profile
配置成功后可用 hadoop version 查看版本,注意没有横杠!
三、配置
** 最终配置效果:
linux01:namenode、datanode、nodemanager
linux02:resourcemanager 、datanode 、nodemanager
linux03:datanode、nodemanager
(1)删除windows脚本
** 进入到hadoop的etc/hadoop目录下 $ rm -rf *.cmd
(2)重命名文件
$ mv mapred-site.xml.template mapred-site.xml
(3)配置evn文件
查看java路径:
echo $JAVA_HOME,我的机器:/home/admin/modules/jdk1.8.0_131

配置hadoop-env.sh
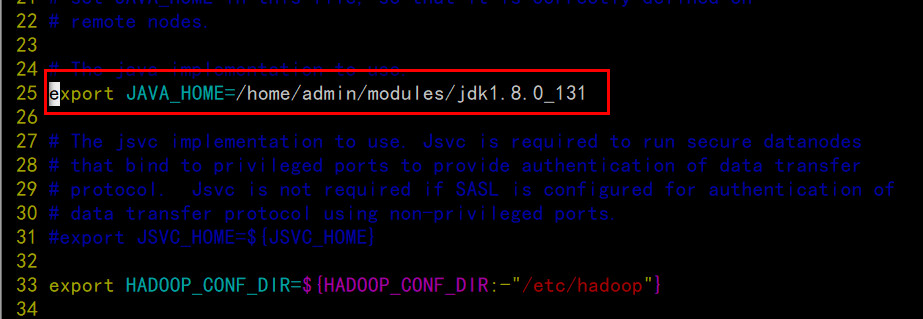
配置yarn-env.sh
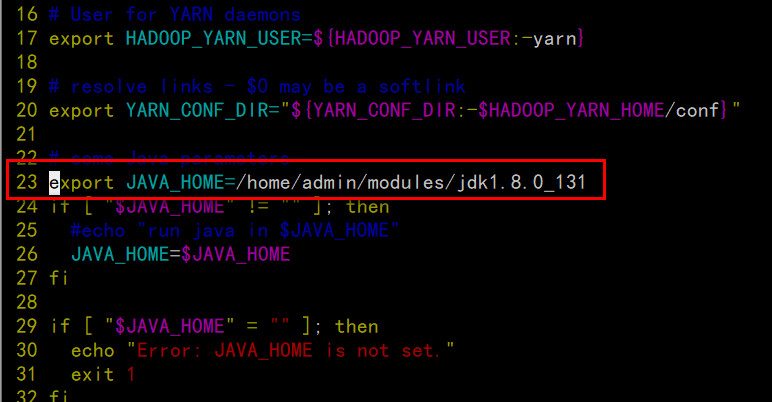
配置mapred-env.sh

(4)配置site文件
配置 core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://linux01:8020</value>
</property> <property>
<name>hadoop.tmp.dir</name>
<value>/home/admin/modules/hadoop-2.7.2/hadoop-data</value>
</property>
</configuration>
配置hdfs-site.xml
<configuration>
<!-- 指定数据冗余份数 -->
<property>
<name>dfs.replication</name>
<value>1</value>
</property> <!-- 关闭权限检查-->
<property>
<name>dfs.permissions.enable</name>
<value>false</value>
</property> <property>
<name>dfs.namenode.secondary.http-address</name>
<value>linux03:50090</value>
</property> <property>
<name>dfs.namenode.http-address</name>
<value>linux01:50070</value>
</property> <property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
</configuration>
配置yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property> <property>
<name>yarn.resourcemanager.hostname</name>
<value>linux02</value>
</property> <property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property> <property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>86400</value>
</property> <property>
<name>yarn.log.server.url</name>
<value>http://linux01:19888/jobhistory/logs/</value>
</property> </configuration>
配置mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- 配置 MapReduce JobHistory Server 地址 ,默认端口10020 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>linux01:10020</value>
</property> <!-- 配置 MapReduce JobHistory Server web ui 地址, 默认端口19888 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>linux01:19888</value>
</property>
</configuration>
(5)配置slaves文件

四、分发安装配置完成的hadoop到linux02以及linux03
$ scp -r hadoop-2.7.2/ linux02:/home/admin/modules/
$ scp -r hadoop-2.7.2/ linux03:/home/admin/modules/
五、 格式化namenode(在hadoop-2.7.2的根目录下执行)
$ bin/hdfs namenode -format
如果正常格式化会生成haddop-data文件夹
六、启动服务
HDFS:(linux01)
$ sbin/start-dfs.sh
YARN:(一定要在ResourceManager所在机器启动,linux02)
$ sbin/start-yarn.sh
JobHistoryServer:(linux01)
$ ssh admin@linux01 '/home/admin/modules/hadoop-2.7.2/sbin/mr-jobhistory-daemon.sh start historyserver'
常见启动失败情况:
(1)hadoop处于安全模式,namenode启动失败,参考链接
解决:磁盘空间不足,需要手动释放资源后再用命令 hdfs dfsadmin -safemode leave 离开安全模式
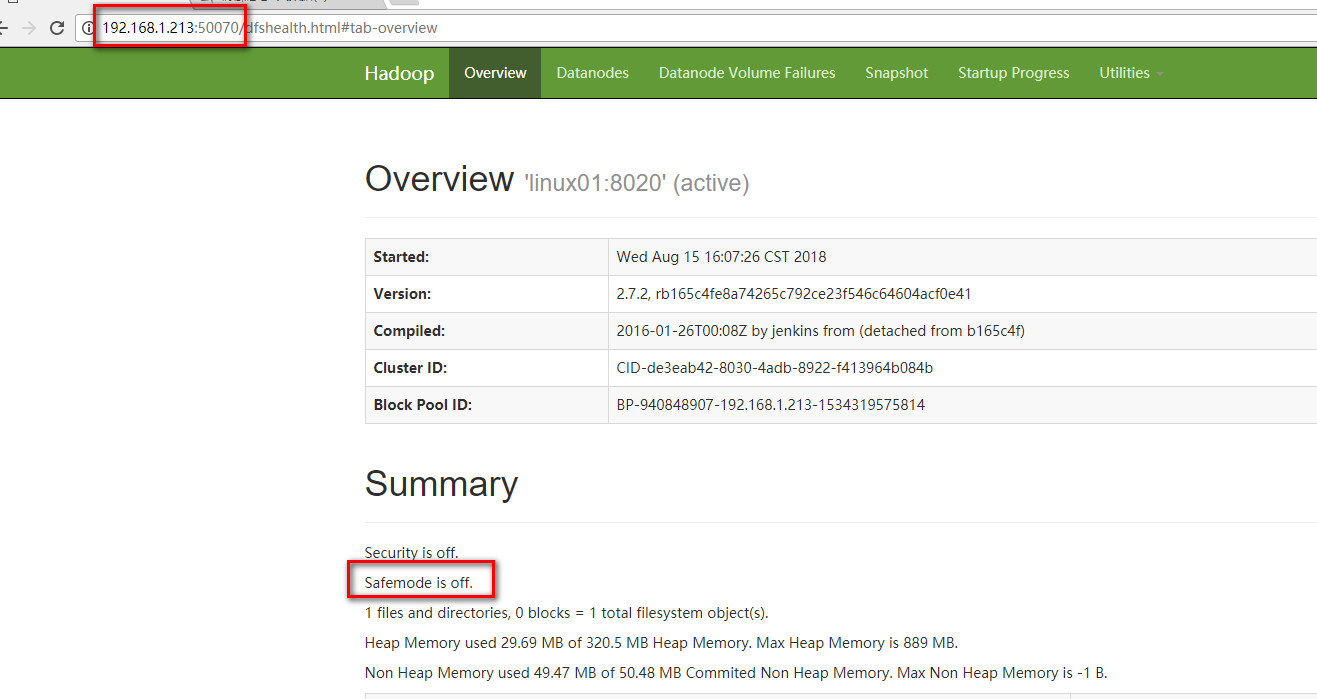
全部完成后查看:
在浏览器输入192.168.1.213:50070,如果不在安全模式证明namenode启动正常
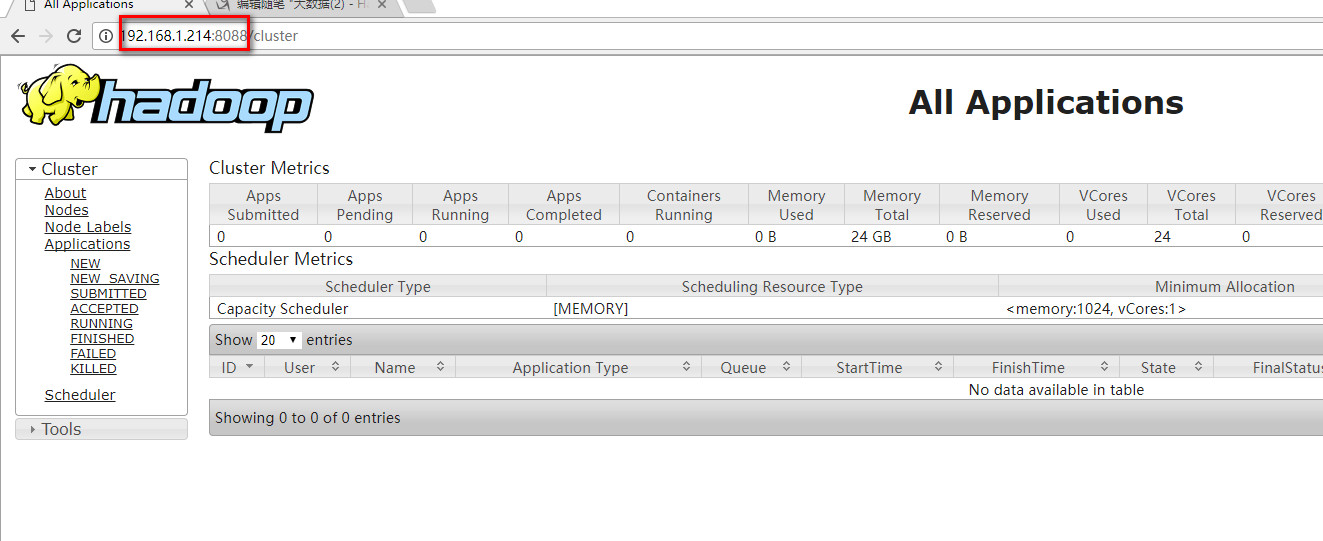
输入192.168.1.214:8088
七、关闭全部服务
$ sbin/stop-all.sh
八、将系统变量追加到用户变量中(3台机器都要操作)
$ cd ~ $ cat /etc/profile >> .bashrc
生效 $ source ~/.bashrc
九、编写脚本批量操作三台机器
$ cd ~
$ mkdir tools
$ vim /tools/jpsutil.sh 添加批量查看jps服务的脚本 #!/bin/bash
for i in admin@linux01 admin@linux02 admin@linux03
do
echo "==================$i==================="
ssh $i 'jps'
done 保存后查看 sh jpsutil.sh
十、遇到问题
关闭虚拟机后重启,重启集群时,namenode启动失败,需要使用命令:bin/hdfs namenode -format
格式化,才能启动。
格式化后datanode又有异常,需要把/hadoop-2.7.2/hadoop-data/dfs/name/current/VERSION里面的clusterID复制下来,依次替换/hadoop-2.7.2/hadoop-data/dfs/data/current/VERSION里的clusterID,再执行:sbin/hadoop-daemon.sh start datanode(全部机器都要操作)。
格式化会导致集群原本存储的数据全部丢失,如何正常关机后,正常开启集群,这个有待研究。
最新文章
- Android搜索功能的案例,本地保存搜索历史记录......
- vs2015打包winform程序遇到的一系列问题
- Selenium_Selenium WebDriver 中鼠标和键盘事件分析及扩展
- centos下linux运行asp网站搭建配置-mono+nginx
- SpringMVC系列之基本配置
- WPF登陆窗口、主窗口切换问题
- 将Spark中CompactBuf转换为String
- c++时间处理
- [系统开发] Postfix 邮件管理系统
- IMAP收邮件
- BZOJ 3143 HNOI2013 游走 高斯消元 期望
- (转)android底部弹出iOS7风格对话选项框(QQ对话框)--第三方开源--IOS_Dialog_Library
- cglib源码分析(四):cglib 动态代理原理分析
- WAF
- 用Javascript进行HTML转义(分享)
- Fedora、CentOS install TTF/otf fonts
- 语义化标签SEO
- swift 2 选择头像图片
- Head First 设计模式 第4章工厂模式
- JDBC操作数据库之批处理