【Python3 爬虫】06_robots.txt查看网站爬取限制情况
2024-08-23 20:14:59
大多数网站都会定义robots.txt文件来限制爬虫爬去信息,我们在爬去网站之前可以使用robots.txt来查看的相关限制信息
例如:
我们以【CSDN博客】的限制信息为例子
在浏览器输入:https://blog.csdn.net/robots.txt
获取到信息如下:
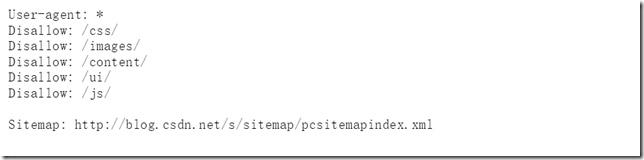
从上图我们可以看出:
①该网站无论用户使用哪种代理都允许爬取
②但是当爬取/css,/images…等链接的时候是禁止的
③我们可以看到还存在一个网址Sitemap,j具体解析如下:
网站提供的Sitemap文件(即网站地图)可以帮助网站定位最新的内容,则无须爬取每一个网页,虽然Sitemap文件提供了一种爬取网站的有效方式,但是我们仍然需要对其谨慎处理,因为该文件经常存在缺失,过期和不完整。
最新文章
- Mono+Jexus部署C# MVC的各种坑
- Python的数据类型
- Wakez计算与压缩的思考
- [转]Design Pattern Interview Questions - Part 4
- 2种方式解决nginx负载下的Web API站点里swagger无法使用
- Eclipse启动时选择workspace设置
- 使用yum来安装或卸载CentOS图形界面包
- 前端里神奇的BFC 原理剖析
- WebView注入Java对象注意事项
- 使用 IntraWeb (42) - 测试读取 SqLite (一)
- Google Developers中国网站
- MVC View基础(转)
- js获取手机重力感应api
- iScroll的简单使用
- Java学习笔记(5)
- SpringBoot之整合Mybatis范例
- 【Cocos2d-html5】运动中速度效果
- Uva 12124 Uva Live 3971 - Assemble 二分, 判断器, g++不用map.size() 难度:0
- redis 简介,安装与部署
- linux操作系统基础讲解