HBase读写数据的详细流程及ROOT表/META表介绍
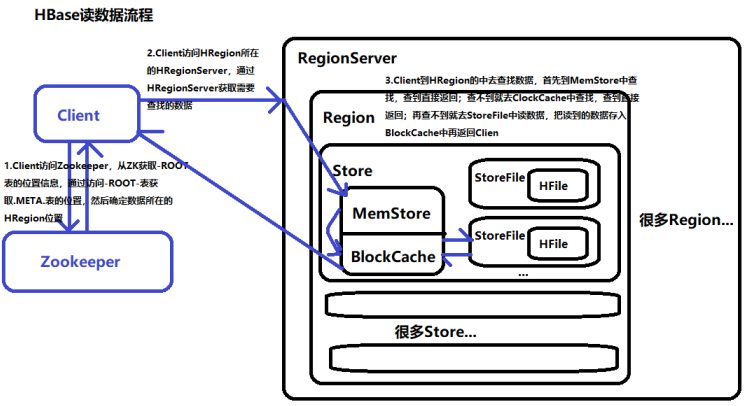
一、HBase读数据流程
1.Client访问Zookeeper,从ZK获取-ROOT-表的位置信息,通过访问-ROOT-表获取.META.表的位置,然后确定数据所在的HRegion位置;
2.Client访问HRegion所在的HRegionServer,通过HRegionServer获取需要查找的数据;
3.Client到HRegion的中去查找数据,首先到MemStore中查找,查到直接返回;查不到就去ClockCache中查找,查到直接返回;再查不到就去StoreFile中读数据,把读到的数据存入BlockCache中再返回Client。
如图:
二、HBase写数据流程
1.Client通过Zookeeper调度获取表的元数据信息;
2.Cilent通过rpc协议与RegionServer交互,通过-ROOT-表与.META.表找到对应的对应的Region;
3.将数据写入HLog日志中,如出现意外可以同通过HLog恢复信息;
4.将数据写入Region的MemStore中,当MemStore达到阈值开始溢写,将其中的数据Flush成一个StoreFile;
5.MemStore不断生成新的StoreFile,当StoreFile的数量到达阈值后会出发Compact合并操作,将多个StoreFile合并成一个StoreFile;
6.StoreFile文件会不断增大,当达到阈值后会出发Split操作,把当前的Region且分为两个新的Region。父Region会下线,两个子Region会被HMaster分配到相应的RegionServer。
图略、自己脑补一哈把~~
*********************************************************************************************
补充:1.由读写数据的流程可以发现,Region中的内存分为两块:MemStore(负责写数据)、BlockCache(负责读数据),这是HBase的一大特点——读写分离,这也是HBase读写速度极快的原因之一;
2.在HBase中,可以看出只有增添操作,所有的更新和删除都是在后续的Compact合并历程中进行的,这使得用户的写操作只有进入内存就可以立刻返回,实现了I/O的高性能。
*********************************************************************************************
三、-ROOT-表和.META.表的介绍
HBase用-ROOT-表记录.META.表的位置信息(即元数据信息),而.META.表记录了用户表Region的位置信息。
为了定位.META.表中各个Region的位置信息,把.META.表中所有Region的元数据保存在-ROOT-表中,最后由Zookeeper记录-Root-表的位置信息。
所以客户端Client要先访问ZK获取-ROOT-表的位置,然后访问-ROOT-表获取.META.表的位置,最后根据.META.表中的信息确定用户数据存放的位置。
最新文章
- 使用 jQuery Mockjax 插件模拟 Ajax 请求
- SharePoint2010升级到SharePoint2013操作手册
- 谈谈软件项目的dependency
- Maven+Spring Batch+Apache Commons VF学习
- GDB调试详解
- 从实践谈iOS生命周期
- javascript变量,作用域和内存问题(一)
- do-while循环判断成绩的有效输入
- Angularjs $http服务的两个request安全问题
- Solr中在使用过程中遇到的"与"和"或"的问题
- VSCode 启动 Vue 项目 npm install 报错
- Effective Java 第三版——60. 需要精确的结果时避免使用float和double类型
- leetcode 566. 重塑矩阵 c++ 实现
- 20151224今天发现到的两篇关于CSS架构、可复用可维护CSS和CSS学习提升能有改变思想观念意识的文章 分别是CSS架构目标和说说CSS学习中的瓶颈
- 手把手JDK环境变量配置
- EMCA和EMCTL的简单用法
- Jmeter发送Json请求
- Hibernate架构
- java持有对象【2】ArrayList容器续解
- CyclicBarrier和CountDownLatch笔记