HashMap源码(一)
本文主要是从学习的角度看HashMap源码
HashMap的数据结构
- HashMap是一个数组+链表的结构(链表散列),每个节点在HashMap中以一个Node存在;
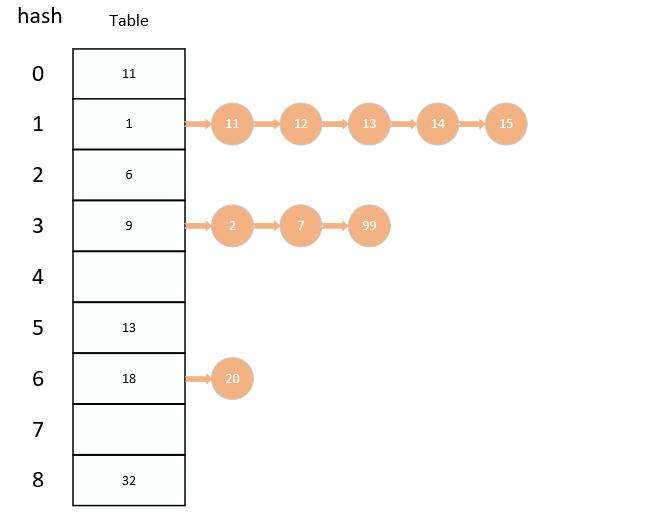
HashMap的初始化
public HashMap(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
// 这里的MAXIMUM_CAPACITY=1 << 30(问题一: 为什么是30?)
if (initialCapacity > MAXIMUM_CAPACITY)
// 如果传入初始值大于1<<30 则默认值为最大;
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
this.loadFactor = loadFactor;
// 这里是根据传入的初始值算得 大于输入参数且最近的2的整数次幂的数
this.threshold = tableSizeFor(initialCapacity);
}
HashMap中初始化方法如上。
- initialCapacity参数为初始化大小的值,默认为16,问题二:这里为什么为16?;
- loadFactor参数我理解为扩容权重比,默认值为0.75,问题三:这里为什么是0.75?,就是当HashMap的容量达到HashMap的数组长度*loadFactor时就会进行扩容。也就是HashMap中的 resize 方法
初始化方法代码不多,此处为了效率运用了很多的位运算;
首先: 为什么HashMap的容量永远是2的整数倍?
- 首先我们可以看源码知道HashMap中元素的位置计算是 hash & (n- 1),为啥要这么算我也不知道,反正这样的算法下 如果hashmap的长度刚好是2的倍数那么元素的分布相对来说是比较均匀的。减少元素碰撞的几率; 具体详细的可以看下这篇博文
- 所以这也解释了问题二的初始值为16即2的四次方;至于为啥一定是16,我也不知道,可能我比较杠精;
- 更新(12-11 ): 此处为什么是16在关于这个默认容量的选择,JDK并没有给出官方解释,我也没有在网上找到关于这个任何有价值的资料。(如果哪位有相关的权威资料或者想法,可以留言交流)
- 更新(12-23):详见问题二
问题一:MAXIMUM_CAPACITY = 1 << 30
- 首先这个值符合上面的原则,即大小为2的整数倍;而1<<30这个值我们可以尝试发现:
System.out.println(1<<30); // 1073741824
System.out.println(1<<31); // -2147483648
System.out.println(1<<32); // 1
- 因为int类型是32位整型,1左移31位的为 16进制的0x80000000代表的是-2147483648, 所以最大值只能为1>>30;至于为什么初始值不用Integer.MAX_VALUE,其实在resize方法中有下面这段代码:
if (oldCap >= MAXIMUM_CAPACITY) {
//若数组长度大于1>>30,这里则扩容Integer.MAX_VALUE;
threshold = Integer.MAX_VALUE;
return oldTab;
}
问题二:initialCapacity初始值为16
因为在使用是2的幂的数字的时候,Length-1的值是所有二进制位全为1,这种情况下,index的结果等同于HashCode后几位的值。
只要输入的HashCode本身分布均匀,Hash算法的结果就是均匀的。
这是为了实现均匀分布。
问题三: loadFactor默认值0.75
JDK 1.7中:
As a general rule, the default load factor (.75) offers a good tradeoff between time and space costs. Higher values decrease the space overhead but increase the lookup cost (reflected in most of the operations of the HashMap class, including get and put). The expected number of entries in the map and its load factor should be taken into account when setting its initial capacity, so as to minimize the number of rehash operations. If the initial capacity is greater than the maximum number of entries divided by the load factor, no rehash operations will ever occur.
翻译过来就是:
作为一般规则,默认负载因子(0.75)在时间和空间成本上提供了很好的折衷。较高的值会降低空间开销,但提高查找成本(体现在大多数的HashMap类的操作,包括get和put)。设置初始大小时,应该考虑预计的entry数在map及其负载系数,并且尽量减少rehash操作的次数。如果初始容量大于最大条目数除以负载因子,rehash操作将不会发生。理想状态下,在随机哈希值的情况,对于loadfactor = 0.75 ,虽然由于粒度调整会产生较大的方差,桶中的Node的分布频率服从参数为0.5的泊松分布。
接下来我们会具体看下HashMap的resize方法
博文推荐:https://www.hollischuang.com/archives/4320 (掘金看见的,写的很好)
最新文章
- Linux 基础笔记
- MongoDB(五)mongo语法和mysql语法对比学习
- Html5拖拽复制
- ZendGuardLoader安装
- heroku空间部署步骤
- Solr学习笔记之2、集成IK中文分词器
- laravel扩展xls处理maatwebsite/excel
- Spring在代码中获取bean的几种方式
- vc调用BCB的dll 参数传递 报错
- codesmith的使用
- NHibernate -- HQL
- .net mvc mssql easyui treegrid 及时 编辑 ,支持拖拽
- struts升级到最高版本后遇到的问题。关于actionmessage传递问题。
- Qt5:Qt中一些函数功能介绍
- bzoj3991 [Sdoi2015]寻宝游戏 set动态维护虚树+树链求并
- Bootstrap学习笔记(二)---常见工具和流程导航范例
- javascript基础修炼(6)——前端路由的基本原理
- 【Python】图形界面
- 【Ubuntu】录屏软件
- .NET 下第一次接触Redis数据库