第四十九篇 入门机器学习——数据归一化(Feature Scaling)
2024-10-12 02:49:59
No.1. 数据归一化的目的
数据归一化的目的,就是将数据的所有特征都映射到同一尺度上,这样可以避免由于量纲的不同使数据的某些特征形成主导作用。
No.2. 数据归一化的方法
数据归一化的方法主要有两种:最值归一化和均值方差归一化。
最值归一化的计算公式如下:

最值归一化的特点是,可以将所有数据都映射到0-1之间,它适用于数据分布有明显边界的情况,容易受到异常值(outlier)的影响,异常值会造成数据的整体偏斜。
均值方差归一化的计算公式如下:
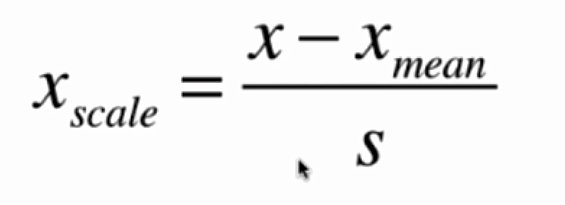
均值方差归一化的特点是,可以将数据归一化到均值为0方差为1的分布中,不容易受到异常值(outlier)影响。
No.3. 向量和矩阵的最值归一化
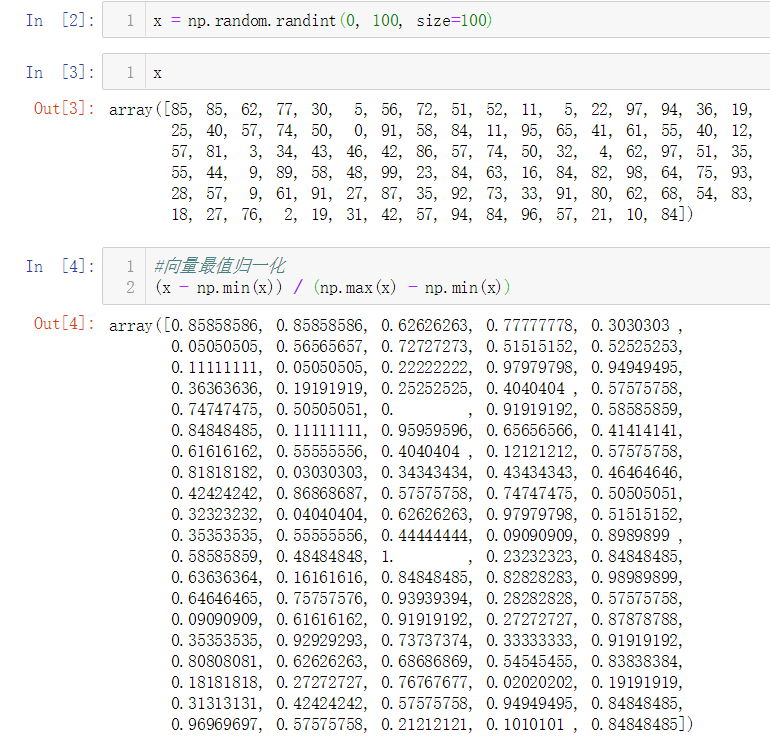
向量的最值归一化
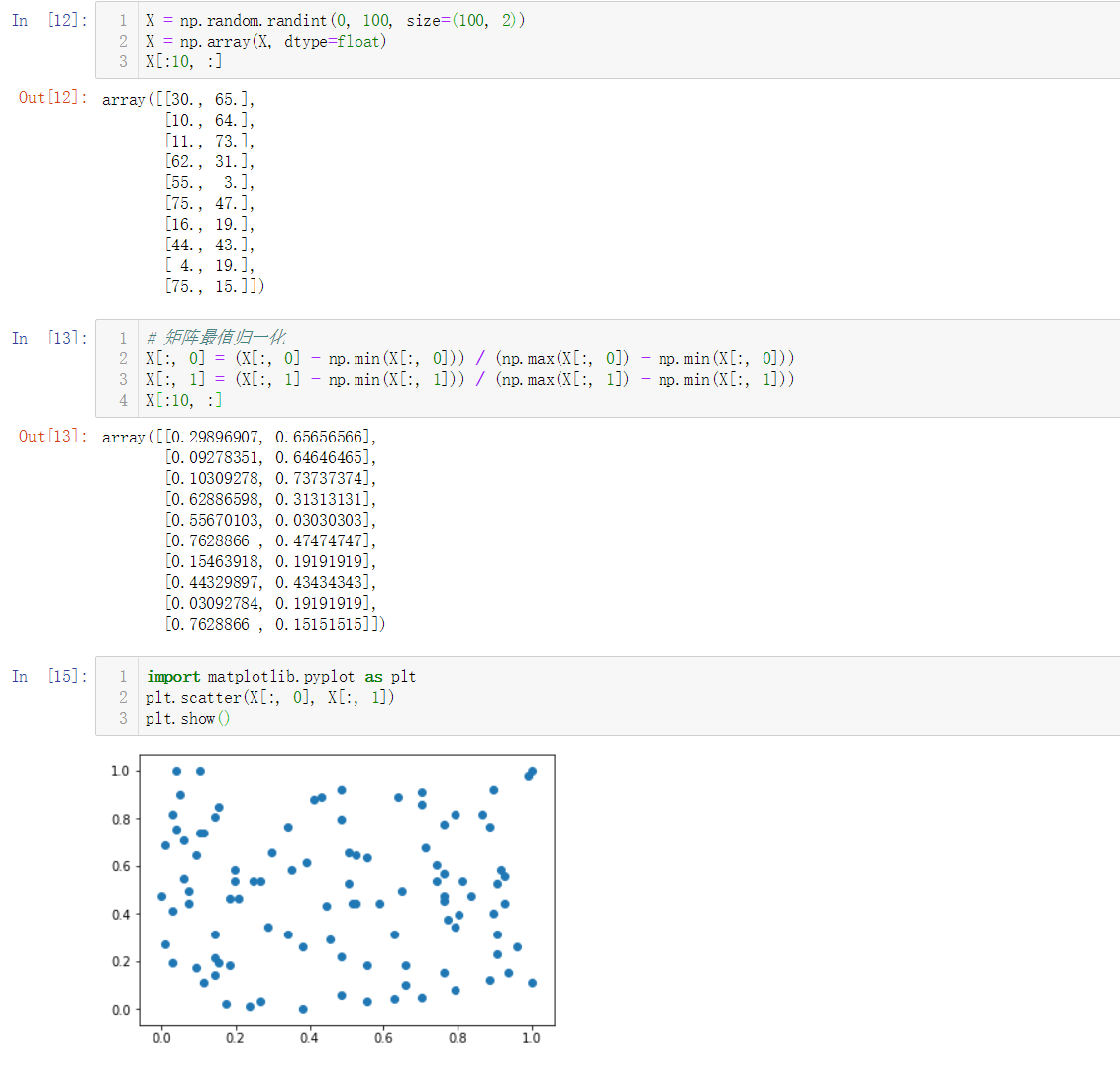
矩阵的最值归一化
No.4. 向量和矩阵的均值方差归一化
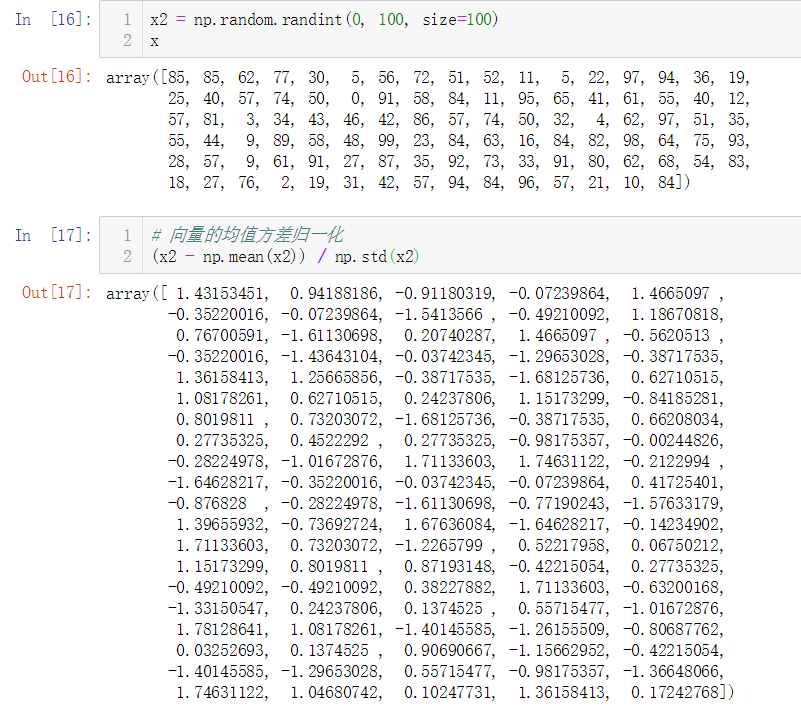
向量的均值方差归一化
矩阵的均值方差归一化
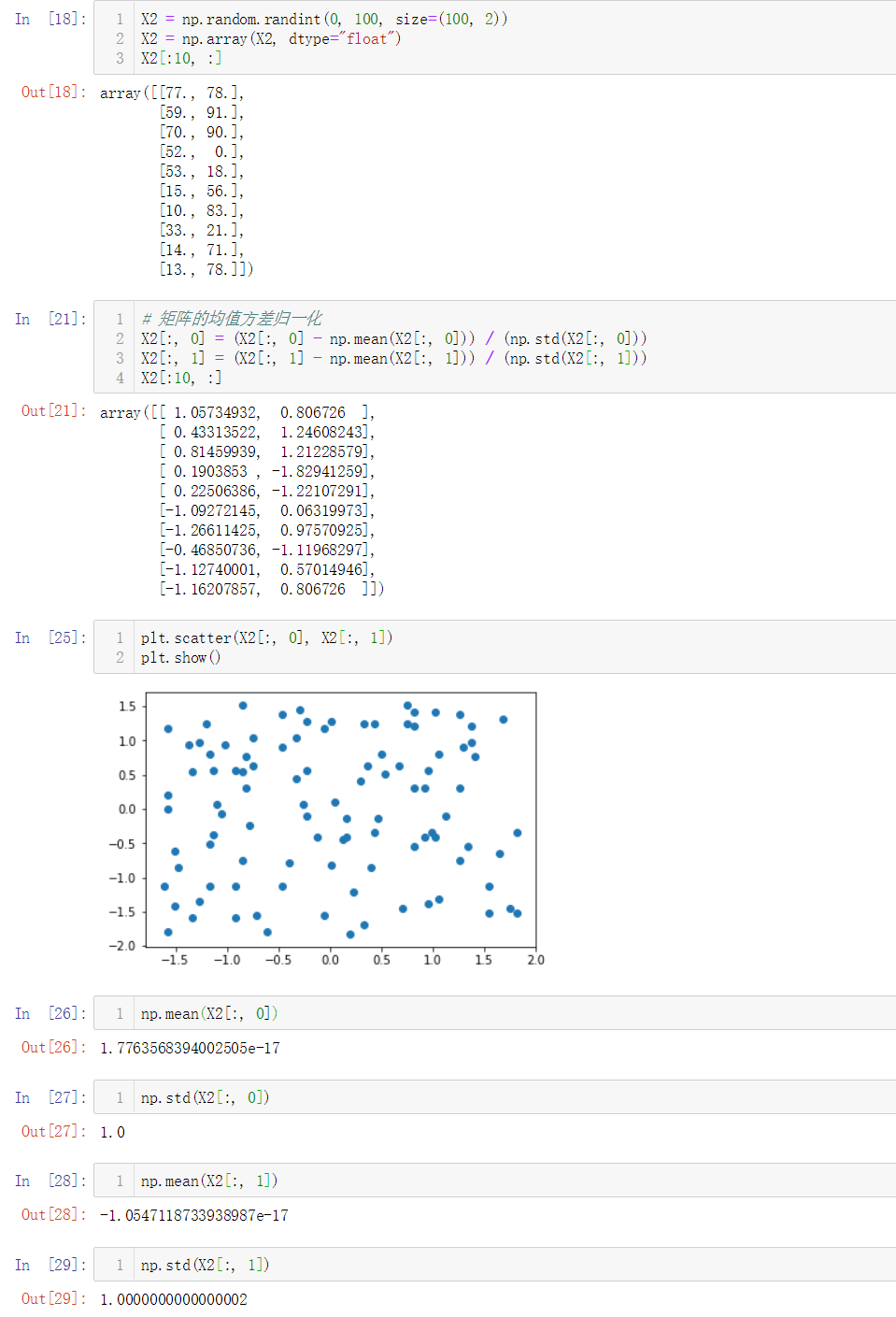
No.5. sklearn中对数据集归一化的流程
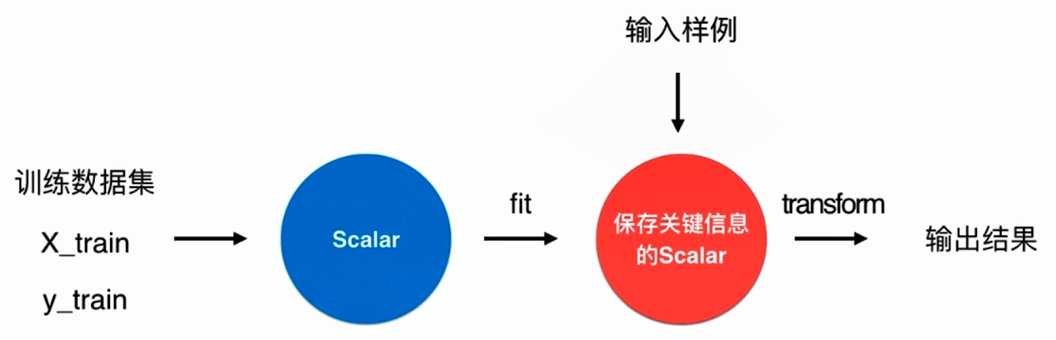
No.6. 使用鸢尾花数据集进行数据归一化
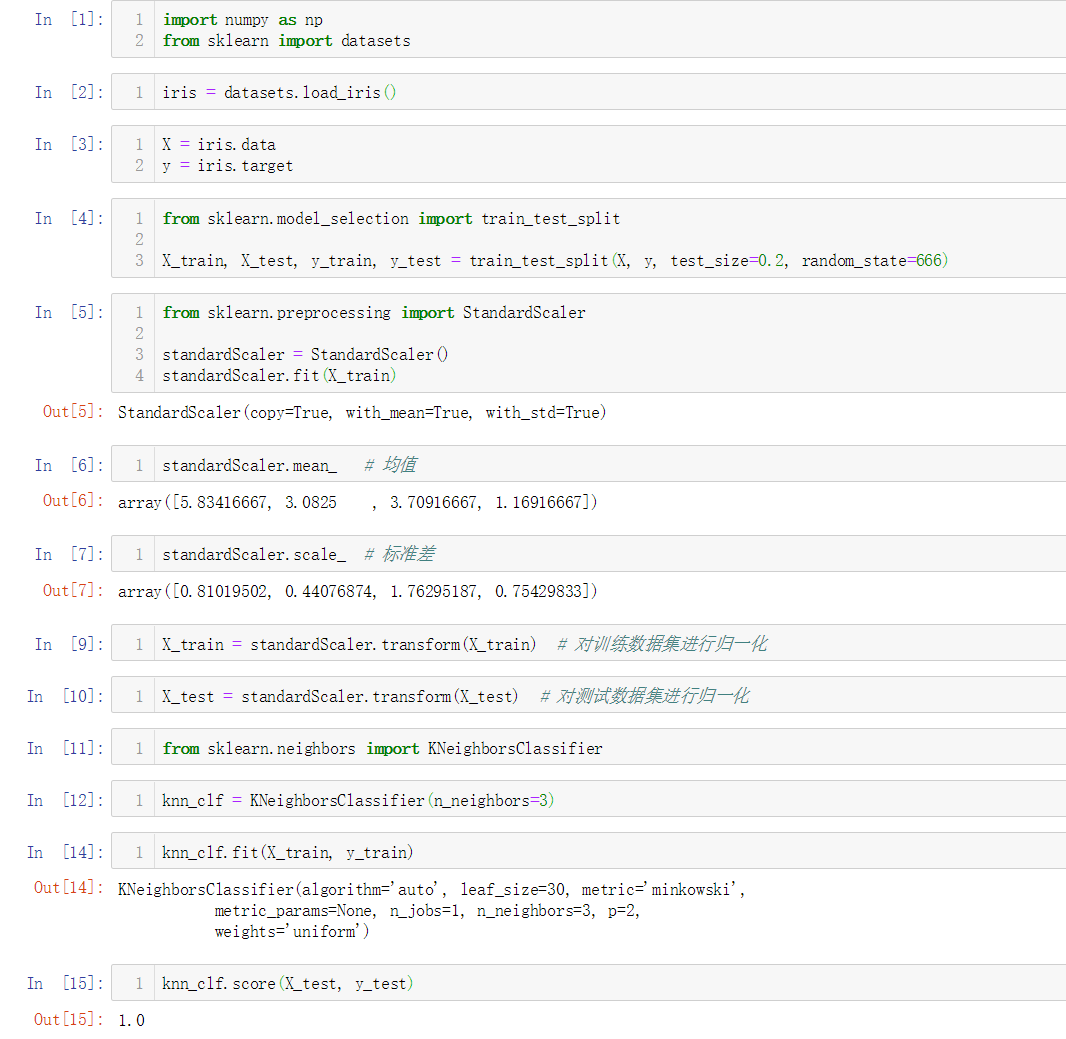
No.7. 简单实现一个自己的StandardScaler类

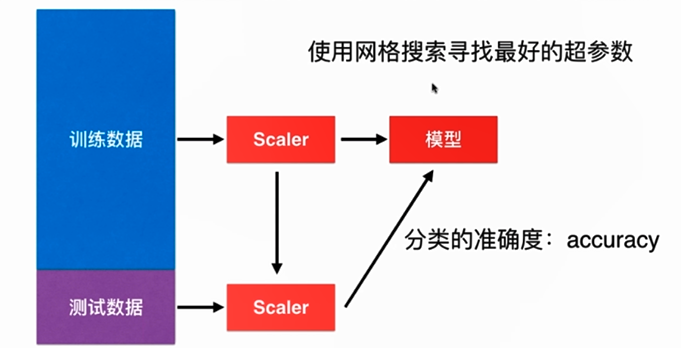
No.8. 机器学习流程回顾:
首先我们需要将数据集分成训练数据集和测试数据集两部分;对于kNN这种算法,我们需要保证数据在同一尺度下,因此要进行数据的归一化,训练数据集通过一个Scaler进行数据的归一化;将归一化后的数据进行训练,训练过程中要使用网格搜索来寻找最好的超参数,训练后得到最终的模型;之后,对于测试数据集,需要使用相同的Scaler进行归一化,然后送进用训练数据集得到的模型,得到模型分类的准确度,这样就可以确定训练数据集得到的模型的优劣。
最新文章
- python gettitle.py
- 数据存储_ SQLite (1)
- 半透明状态栏(适用于搜索等)CSS样式
- angularJS——自定义指令
- mysql及php命名规范
- HDU 4825:Xor Sum(Trie)
- 从 IT 中断中学到的最佳监控实践
- uva1620 Lazy Susan
- load_library(linker.cpp:759): library "libmaliinstr.so" not found
- excel读入数据库
- 分布式架构设计(一) --- 面向服务的体系架构 SOA
- [Swift]LeetCode526. 优美的排列 | Beautiful Arrangement
- Workspace in use or cannot be created, choose a different one.错误的解决办法
- 【Unity3d游戏开发】Unity中的Time.timeScale
- 高精度(x ,/, +, -, %)良心模板
- babel-polyfill
- Serial-mcu
- 【代码审计】iCMS_v7.0.7 search.admincp.php页面存在SQL注入漏洞
- .apk等常用文件下载出现如果应下载文件,请添加 iis MIME 映射。
- jquery tab选项卡、轮播图、无缝滚动
热门文章
- ab使用详解—如何使用apache性能测试工具进行压力测试
- 修改centos7容器的时间和宿主机时间一致
- 将jsp页面转化为图片或pdf升级版(一)(qq:1324981084)
- EF--封装三层架构IOC
- update mysql row (You can't specify target table 'x' for update in FROM clause)
- App自动化测试环境搭建
- Qt编写的项目作品3-输入法V2018
- hive中parquet存储格式数据类型timestamp的问题
- 全面了解Python中的特殊语法:filter、map、reduce、lambda。
- 通过phpstorm管理svn的gui界面报错问题