GIL全局解释器
'
GIL是一个互斥锁:保证数据的安全(以牺牲效率来换取数据的安全)
阻止同一个进程内多个线程同时执行(不能并行但是能够实现并发)
并发:看起来像同时进行的
GIL全局解释器存在的原因是因为CPython解释器的内存管理不是线程安全的
垃圾回收机制
1 引用计数
2 标记清楚
3 分代回收
同一个进程下的多个线程不能实现并行 但是能够实现并发 多个进程下的线程能够实现并行
'
在一个python的进程内,不仅只有主线程或者还有该主线程开启的其他线程,海有解释器开启的垃圾回收等解释器级别的线程,总之所有的线程都运行在这一个进程内。
1 所有数据都是共享的,这其中,代码作为一种数据也是被所有线程共享的(test.py的所有代码以及CPython解释器的所有
代码) 例如:test.py定义一个函数work,在进程内所有线程都能访问到work的代码,于是我们可以开启三个线程然后target都指
向该代码,能访问到意味着就是可以执行。 2 所有线程的任务,都需要将任务的代码当做参数传给解释器的代码去执行,即所有的线程想要运行自己的任务,首先需要解
决的是能够访问到解释器的代码。
综上:
如果多个线程的target=work,那么执行流程是多个线程先访问到解释器的代码,即拿到执行权限,然后将target的代码交给解释器的代码去执行解释器的代码是所有线程共享的,所以垃圾回收线程也可能放到解释器的代码而执行,这就导致了一个问题:对于同一个数据100 ,可能是线程1执行x=100的同时,而垃圾回收执行的是回收100的操作,解决这种问题就是解锁,保证python解释器同一时间只能执行一个任务的代码。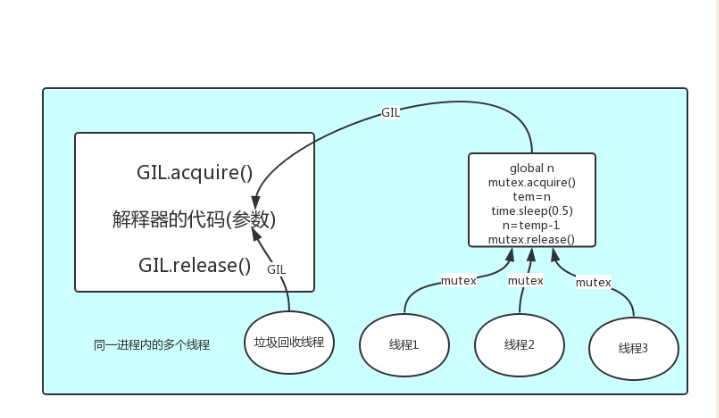
GIL全局解释锁是所有解释型语言的通病!
GIL全局解释锁是python的问题吗?
它是CPython解释器的特点
GIL与多线程
有了GIL的存在,同一时刻同一进程中只有一个线程被执行
进程可以利用多核,但是开销大,而python的多线程开销小,但却无法利用多核优势?
要解决这个问题,先统一一个条件:
1 cpu到底是用来做计算的,还是用来最I/O的? 2 多cpu,意味着可以由多个核并行完成计算,所以多核提升的计算机性能 3 每一个cpu一旦遇到I/O阻塞,任然需要等待,所以多核对I/O操作没什么用处
一个工人相当于cpu,此时计算相当于工人在干活,I/O阻塞相当于为工人干活提供所需原材料的过程,工人干活的过程中如果没有原料了,则工人干活的过程需要停止,直到等待原材料的带来。
如果你的工厂干的大多数任务都需要准备原材料的过程(I/O密集型),那么你有再多的工人,意义也不打,还不如一个人,在等材料的过程中让工人去干别的活,
反过来讲,如果你的工厂原材料都齐全,那当然是工人越多,效率越高
结论:
对计算来说,cpu越多越好,但是对于I/O来说,在多的cpu也没用
当然对于运行一个程序来说,随着cpu的增多执行效率肯定会有所提高(不管提高幅度多大,总会有所提高),这是因为一个程序基本上不会是纯计算或者纯I/O,所以我们只能相对的去看一个程序到底计算密集型还是I/O密集型,从而进一步分析python的多线程到底有无用处。
我们有四个人物需要处理,处理方式肯定是要玩出并发的效果,解决方案可以是:
方案一:开启四个进程
方案二:一个进程下,开启四个线程 单核情况下,分析结果:
如果四个任务是计算密集型,没有多核来并行计算,方案一徒增了创建进程的开销,方案二胜
如果四个任务是I/O密集型,方案一创建进程的开销大,且进程的切换速度远不如线程,方案二胜 多核情况下,分析结果:
如果四个任务是计算密集型,多核意味着并行计算,在python中一个进程中同一时刻只有一个线程执行用不上多核,方案一胜
如果四个任务是I/O密集型,再多的和也解决不了I/O问题,方案二胜 结论:现在的计算机基本上都是多核,python对于计算密集型的任务开多线程的效率并不能带来多大性能上的提升,甚至不如串行(没有大量切换),但是,对于I/O密集型的任务效率还是有显著提升的。
问题:python多线程是不是就没用了?
四个任务:计算密集型的任务,每个任务耗时10s
单核情况下:
多线程好一点,消耗的资源少一点
多核情况下:
开四个进程:10s多一点
开多线程:40s多一点
四个任务:IO密集的任务 每个任务IO 10s
单核情况下:
多线程好一点
多核情况下:
多线程好一点
多线程和多进程都有自己的优点,要根据项目需求合理现在
引用: 多线程用于IO密集型,如socket,爬虫,web
多进程用于计算机密集型,如金融分析
多线程性能测试
#计算密集型:
from multiprocessing import Process
from threading import Thread import os,time
def work():
res=0
for i in range(10000000):
res*=i if __name__ == '__main__':
l=[]
print(os.cpu_count()) #本机为4核
start=time.time()
for i in range(4):
p = Process(target=work) #进程耗时:1.7300989627838135
# p = Thread(target=work) #线程耗时:2.648151397705078
l.append(p)
p.start() for p in l:
p.join()
stop =time.time()
print('run time is %s'%(stop-start))
计算密集型:多进程效率高
#IO密集型:
from multiprocessing import Process
from threading import Thread
import os,time def work():
time.sleep(2) if __name__ == '__main__':
l=[]
print(os.cpu_count()) #本机为4核
start=time.time()
for i in range(200):
p=Process(target=work) #进程耗时:9.763558387756348
# p=Thread(target=work) #线程耗时:2.020115852355957
l.append(p)
p.start() for p in l:
p.join()
stop=time.time()
print('run time is %s'%(stop-start))
I/O密集型:多线程效率高
最新文章
- SMP、NUMA、MPP(Teradata)体系结构介绍
- 注解的方式搭建springmvc步骤
- 个人对于Virtual DOM的一些理解
- MarkupExtension
- matplotlib库的常用知识
- struts2的action访问servlet API的三种方法
- Asp.net MVC + EF6.0 经常出现的问题
- 用Meta 取消流量器缓存实现每次访问都刷新页面方便调试
- Jenkins学习——Jenkins是什么
- python 小程序—循环和列表训练
- codeforces 1077F2. Pictures with Kittens (hard version)单调队列+dp
- PHP基础之$_SERVER的详细参数与说明
- python设计模式---创建型之单例模式
- May 26. 2018 Week 21st Saturday
- JS基本类型-引用类型-深浅拷贝
- ActiveSync之HTTP
- 译: 2. Apache Axis2安装指南
- (1)线程的同步机制 (2)网络编程的常识 (3)基于tcp协议的编程模型
- 对web标准的理解,以及对w3c组织的认识
- Tomcat 错误代号集
热门文章
- Codeforces 915 F. Imbalance Value of a Tree(并查集)
- RHSA-2018:0014-重要: linux-firmware 安全更新
- js 继承的一个例子
- bypass disable_function总结学习
- python+selenium 切换至iframe
- window 定时任务小项目,每秒钟,每分钟访问url
- 【SQL】 java.sql.SQLException: You can't specify target table 'emp' for update in FROM clause
- Mac下持续集成-Mac下Tomcat+Jenkins集成环境搭建
- Mac系统下,docker安装nextcloud,打造个人本地网盘
- 【Makefile】Makefile中的常用函数简介