bert系列二:《BERT》论文解读
论文《BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding》
以下陆续介绍bert及其变体(介绍的为粗体)
bert自从横空出世以来,引起广泛关注,相关研究及bert变体/扩展喷涌而出,如ELECTRA、DistilBERT、SpanBERT、RoBERTa、MASS、UniLM、ERNIE等。
由此,bert的成就不仅是打破了多项记录,更是开创了一副可期的前景。
1, Bert
在看bert论文前,建议先了解《Attention is all you need》论文。
创新点:
- 通过MLM,使用双向Transformer模型,获得更丰富的上下文信息
- 输入方式,句子级输入,可以是一个句子或2个句子,只要给定分隔标记即可
Transformer,多头注意力等概念见bert系列一
预训练语言表示应用到下游任务的2种方式
- feature-based:提取某层或多层特征用于下游任务。代表:ELMo
- fine-tuning:下游任务直接在预训练模型上添加若干层,微调即可。代表:OpenAI GPT,bert
MLM(masked language model):
文中操作为,对15%的token进行mask标记,被标记的token有80%的情况下以[MASK]代替,10%以随机token代替,10%不改变原始token。
为什么要mask操作?因为,要使用双向模型,就面临一个“看见自己”的问题,如bert系列一所述。那么我们将一个token mask掉(是什么蒙蔽了我的双眼?是mask),它就看不见自己啦!
为什么不对选中的token全部mask?因为,预训练中这么做没问题,而在下游任务微调时,[MASK] token是不会出现的,由此产生mismatch问题。
预训练与微调图示
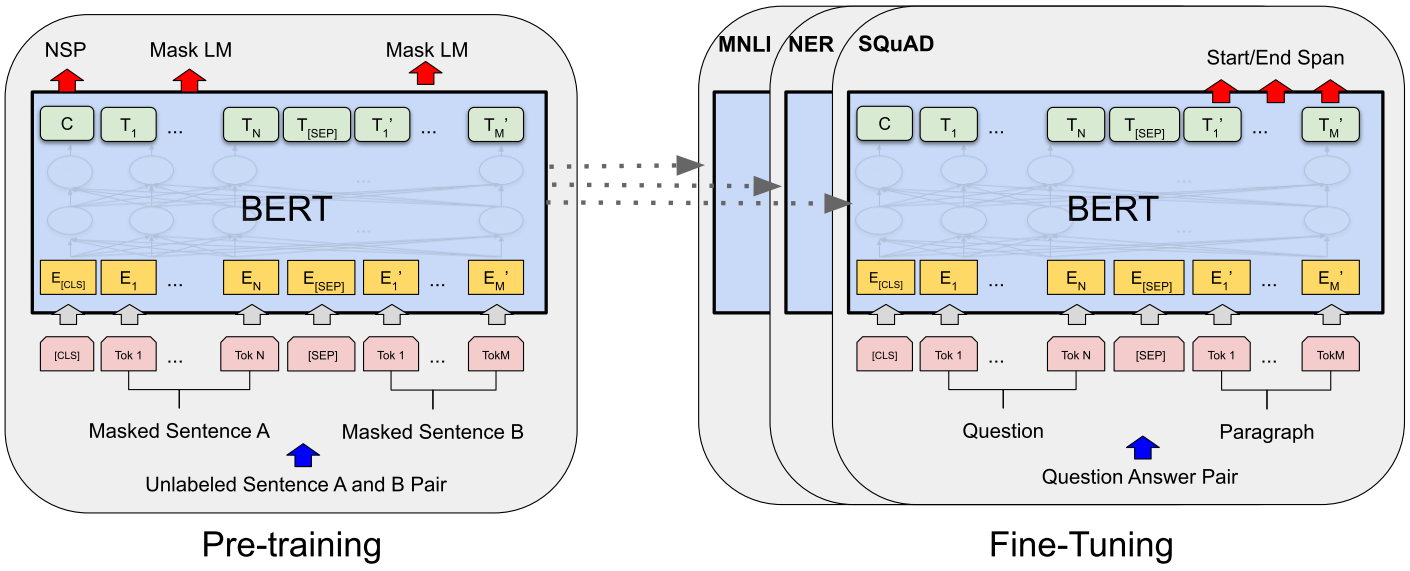
如图,输入可以是一个句子,或2个句子,最后都转换成最大长度521的序列,序列的开头是一个[CLS]标记,用于分类或预测下一句等任务。句子之间也有一个[SEP]标记,用于分隔句子。
对于微调,如图示问答任务,用S表示答案开头,E表示答案末尾。第i个单词(Ti)作为答案开头的概率为:
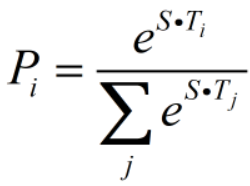
即单词隐层表示Ti与开头S点乘后的softmax值。
候选范围i~j的得分为STi+ETj,取其中得分最大(i,j)的作为答案的预测范围。
输入Embedding使用3个嵌入相加,token嵌入层就是我们通常用的嵌入方式,segment用于区分一个token属于句子A还是B,Position用于位置编码(自注意需要)
如下图:

2, ELECTRA
再介绍一个参数少,训练快,性能好的ELECTRA。来自论文《ELECTRA: PRE-TRAINING TEXT ENCODERS AS DISCRIMINATORS RATHER THAN GENERATORS》
创新点:
不使用mask操作,而是从一个较小的生成器(文中建议大小为判别器的1/4到1/2)中采样来替换一些tokens,然后使用一个判别器去判断这个token是真实的还是生成器产生的。这样模型可以使用全部的tokens而非bert中15%mask的token去训练。
这有点像GAN(生成对抗网络)的概念,不同的是,这里的生成器并不以fool判别器为目标,而是基于极大似然原则训练(其实GAN也可以通过极大似然,只不过生成器反向传播更新需要通过鉴别器)。
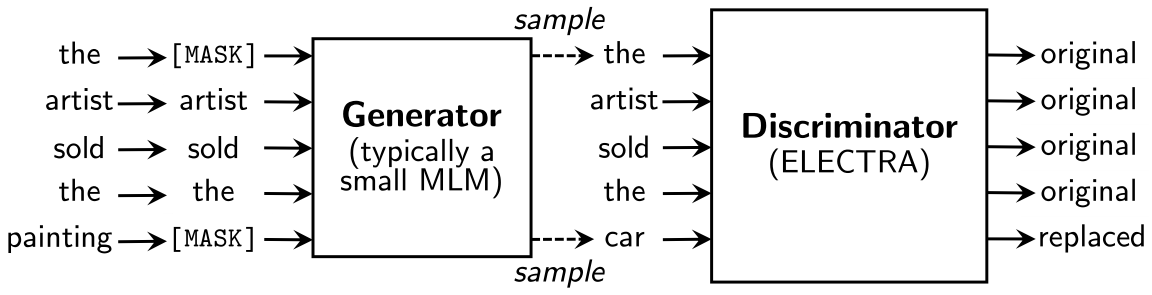
如图,先标记若干位置为mask点,然后使用生成器采样的数据覆盖mask位置,再使用判别器判断每个token是原生的还是伪造的。
生成器及判别器的损失函数为:
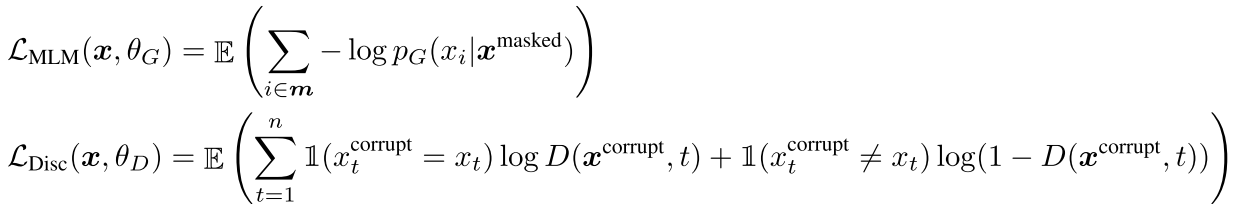
生成器负责对选定的m个点使用极大似然训练,而判别器将要对所有的token进行真伪判断。
最终loss为加权和:
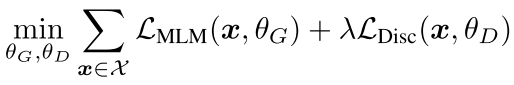
参数共享:
文中仅使用Embedding参数在生成器和判别器中共享(token和positional Embedding,这样做更高效)
3,DistilBERT
论文为《DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter》介绍部分我认为机器之心的这篇文章不错
机器之心:小版BERT也能出奇迹:最火的预训练语言库探索小巧之路
这里只总结一下
创新点
蒸馏模型之前也有。主要是使用了软目标交叉熵损失,以及学生网络初始化的方式。
成就
模型大小减到60%,保留97%语言理解能力,推理速度快60%
训练方式
训练方式为蒸馏(即使用学生网络模拟教师网络,这里bert-base作为教师网络)。
损失由3部分组成,一部分是学生网络与教师网络的软目标交叉熵,一部分为学生网络与教师网络隐状态矢量的嵌入余弦损失,一部分为掩饰语言模型(mlm)损失。其中前2个损失较为重要。
模型移除了token Embedding层和pooler(用于下一句预测),layer数量减到一半。学生网络的初始化也很重要,因为layer只有一半,所以初始化也是从2个layer中取1个。使用非常大的batch_size=4000等。
最新文章
- HQL查询——聚集函数
- 【SharePoint学习笔记】第3章 SharePoint列表新特性以及数据访问
- github邮箱验证技巧
- LeetCode:Longest Palindromic Substring 最长回文子串
- OpenSSH后门获取root密码及防范
- JavaScript 将多个引用(样式或者脚本)放入一个文件进行引用
- storm 入门
- C++ C++ 控制台程序 设置图标
- MD5 32位、16位加密
- 微信公众平台PHP开发
- Python:黑板课爬虫闯关第四关
- 洛谷 P2590 [ZJOI2008]树的统计
- Android下实现数据绑定功能
- TableExistsException: hbase:namespace
- EgretPaper学习笔记一 (安装环境,新建项目)
- spring boot 发邮件
- Maya中输出nuke脚本的方法
- select & input的disabled属性及其向后台传值问题
- day6面向对象--继承、多态
- MySQL技术内幕:SQL编程 第2章 数据类型 读书笔记