python 爬虫实例(二)
2024-08-26 20:31:02
环境:
OS:Window10
python:3.7
描述
打开下面的网址,之后抓取其中的图片
https://music.163.com/#/artist/album?id=101988&limit=120&offset=0
安装一些库文件
首先看你的网页版本,查看方法,打开【https://sites.google.com/a/chromium.org/chromedriver/downloads】之后显示如下图1,说明你的版本是2.45,
下载对应的版本的驱动下载地址【https://chromedriver.storage.googleapis.com/index.html】如下图2

(图1)

(图2)
上面的包文件下载到本地之后,把bin里面的EXE文件放到你本地安装的Python的【Scripts】文件夹路径下
自己的本地路径【C:\Users\XXXXXXX\AppData\Local\Programs\Python\Python37\Scripts】 整体代码如下
import time import requests
import os from bs4 import BeautifulSoup
from selenium import webdriver class GetMuisc: def __init__(self):
self.init_url = 'http://music.163.com/#/artist/album?id=101988&limit=120&offset=0'
self.folder_path = r"C:\pythonProject\wangyi" def request(self, url):
r = requests.get(url)
return r def mkdir(self, path):
path = path.strip()
isExists = os.path.exists(path) if not isExists:
print('创建名字叫做', path, '的文件夹')
os.makedirs(path)
print('创建成功!')
return True
else:
print(path, '文件夹已经存在了,不再创建')
return False def save_img(self, url, file_name):
print("开始请求图片地址...")
img = self.request(url)
print('开始保存图片')
with(open(file_name, "ab")) as ff:
ff.write(img.content)
print(file_name, '图片保存成功!') # f = open(file_name, "ab")
# f.write(img.content)
# f.close() def get_files(self, path):
pic_name = os.listdir(path)
return pic_name def spider(self):
print("Start!")
driver = webdriver.Chrome()
driver.get(self.init_url)
driver.switch_to.frame("g_iframe")
iframe_html = driver.page_source
driver.close() self.mkdir(self.folder_path)
file_name = self.get_files(self.folder_path)
os.chdir(self.folder_path) idstr = 'm-song-module'
moduleHtml = BeautifulSoup(iframe_html, 'lxml').find(id=idstr)
if moduleHtml is None:
print("标签{}没有找到,请检查是否有问题。".format(idstr))
else:
all_li = moduleHtml.find_all('li')
for li in all_li:
album_img = li.find("img")["src"]
album_name = li.find("p", class_="dec")["title"]
album_date = li.find("span", class_="s-fc3").get_text()
end_pos = album_img.index("?")
album_img_url = album_img[:end_pos] photo_name = album_date + " - " + album_name.replace("/", "").replace(":", ",") + ".jpg"
print(album_img_url, photo_name) if photo_name in file_name:
print('图片已经存在,不再重新下载')
else:
self.save_img(album_img_url, photo_name) album_cover = GetMuisc()
album_cover.spider()
运行效果

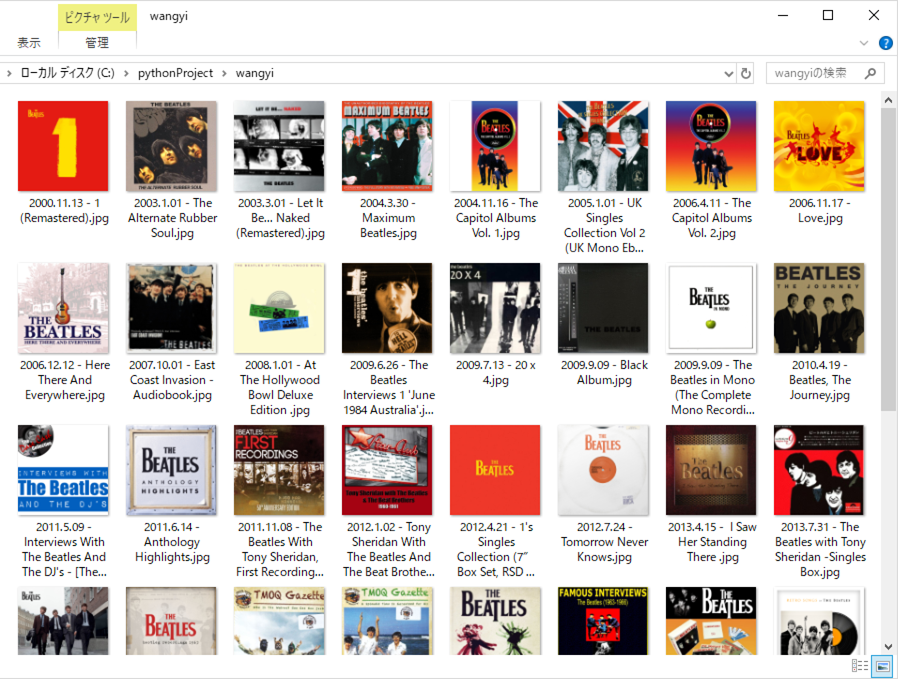
最新文章
- Replace Pioneer 续用2
- GEOS库在windows中的编译和测试(vs2012)
- STM32的PWM输出极性的问题
- 51nod1376 最长递增子序列的数量
- Android设计模式之策略模式
- 机器学习算法与Python实践之(四)支持向量机(SVM)实现
- Python数据结构-元祖
- 使用javascript生成当前博文地址的二维码图片
- c# List实现原理
- GitHub提供服务简介
- HC-05蓝牙模块配对步骤
- C#实现给图片加边框的方法
- 【BZOJ3625】【CF438E】小朋友和二叉树 NTT 生成函数 多项式开根 多项式求逆
- C#利用Guid实现真随机数
- Scala学习笔记——样本类和模式匹配
- iis配置asp.net常见验证失败问题解决方案
- ef linq 访问视图返回结果重复
- 另一个SqlParameterCollection中已包含SqlParameter(转)
- 超简易复制Model对象(为后续备忘录设计模式博文做铺垫)
- Netty堆外内存泄露排查与总结