再说Postgres中的高速缓存(cache)
表的模式信息存放在系统表中,因此要访问表,就需要首先在系统表中取得表的模式信息。对于一个PostgreSQL系统来说,对于系统表和普通表模式的访问是非常频繁的。为了提高这些访问的效率,PostgreSQL设立了高速缓存(Cache)来提高访问效率。
Cache中包括一个系统表元组Cache(SysCache)和一个表模式信息Cache(RelCache)。其中:
- SysCache中存放的是最近使用过的系统表的元组;
- RelCache中包含所有最近访问过的表的模式信息(包含系统表的信息)。RelCache中存放的不是元组,而是RelationData数据结构,每一个RelationData结构表示一个表的模式信息,这些信息都由系统表元组中的信息构造而来。
值得注意的是,两种Cache都不是所有进程共享的。每一个PostgreSQL的进程都维护着自己的SysCache和RelCache。
1.SysCache
SysCache主要用于缓存系统表元组。从实现上看SysCache就是一个数组,数组的长度为预定义的系统表的个数。在PostgreSQL9.5.6中实现了55个系统表,因此SysCache数组具有55个元素,每个元素的数据结构为CatCache,该结构体内使用Hash来存储被缓存的系统表元组,每一个系统表唯一地对应一个SysCache数组中的CatCache结构。每个CatCache都有若干个(不超过4个)査找关键字,这些关键字及其组合可以用来在CatCache中查找系统表元组,在初始化数据集簇时会在这些关键字上为系统表创建索引。
其中涉及到的数据类型的简要意义如下,我们先有个印象,以免后面遇到了感到奇怪和陌生:
/*
* struct catctup: individual tuple in the cache.
* struct catclist: list of tuples matching a partial key.
* struct catcache: information for managing a cache.
* struct catcacheheader: information for managing all the caches.
*/
1.1 SysCache初始化
在Postgres进程初始化时(在InitProgres中),将会对SysCache进行初始化。SysCache的初始化实际上是填充SysCache数组中每个元素的CatCache结构的过程,主要任务是将査找系统表元组的关键字信息写入SysCache数组元素中。这样通过指定的关键字可以快速定位到系统表元组的存储位置。
CatCache的数据结构如下:
typedef struct catcache
{
int id; /* cache identifier --- see syscache.h */
slist_node cc_next; /* list link */
const char *cc_relname; /* name of relation the tuples come from */
Oid cc_reloid; /* OID of relation the tuples come from */
Oid cc_indexoid; /* OID of index matching cache keys */
bool cc_relisshared; /* is relation shared across databases? */
TupleDesc cc_tupdesc; /* tuple descriptor (copied from reldesc) */
int cc_ntup; /* # of tuples currently in this cache */
int cc_nbuckets; /* # of hash buckets in this cache */
int cc_nkeys; /* # of keys (1..CATCACHE_MAXKEYS) */
int cc_key[CATCACHE_MAXKEYS]; /* AttrNumber of each key */
PGFunction cc_hashfunc[CATCACHE_MAXKEYS]; /* hash function for each key */
ScanKeyData cc_skey[CATCACHE_MAXKEYS]; /* precomputed key info for
* heap scans */
bool cc_isname[CATCACHE_MAXKEYS]; /* flag "name" key columns */
dlist_head cc_lists; /* list of CatCList structs */
#ifdef CATCACHE_STATS
long cc_searches; /* total # searches against this cache */
long cc_hits; /* # of matches against existing entry */
long cc_neg_hits; /* # of matches against negative entry */
long cc_newloads; /* # of successful loads of new entry */
/*
* cc_searches - (cc_hits + cc_neg_hits + cc_newloads) is number of failed
* searches, each of which will result in loading a negative entry
*/
long cc_invals; /* # of entries invalidated from cache */
long cc_lsearches; /* total # list-searches */
long cc_lhits; /* # of matches against existing lists */
#endif
dlist_head *cc_bucket; /* hash buckets */
} CatCache;
在SysCache.c文件中已经将所有系统表的CatCache信息存储在一个名为cacheinfo的静态数组
中,每个系统表的CatCache信息用一个数组元素来描述,其数据类型为cachedesc:
struct cachedesc
{
Oid reloid; /* OID of the relation being cached */
Oid indoid; /* OID of index relation for this cache */
int nkeys; /* # of keys needed for cache lookup */
int key[4]; /* attribute numbers of key attrs */
int nbuckets; /* number of hash buckets for this cache */
};
在Postgres进程初始化时,会调用InitCatalogCache函数对SysCache数组进行初始化,并建立由CacheHdr记录的CatCache链表。
InitCatalogCache函数中对SysCache的初始化主要分为以下儿个步骤:
1)根据cacheinfo为SysCache数组分配空间,这里将SysCache的长度设置为和cacheinfo数组相同。
2)循环调用InitCatcache函数根据cacheinfo中的每一个元素生成CatCache结构并放人SysCache数组的对应位置中。InitCatcache每调用一次将处理一个cachedesc结构。该函数根据cachedesc中要求的Hash桶的数量
为即将建立的CatCache结构分配内存,并根据cachedesc结构中的信息填充CatCache的各个字段。
最后将生成的CatCache链接在CacheHdr所指向的链表的头部。
在InitCatalogCache函数中实际只完成了SysCache初始化的第一个阶段,在稍后被调用的函数
RelationCachelnitializePhase2(负责 RelCache 的初始化)还将调用InitCalcachePhase2进行第二阶段也是最后的SysCache初始化工作。InitCatcachePhase2将依次完善SysCache数组中的CatCache结构,
主要是根据对应的系统表填充CatCache结构中的元组描述符(cc_tupdesc)、系统表名(cc_relname)、査找关键字的相关字段(cc_hashfunc、cc_isname、cc_skey)等。
SysCache数组初始化完成之后,CalCache内是没有任何元组的,但是随着系统运行时对于系统表元组的访问,CatCache中的系统表元组会逐渐增多。
1.2 CatCache中缓存元组的组织
CatCache中对缓存元组的组织可以看上图。CatCache中的cc_bucket是一个可变数组。cc_bucket数组中的每一个元素都表示一个Hash桶,元组的键值通过Hash函数可以映射到cc_bucket数组的下标。每一个Hash桶都被组织成一个双向链表(Dlist),其中的节点为Dlist_node类型。
struct dlist_node
{
dlist_node *prev;
dlist_node *next;
};
具有同一个hash值得元组被缓存在同一个hash桶中,每一个hash桶中的缓存元组都被先包装成Dlist_node结构并链接成一个链表。因此在査找某一个元组时,需要先计算其Hash键值并通过键值找到其所在的Hash桶,之后要遍历Hash桶的链表逐一比对缓存元组。为了尽最减少遍历Hash桶的代价,在组织Hash桶中链表时,会将这一次命中的缓存元组移动到链表的头部,这样下一次査找同一个元组时可以在尽可能少的时间内命中。
CatCache中的缓存元组将先被包装成CatCTup形式,然后加人到其所在Hash桶的链表中。在CatCTup中通过my_cache和cache_elem分别指向该缓存元组所在的CatCache及Hash桶链表中的节点。一个被标记为“死亡”的CalCTup(dead字段为真)并不会实际从CatCache中删除,但是在后续的査找中它不会被返回。“死亡"的缓存元组将一直被保留在CatCache中,直到没有人访问它,即其refcount变为0。但如果“死亡”元组同时也属于一个CatCList,则必须等到CatCList和CatCTup的refcount都变为0时才能将其从CatCache中清除。CatCTup的negative字段表明该缓存元组是否为一个“负元组”,所谓负元组就是实际并不存在于系统表中,但是其键值曾经用于在CatCache中进行査找的元组。负元组只有键值,其他属性均为空。负元组的存在是为了避免反复到物理表中去査找不存在的元组所带来的I/O开销。
catctup的数据结构如下:
typedef struct catctup
{
int ct_magic; /* for identifying CatCTup entries */
#define CT_MAGIC 0x57261502
CatCache *my_cache; /* link to owning catcache */
dlist_node cache_elem; /* list member of per-bucket list */
struct catclist *c_list; /* containing CatCList, or NULL if none */
int refcount; /* number of active references */
bool dead; /* dead but not yet removed? */
bool negative; /* negative cache entry? */
uint32 hash_value; /* hash value for this tuple's keys */
HeapTupleData tuple; /* tuple management header */
} CatCTup;
1.3 在CatCache中査找元组
在CatCache中査找元组有两种方式:精确匹配和部分匹配。前者用于给定CatCache所需的所有键值,并返回CatCache中能完全匹配这个键值的元组;而后者只需要给出部分键值,并将部分匹配的元组以一个CatCList的方式返回。
精确匹配査找由函数SearchCatCache函数实现,其函数原型如下:
SearchCatcache (CatCache* Cache .Datum vl, Datum v2 .Datum v3, Datum v4)
其中,vl、v2、v3和v4都用于査找元组的键值,分别对应该Cache中记录的元组搜索键。可以看到,SearehCatcache最多可以使用4个属性的键值进行査询,4个参数分别对应该CatCache数据结构中CC_key字段定义的査找键。
SearchCatCache需要在一个给定的CatCache中査找元组,为了确定要在哪个CatCache中进行査找,还需要先通过CacheHdr遍历SysCache中所有的CatCache结构体,并根据査询的系统表名或系
统表OID找到对应的CatCache。
SearchCatCache在给定的CatCache中査找元组的过程如下:
- 对所査找元组的键值进行Hash,按照Hash值得到该CatCache在cc_bucket数组中对应的
Hash桶的下标。
- 对所査找元组的键值进行Hash,按照Hash值得到该CatCache在cc_bucket数组中对应的
- 遍历Hash桶链找到满足査询需求的Dlist(CatCTup类型的属性cache_elem就是Dlist的节点dlist_node)并遍历,CatCTup中的HeapTupleData就是要査找的元组头部。另外,还要将该dlist_node移到链表头
部并将CatCache的cc_hits(命中计数器)加1。
- 遍历Hash桶链找到满足査询需求的Dlist(CatCTup类型的属性cache_elem就是Dlist的节点dlist_node)并遍历,CatCTup中的HeapTupleData就是要査找的元组头部。另外,还要将该dlist_node移到链表头
- 如果在Hash桶链中无法找到满足条件的元组,则需要进一步对物理系统表进行扫描,以确认要査找的元组是确实不存在还是没有缓存在CatCache中。如果扫描物理系统表能够找到满足条件的元组,则需要将该元组包装成Dlelem之后加人到其对应的Hash桶内链表头部。如果在物理系统表中找不到要査找的元组,则说明该元组确实不存在,此时构建一个只有键值但没有实际元组的“负元组”,并将它包装好加人到Hash桶内链表头部。
从SearchCatCache的査找过程可以看到,由于CatCache只是一个缓存,因此即使在其中找不到某个元组也不能确定该元组是否存在于系统表中,还需要进一步扫描物理系统表来査找该元组。但是,如果在CatCache中为这个不存在的元组放置一个“负元组”则可避免这些额外的开销,因为每次査找同一个不存在的元组时将会得到这个“负元组”,此时即可判定要査找的元组并不存在于系统表中,因而不用进一步去扫描物理系统表确认,从而造成浪费。
要注意SearchCatCache的调用者不能修改返回的元组,并且使用完之后要调用ReleaseCatCache将其释放。
在CatCache中,部分匹配使用另外一个函数SearchCatcacheList,该函数产生一个CatCList结构。
typedef struct catclist
{
int cl_magic; /* for identifying CatCList entries */
#define CL_MAGIC 0x52765103
CatCache *my_cache; /* link to owning catcache */
dlist_node cache_elem; /* list member of per-catcache list */
int refcount; /* number of active references */
bool dead; /* dead but not yet removed? */
bool ordered; /* members listed in index order? */
short nkeys; /* number of lookup keys specified */
uint32 hash_value; /* hash value for lookup keys */
HeapTupleData tuple; /* header for tuple holding keys */
int n_members; /* number of member tuples */
CatCTup *members[FLEXIBLE_ARRAY_MEMBER]; /* members */
} CatCList;
其中以链表的方式存放了在Cache中找到的元组。CatCLUt中的tuple字段记录的是一个“负元组”,它仅仅用来存放该CatCList所用到的键值,没有其他用途。CatCLUt中所包含的元组实际通过members字段表示的变长数据来记录,该数组的实际长度由n_membera字段记录。
SearchCatcacheList函数也会先计算査找键的Hash值,不过该函数首先会在CatCache的cc_lists字段中记录的CatCLlst链表中査找以前是否缓存了该査找键的结果,该査找过程将使用CatCList中tuple字段指向的元组与査找键进行Hash值比较。如果能够找到匹配该Hash值的CatCList,则cc_hits加1并将该CatCList移到ccjists所指向链表的头部,然后返回找到的CatCList。如果在CatCache中找不到CatCList,则扫描物理系统表并构建相应的CatCList并将它加人到ccjists所指向链表的头部。
同样,SearchCatcacheList的调用者不能修改返回的CatCList对象或者里面的元组,并且使用完之后要调用ReleaseCatCacheList将其释放。
最后,我们给一张SysCache相关的内存结构图吧:
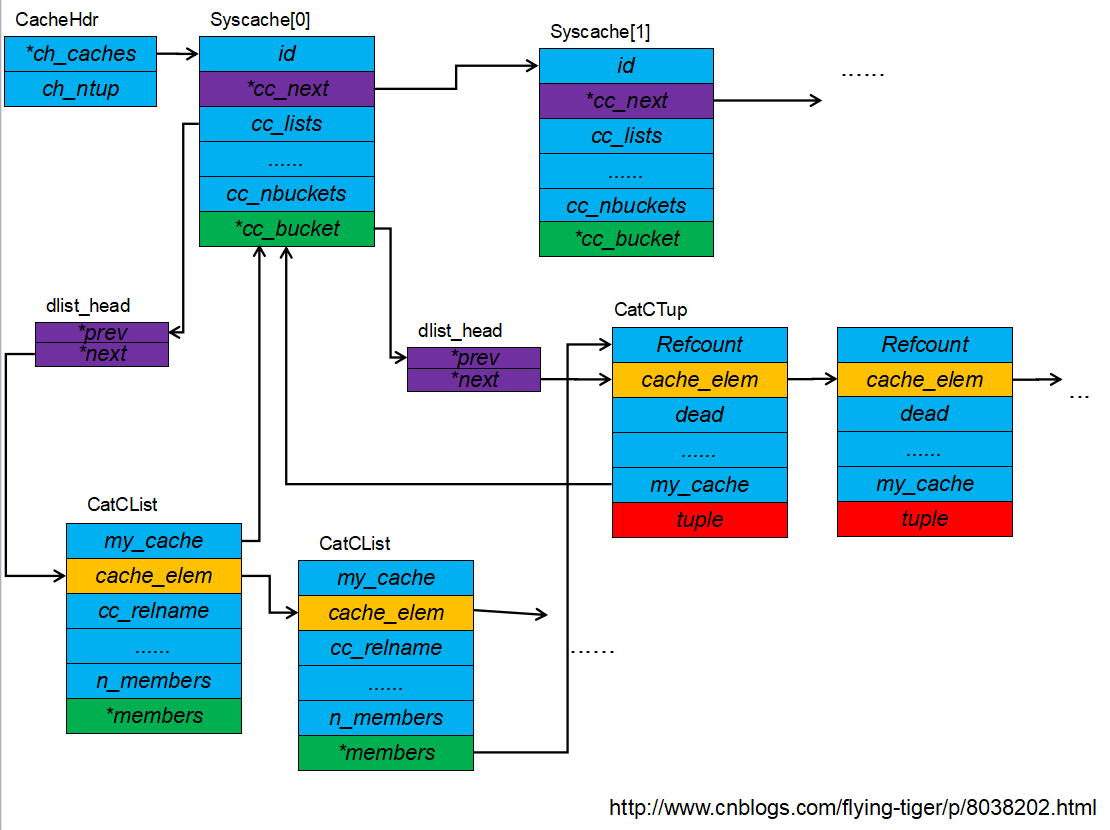
2.RelCache
对RelCache的管理比SysCache要简单许多,原因在于大多数时候RelCache中存储的RelationData 的结构是不变的,因此 PostgreSQL 仅用一个 Hash 表来维持这样一个结构。对 RelCache 的査找、插人、删除、修改等操作也非常简单。当需要打开一个表时,首先在RelCache中寻找该表的RelationData结构,如果没有找到,则创建该结构并加人到RelCache中。
和SysCache的初始化类似,RelCache的初始化同样也在InitPostgres函数中进行,同样分为两个阶段:RelationCachelnitialize 和 ReIationCacheInitializePhase2。
InitPostgres会调用函数RelationCachelnitialize对ReiCache进行第一阶段初始化,该函数将为该进程创建一个Hash表,其Hash键为表的OID,并设置Hash函数为oid_hash。Hash表的创建在函数hash_create中实现,该函数将创建一个标准Hash表结构体HTAB。
在完成了 Hash表的创建后,InitPostgres将调用RelationCachelnitializePhase进人第二阶段的初始化。该函数将必要的系统表和系统表索引的模式信息加人到RelCache中,这个过程通过函数RelationCacheInitializePhase2 来实现。这个阶段会确保 pg_class、pg_attribute、pg_proc、pg_type 四个系统表及相关索引的模式信息被加人到RelCache。在PostgreSQL中,使用一个文件pgJntemaLinit来记录系统表RelationData结构体,若该文件存在且未损坏,则将其内容直接读人RelCache中。否则,分别建立 pg_class、pg__atlribute、pg_proc、pg_type 及其索引的 RelationData 结构,加入到 RelCache上的Hash表中,并重写pg_internal.init文件。
当RelCache初始化完成后,我们就可以使用它来査找表的模式信息。RelCache的主要操作包括:
2.1 插人新打开的表
当打开新的表时,要把它的RelationData加人到RelCache中。该操作通过宏RelationCachelnsert来实现:首先,根据关系表OID在Hash表中找到对应的位置,调用函数hasf^search,指定査询模式为HASH_ENTER,该模式下若发现OID对应的Hash桶已存在,则返回其指针;否则创建一个新的空的hash桶,返回其指针。然后将返回的指针强制转换为RelIdCacheEnt,然后把打开表的RelationData陚值给reldesc字段。
typedef struct relidcacheent
{
Oid reloid;
Relation reldesc;
} RelIdCacheEnt;
2.2 査找Hash表
査找Hash表通过定义宏RelationldCacheLookup (ID,RELATION)来实现,调用函数hash_search,指定査询模式为HASH_FIND,若找到ID对应的RelldCacheEnt,则将其iddesc字段的值賦值给 RELATION;否则,设置RELATION为NULL。
2.3 从Hash表中删除元素
从Hash表中删除元素通过定义宏RelationCacheDelete(RELATION)来实现,调用函数hash_search,指定査询模式为HASH_REVOKE,在该模式下,若找到对应的Hash桶,则将其删除;否则
返回NULL。
Hash表实际上扮演了 RelCache索引的角色,所有对于RelCache的査找都是通过Hash表辅助进行的。
3.后续
其实楼主还想写写Cache信息的同步,因为Cacahe中的信息可能会变化,而Cache都是进程独立的,在一个进程中对某个Cache中的信息进行了修改,当然是应当尽可能快地反映到其他进程中。因此IPC(进程间通信)将是我下一个关注的话题,当然这个比较难,可能要憋一会儿了。
最新文章
- macOS 我的装机
- 关于oracle中日期使用
- TortoiseGit安装详解
- We are 歪果仁带你灰
- openURL的使用方法
- SilkTest高级进阶系列9 – 异步执行命令
- 利用python 与 wmi 获取WINDOWS基本信息
- Rotate Array leetcode
- linux内核 container_ofC语言之应用
- C. Liebig's Barrels
- 4.alembic数据迁移工具
- PHP进程信号处理
- socket 通信 error:88
- java 实现往oracle存储过程中传递array数组类型的参数
- 同步、异步、回调执行顺序之经典闭包setTimeout分析
- ubuntu成功安装搜狗输入法
- Vue指令(四)--v-model
- c++ string写时复制
- JSON初试
- 关于li标签行内显示的问题