【Mysql知识补充】
一、子查询
1.定义
子查询是将一个查询语句嵌套在另一个查询语句中。内层查询语句的查询结果,可以为外层查询语句提供查询条件。子查询中可以包含:IN、NOT IN、ANY、ALL、EXISTS 和 NOT EXISTS等关键字,还可以包含比较运算符:= 、 !=、> 、<等。
2.举例
- 带IN关键字的子查询
#查看技术部员工姓名
select name from employee
where dep_id in
(select id from department where name='技术');
- 带比较运算符的子查询
#比较运算符:=、!=、>、>=、<、<=、<>
#查询大于所有人平均年龄的员工名与年龄 select name,age from emp where age > (select avg(age) from emp);
- 带EXISTS关键字的子查询
EXISTS关字键字表示存在。在使用EXISTS关键字时,内层查询语句不返回查询的记录,而是返回一个真假值:True或False;
当返回True时,外层查询语句将进行查询;当返回值为False时,外层查询语句不进行查询。
#department表中存在dept_id=205,False
mysql> select * from employee
-> where exists
-> (select id from department where id=204);
查询每个部门最新入职的那位员工
company.employee
员工id id int
姓名 emp_name varchar
性别 sex enum
年龄 age int
入职日期 hire_date date
岗位 post varchar
职位描述 post_comment varchar
薪水 salary double
办公室 office int
部门编号 depart_id int #创建表
create table employee(
id int not null unique auto_increment,
name varchar(20) not null,
sex enum('male','female') not null default 'male', #大部分是男的
age int(3) unsigned not null default 28,
hire_date date not null,
post varchar(50),
post_comment varchar(100),
salary double(15,2),
office int, #一个部门一个屋子
depart_id int
); #查看表结构
mysql> desc employee;
+--------------+-----------------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+--------------+-----------------------+------+-----+---------+----------------+
| id | int(11) | NO | PRI | NULL | auto_increment |
| name | varchar(20) | NO | | NULL | |
| sex | enum('male','female') | NO | | male | |
| age | int(3) unsigned | NO | | 28 | |
| hire_date | date | NO | | NULL | |
| post | varchar(50) | YES | | NULL | |
| post_comment | varchar(100) | YES | | NULL | |
| salary | double(15,2) | YES | | NULL | |
| office | int(11) | YES | | NULL | |
| depart_id | int(11) | YES | | NULL | |
+--------------+-----------------------+------+-----+---------+----------------+ #插入记录
#三个部门:教学,销售,运营
insert into employee(name,sex,age,hire_date,post,salary,office,depart_id) values
('egon','male',18,'','老男孩驻沙河办事处外交大使',7300.33,401,1), #以下是教学部
('alex','male',78,'','teacher',1000000.31,401,1),
('wupeiqi','male',81,'','teacher',8300,401,1),
('yuanhao','male',73,'','teacher',3500,401,1),
('liwenzhou','male',28,'','teacher',2100,401,1),
('jingliyang','female',18,'','teacher',9000,401,1),
('jinxin','male',18,'','teacher',30000,401,1),
('成龙','male',48,'','teacher',10000,401,1), ('歪歪','female',48,'','sale',3000.13,402,2),#以下是销售部门
('丫丫','female',38,'','sale',2000.35,402,2),
('丁丁','female',18,'','sale',1000.37,402,2),
('星星','female',18,'','sale',3000.29,402,2),
('格格','female',28,'','sale',4000.33,402,2), ('张野','male',28,'','operation',10000.13,403,3), #以下是运营部门
('程咬金','male',18,'','operation',20000,403,3),
('程咬银','female',18,'','operation',19000,403,3),
('程咬铜','male',18,'','operation',18000,403,3),
('程咬铁','female',18,'','operation',17000,403,3)
;
创建表
alter table employee rename emp;#修改表名 SELECT
*
FROM
emp AS t1
INNER JOIN (
SELECT
post,
max(hire_date) max_date
FROM
emp
GROUP BY
post
) AS t2 ON t1.post = t2.post
WHERE
t1.hire_date = t2.max_date;
联表查询
补充:
SELECT语句关键字的执行顺序
(7) SELECT
(8) DISTINCT <select_list>
(1) FROM <left_table>
(3) <join_type> JOIN <right_table>
(2) ON <join_condition>
(4) WHERE <where_condition>
(5) GROUP BY <group_by_list>
(6) HAVING <having_condition>
(9) ORDER BY <order_by_condition>
(10) LIMIT <limit_number>
二、索引
1.定义
索引在MySQL中也叫做“键”,是存储引擎用于快速找到记录的一种数据结构。
索引相当于字典的音序表,如果要查某个字,如果不使用音序表,则需要从几百页中逐页去查。索引优化应该是对查询性能优化最有效的手段了。索引能够轻易将查询性能提高好几个数量级。
2.原理
索引的目的在于提高查询效率,与我们查阅图书所用的目录是一个道理:先定位到章,然后定位到该章下的一个小节,然后找到页数。相似的例子还有:查字典,查火车车次,飞机航班等。
本质都是:通过不断地缩小想要获取数据的范围来筛选出最终想要的结果,同时把随机的事件变成顺序的事件,也就是说,有了这种索引机制,我们可以总是用同一种查找方式来锁定数据。
3.索引的数据结构
- B+树
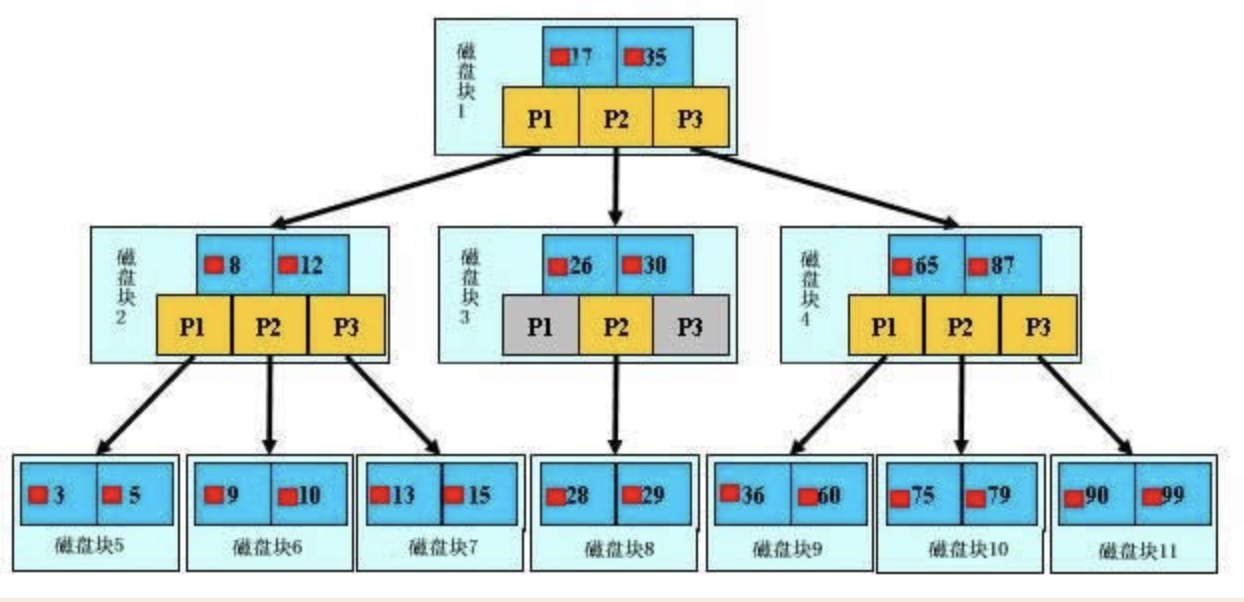
如上图,是一颗b+树,关于b+树的定义可以参见B+树,这里只说一些重点,浅蓝色的块我们称之为一个磁盘块,可以看到每个磁盘块包含几个数据项(深蓝色所示)和指针(黄色所示),如磁盘块1包含数据项17和35,包含指针P1、P2、P3,P1表示小于17的磁盘块,P2表示在17和35之间的磁盘块,P3表示大于35的磁盘块。真实的数据存在于叶子节点即3、5、9、10、13、15、28、29、36、60、75、79、90、99。非叶子节点不存储真实的数据,只存储指引搜索方向的数据项,如17、35并不真实存在于数据表中。
- b+树的查找过程
如图所示,如果要查找数据项29,那么首先会把磁盘块1由磁盘加载到内存,此时发生一次IO,在内存中用二分查找确定29在17和35之间,锁定磁盘块1的P2指针,内存时间因为非常短(相比磁盘的IO)可以忽略不计,通过磁盘块1的P2指针的磁盘地址把磁盘块3由磁盘加载到内存,发生第二次IO,29在26和30之间,锁定磁盘块3的P2指针,通过指针加载磁盘块8到内存,发生第三次IO,同时内存中做二分查找找到29,结束查询,总计三次IO。真实的情况是,3层的b+树可以表示上百万的数据,如果上百万的数据查找只需要三次IO,性能提高将是巨大的,如果没有索引,每个数据项都要发生一次IO,那么总共需要百万次的IO,显然成本非常非常高。
三、视图
1、定义
视图是一个虚拟表(非真实存在),其本质是【根据SQL语句获取动态的数据集,并为其命名】,用户使用时只需使用【名称】即可获取结果集,可以将该结果集当做表来使用。
使用视图我们可以把查询过程中的临时表摘出来,用视图去实现,这样以后再想操作该临时表的数据时就无需重写复杂的sql了,直接去视图中查找即可,但视图有明显地效率问题,并且视图是存放在数据库中的,如果我们程序中使用的sql过分依赖数据库中的视图,即强耦合,那就意味着扩展sql极为不便,因此并不推荐使用
2、创建视图
#语法:CREATE VIEW 视图名称 AS SQL语句
create view teacher_view as select tid from teacher where tname='李平老师'; #于是查询李平老师教授的课程名的sql可以改写为
mysql> select cname from course where teacher_id = (select tid from teacher_view);
+--------+
| cname |
+--------+
| 物理 |
| 美术 |
+--------+
rows in set (0.00 sec) 注意:
#1. 使用视图以后就无需每次都重写子查询的sql,但是这么效率并不高,还不如我们写子查询的效率高 #2. 而且有一个致命的问题:视图是存放到数据库里的,如果我们程序中的sql过分依赖于数据库中存放的视图,那么意味着,一旦sql需要修改且涉及到视图的部分,则必须去数据库中进行修改,而通常在公司中数据库有专门的DBA负责,你要想完成修改,必须付出大量的沟通成本DBA可能才会帮你完成修改,极其地不方便
3、修改视图
语法:ALTER VIEW 视图名称 AS SQL语句
mysql> alter view teacher_view as select * from course where cid>3;
4、删除视图
语法:DROP VIEW 视图名称 DROP VIEW teacher_view
四、触发器
使用触发器可以定制用户对表进行【增、删、改】操作时前后的行为,注意:没有查询
1、创建触发器
# 插入前
CREATE TRIGGER tri_before_insert_tb1 BEFORE INSERT ON tb1 FOR EACH ROW
BEGIN
...
END # 插入后
CREATE TRIGGER tri_after_insert_tb1 AFTER INSERT ON tb1 FOR EACH ROW
BEGIN
...
END # 删除前
CREATE TRIGGER tri_before_delete_tb1 BEFORE DELETE ON tb1 FOR EACH ROW
BEGIN
...
END # 删除后
CREATE TRIGGER tri_after_delete_tb1 AFTER DELETE ON tb1 FOR EACH ROW
BEGIN
...
END # 更新前
CREATE TRIGGER tri_before_update_tb1 BEFORE UPDATE ON tb1 FOR EACH ROW
BEGIN
...
END # 更新后
CREATE TRIGGER tri_after_update_tb1 AFTER UPDATE ON tb1 FOR EACH ROW
BEGIN
...
END
创建触发器
例
NEW表示即将插入的数据行,OLD表示即将删除的数据行。
#准备表
CREATE TABLE cmd (
id INT PRIMARY KEY auto_increment,
USER CHAR (32),
priv CHAR (10),
cmd CHAR (64),
sub_time datetime, #提交时间
success enum ('yes', 'no') #0代表执行失败
); CREATE TABLE errlog (
id INT PRIMARY KEY auto_increment,
err_cmd CHAR (64),
err_time datetime
); #创建触发器
delimiter //
CREATE TRIGGER tri_after_insert_cmd AFTER INSERT ON cmd FOR EACH ROW
BEGIN
IF NEW.success = 'no' THEN #等值判断只有一个等号
INSERT INTO errlog(err_cmd, err_time) VALUES(NEW.cmd, NEW.sub_time) ; #必须加分号
END IF ; #必须加分号
END//
delimiter ; #往表cmd中插入记录,触发触发器,根据IF的条件决定是否插入错误日志
INSERT INTO cmd (
USER,
priv,
cmd,
sub_time,
success
)
VALUES
('egon','','ls -l /etc',NOW(),'yes'),
('egon','','cat /etc/passwd',NOW(),'no'),
('egon','','useradd xxx',NOW(),'no'),
('egon','','ps aux',NOW(),'yes'); #查询错误日志,发现有两条
mysql> select * from errlog;
+----+-----------------+---------------------+
| id | err_cmd | err_time |
+----+-----------------+---------------------+
| 1 | cat /etc/passwd | 2017-09-14 22:18:48 |
| 2 | useradd xxx | 2017-09-14 22:18:48 |
+----+-----------------+---------------------+
rows in set (0.00 sec)
2、删除触发器
drop trigger tri_after_insert_cmd;
五、事务
事务用于将某些操作的多个SQL作为原子性操作,一旦有某一个出现错误,即可回滚到原来的状态,从而保证数据库数据完整性。
START TRANSACTION或BEGIN语句可以开始一项新的事务。
COMMIT可以提交当前事务,是变更成为永久变更。
ROLLBACK可以 回滚当前事务,取消其变更。
SET AUTOCOMMIT语句可以禁用或启用默认的autocommit模式,用于当前连接。
create table user(
id int primary key auto_increment,
name char(32),
balance int
); insert into user(name,balance)
values
('wsb',1000),
('egon',1000),
('ysb',1000); #原子操作
start transaction;
update user set balance=900 where name='wsb'; #买支付100元
update user set balance=1010 where name='egon'; #中介拿走10元
update user set balance=1090 where name='ysb'; #卖家拿到90元
commit; #出现异常,回滚到初始状态
start transaction;
update user set balance=900 where name='wsb'; #买支付100元
update user set balance=1010 where name='egon'; #中介拿走10元
uppdate user set balance=1090 where name='ysb'; #卖家拿到90元,出现异常没有拿到
rollback;
commit;
mysql> select * from user;
+----+------+---------+
| id | name | balance |
+----+------+---------+
| 1 | wsb | 1000 |
| 2 | egon | 1000 |
| 3 | ysb | 1000 |
+----+------+---------+
rows in set (0.00 sec)
六、存储过程
存储过程包含了一系列可执行的sql语句,存储过程存放于MySQL中,通过调用它的名字可以执行其内部的一堆sql
使用存储过程的优点:
#1. 用于替代程序写的SQL语句,实现程序与sql解耦 #2. 基于网络传输,传别名的数据量小,而直接传sql数据量大
使用存储过程的缺点:
#1. 程序员扩展功能不方便
- 创建存储过程
delimiter //
create procedure p1()
BEGIN
select * from blog;
INSERT into blog(name,sub_time) values("xxx",now());
END //
delimiter ; #在mysql中调用
call p1() #在python中基于pymysql调用
cursor.callproc('p1')
print(cursor.fetchall())
七、自定义函数
函数中不要写sql语句(否则会报错),函数仅仅只是一个功能,是一个在sql中被应用的功能。若要想在begin...end...中写sql,请用存储过程
- 创建函数
delimiter //
create function f1(
i1 int,
i2 int)
returns int
BEGIN
declare num int;
set num = i1 + i2;
return(num);
END //
delimiter ;
- 执行函数
# 获取返回值
select UPPER('egon') into @res;
SELECT @res; # 在查询中使用
select f1(11,nid) ,name from tb2;
八、流程控制
1、条件语句
delimiter //
CREATE PROCEDURE proc_if ()
BEGIN declare i int default 0;
if i = 1 THEN
SELECT 1;
ELSEIF i = 2 THEN
SELECT 2;
ELSE
SELECT 7;
END IF; END //
delimiter ;
2、循环语句
delimiter //
CREATE PROCEDURE proc_while ()
BEGIN DECLARE num INT ;
SET num = 0 ;
WHILE num < 10 DO
SELECT
num ;
SET num = num + 1 ;
END WHILE ; END //
delimiter ;
最新文章
- nginx配合zabbix编译安装时web下一步跳转问题
- My安卓知识2--使用listview绑定sqlite中的数据
- Azure Redis Cache (3) 在Windows 环境下使用Redis Benchmark
- dom4j-full.jar 解析 XML
- C++模板实例掌握
- Django 1.6 最佳实践: django项目的服务器自动化部署(转)
- POJ1948Triangular Pastures(DP)
- Mac上使用Visual Studio Code开发/调试.NET Core代码
- 使用Slua框架开发Unity项目的重要步骤
- python——常用模块2
- windows server 2012 安装 VC14(VC2015) 安装失败解决方案
- 06 python初学 (列表内置方法)
- Git的配置与使用
- js对象遍历输出顺序错乱的问题
- R8500 MPv2 版本 刷梅林改版固件
- Python *Mix_w4
- 嵌入式系统C编程之堆栈回溯
- idea如何整理代码格式
- uniGUI试用笔记(六)
- MVC框架的理解(配置文件一次编写,所有的java代码都可以运行)