Page Object设计模式(一)
一、简介
主要特点体现在“对界面交互细节的封装”上,使测试用例更专注于业务的操作,从而提高测试用例的可维护性。解决UI变动问题。
page对象的一个基本原则经验法则是:凡是人能做的事,page对象通过软件客户端都能做到。因此,它应该提供一个易于编程的接口,并隐藏窗口中底层的部件。当访问一个文本框时,应该通过一个访问方法(Access Method)实现字符串的获取与返回,复选框应当使用布尔值,按钮应当被表示为行为导向的方法名。page对象应当把在GUI控件上所有查询和操作数据的行为封装为方法。即使改变具体的元素,page对象的接口也不应当发生变化。通过给页面建模,使其对应用程序的使用者变得有意义。
Page Object设计模式应遵循的原则:
- 应该易于使用
- 有清晰的结构,如PageObjects对应页面对象,PageModules对应页面内容
- 只写测试内容,不写基础内容
- 在可能的情况下防止样板代码
- 不需要自己管理浏览器
- 在运行时选择浏览器,而不是类级别
- 不需要直接接触selenium
Page Object的设计思想是:把元素定位与元素操作进行分层,结果是当元素发生变化时,只需要维护page层的元素定位,而不需要关心在哪些测试用例中使用了这些元素。在编写测试用例时,也不需要关心元素是如何定位的。
二、简单实现
1.测试代码
def test_baidu_search_case1(self):
self.driver.get(self.base_url)
self.driver.find_element_by_id("kw").send_keys("selenium")
self.driver.find_element_by_id("su").click() def test_baidu_search_case2(self):
self.driver.get(self.base_url)
self.driver.find_element_by_id("kw").send_keys("unittest")
self.driver.find_element_by_id("su").click() def test_baidu_search_case3(self):
self.driver.get(self.base_url)
self.driver.find_element_by_id("kw").send_keys("page object")
self.driver.find_element_by_id("su").click()
这种每次都要定位元素,再对这些元素操作的重复性行为,会带来这样一个问题:就是一旦元素定位发生改变,每条测试用例都要将定位元素的代码加以修改,若是自动化测试项目中存在上百条测试用例,就会提高自动化测试用例的维护成本。
Page Object的设计思想上是把元素定位与元素操作进行分层,当元素发生变化时,只需要维护page层的元素定位,而不需要关心在哪些测试用例当中使用了这些元素。在编写测试用例时,也不必关心元素是如何定位的。
创建baidu_page.py文件
class BaiduPage():
def __init__(self, driver):
self.driver = driver
def search_input(self, search_key):
self.driver.find_element_by_id("kw").send_keys(search_key)
def search_button(self):
self.driver.find_element_by_id("su").click()
创建BaiduPage类,分别封装输入搜索内容和点击确定搜索按钮的search_input()和search_button()方法,这里的封装只针对一个页面中可能会操作到的元素,原则是一个元素封装成一个方法。当元素的定位方法发生改变时,只需要维护这里的方法即可,而不必关心这个方法被哪个测试用例使用了。
from files.PO.baidu_page import BaiduPage def test_baidu_search_case1(self):
self.driver.get(self.base_url)
bd = BaiduPage(self.driver)
bd.search_input("selenium")
bd.search_button() def test_baidu_search_case2(self):
self.driver.get(self.base_url)
bd = BaiduPage(self.driver)
bd.search_input("unittest")
bd.search_button() def test_baidu_search_case3(self):
self.driver.get(self.base_url)
bd = BaiduPage(self.driver)
bd.search_input("page object")
bd.search_button(
首先在测试中导入BaiduPage类,然后在每个测试用例中为BaiduPage类传入驱动,以便轻松地使用它封装的方法来设计具体的测试用例了。
2.改进Page Object封装
创建base.py文件,内容如下:
class BasePage:
"""
基础Page层,封装一些常用的方法
""" def __init__(self, driver):
self.driver = driver # 打开页面
def open(self, url=None):
if url is None:
self.driver.get(self.url)
else:
self.driver.get(url) # id定位
def by_id(self, id_):
return self.driver.find_element_by_id(id_) # name定位
def by_name(self, name_):
return self.driver.find_element_by_name(name_) # class定位
def by_class(self, class_name):
return self.driver.find_element_by_class(class_name) # Xpath定位
def by_xpath(self, xpath):
return self.driver.find_element_by_xpath(xpath) # CSS定位
def by_css(self, css):
return self.driver.find_element_by_css_selector(css) # 获取title
def get_title(self):
return self.driver.title # 获取页面text,仅使用XPath定位
def get_text(self, xpath):
return self.by_xpath(xpath).text # 执行JavaScript脚本
def js(self, script):
self.driver.execute_script(script)
创建BasePage类作为所有Page类的基类,在BasePage类中封装一些方法
- open()方法用于打开网页,它接收一个url参数,默认为None。如果url参数为None,则默认打开子类中定义的url
- by_id()和by_name()方法。由于Selenium提供的元素定位方法很长,这里做了简化,为的是在子类中使用更加简便
- get_title()和get_text()方法。需要注意的是,get_text()方法需要接收元素定位,这里默认为xpath定位。
修改后的baidu_page.py文件
from files.PO.base import BasePage class BaiduPage(BasePage):
"""百度Page层,百度页面封装操作到的元素"""
url = "http://www.baidu.com" def search_input(self, search_key):
self.by_id("kw").send_keys(search_key) def search_button(self):
self.by_id("su").click()
创建BaiduPage.py类继承BasePage类,定义url变量,供父类中的open()方法使用。在测试用例中,使用BaiduPage类及它所继承的父类中的方法
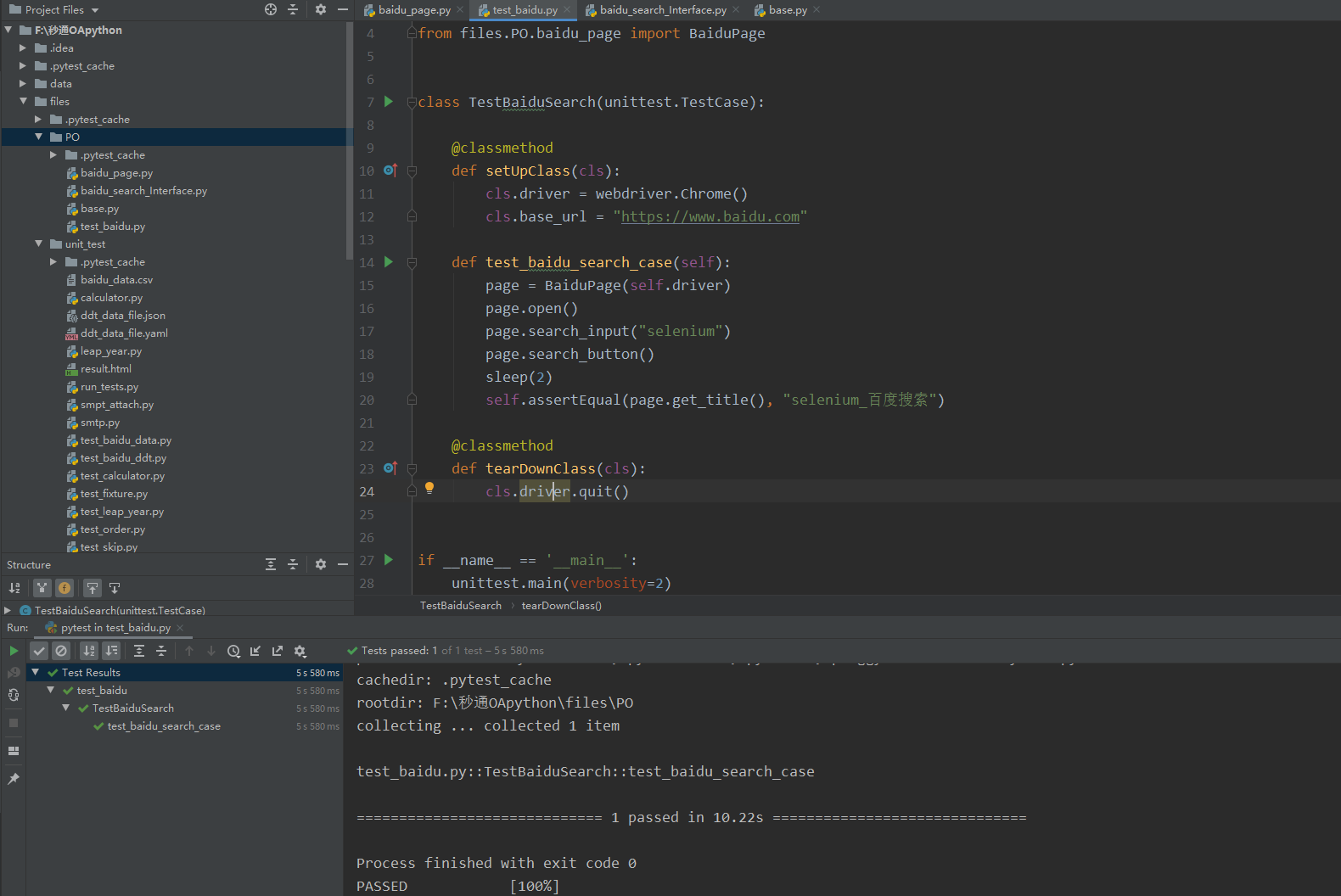
from selenium import webdriver
import unittest
from time import sleep
from files.PO.baidu_page import BaiduPage class TestBaiduSearch(unittest.TestCase): @classmethod
def setUpClass(cls):
cls.driver = webdriver.Chrome()
cls.base_url = "https://www.baidu.com" def test_baidu_search_case(self):
page = BaiduPage(self.driver)
page.open()
page.search_input("selenium")
page.search_button()
sleep(2)
self.assertEqual(page.get_title(), "selenium_百度搜索") @classmethod
def tearDownClass(cls):
cls.driver.quit() if __name__ == '__main__':
unittest.main(verbosity=2)
最新文章
- asp.net分页控件
- java-PreparedStatement的用法
- 玩转 H5 下拉上滑动效果
- [ASE][Daily Scrum]11.30
- C++程序设计之四书五经[转自2004程序员杂志]--下篇
- 屠龙之路_狭路相逢勇者胜_EighthDay
- autotools工具使用记录
- [转载]JSON序列化与反序列化
- OJ——华为编程题目:输入字符串括号是否匹配
- tomcat环境变量配置
- MVC-HtmlHelper简单总结
- Angular开发实践(二):HRM运行机制
- Android开发中StackOverflowError
- vue父路由默认选中第一个子路由,切换子路由让父路由高亮不会消失
- Dubbo常用配置解析
- Mysql DBA 运维 MySQL数据库索引优化及数据丢失案例 MySQL备份-增量备份及数据恢复基础实战 MySQL数据库生产场景核心优化
- GitHub入门与实践 读书笔记一:欢迎来到GitHubde世界
- SQL Server 基础之《学生表-教师表-课程表-选课表》(二)
- MT【140】是否存在常数$\textbf{C}$
- 聊一聊goroutine stack