Lucene 分页搜索实现
2024-09-11 09:29:59
Lucene中有两种分页查询方式
1、一次查询出大量数据,然后根据页码定位是哪个文档,其实就是暴力获取了
2、通过调用searchAfter来实现
我们都知道collect是lucene中对搜索到的文档进行收集和排序过程,searchAfter也是通过一个收集器来控制的,叫PagingTopScoreDocCollector

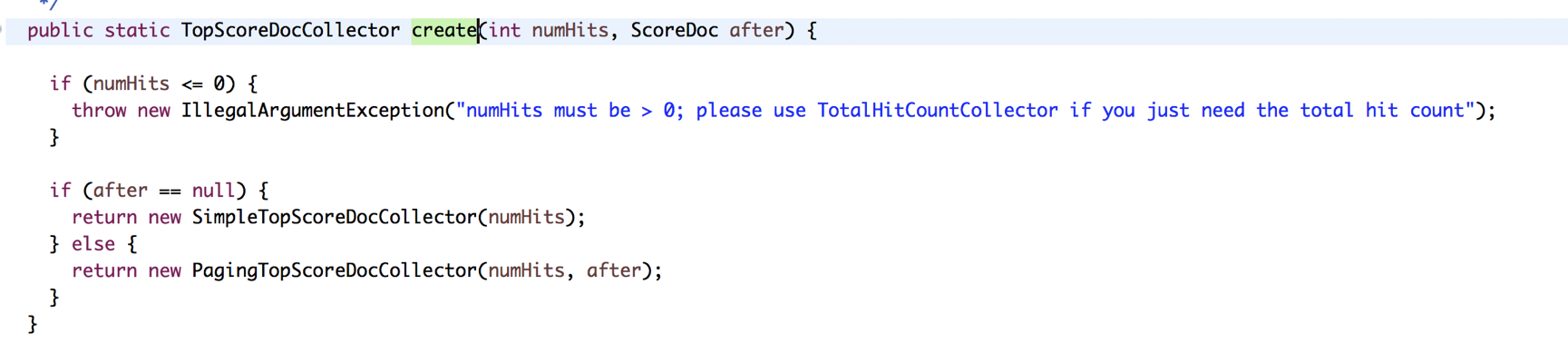
PagingTopScoreDocCollector中最主要的方法是getLeafCollector()判断分页查询的代码为,collect中包含了判断视为当前页的结果还有结果排序,排序方法是pq.updateTop();

updateTop中就执行两部操作,在查询到结果中找到最小的,然后返回heap[1],i默认从1开始所以head【0】为空,所以返回heap[1],每次都会和heap[1]对比把最小的放在前面
这是一个弄了一个二叉堆,具体分析的可以看http://quweiprotoss.blog.163.com/blog/static/408828832011523114133876/这个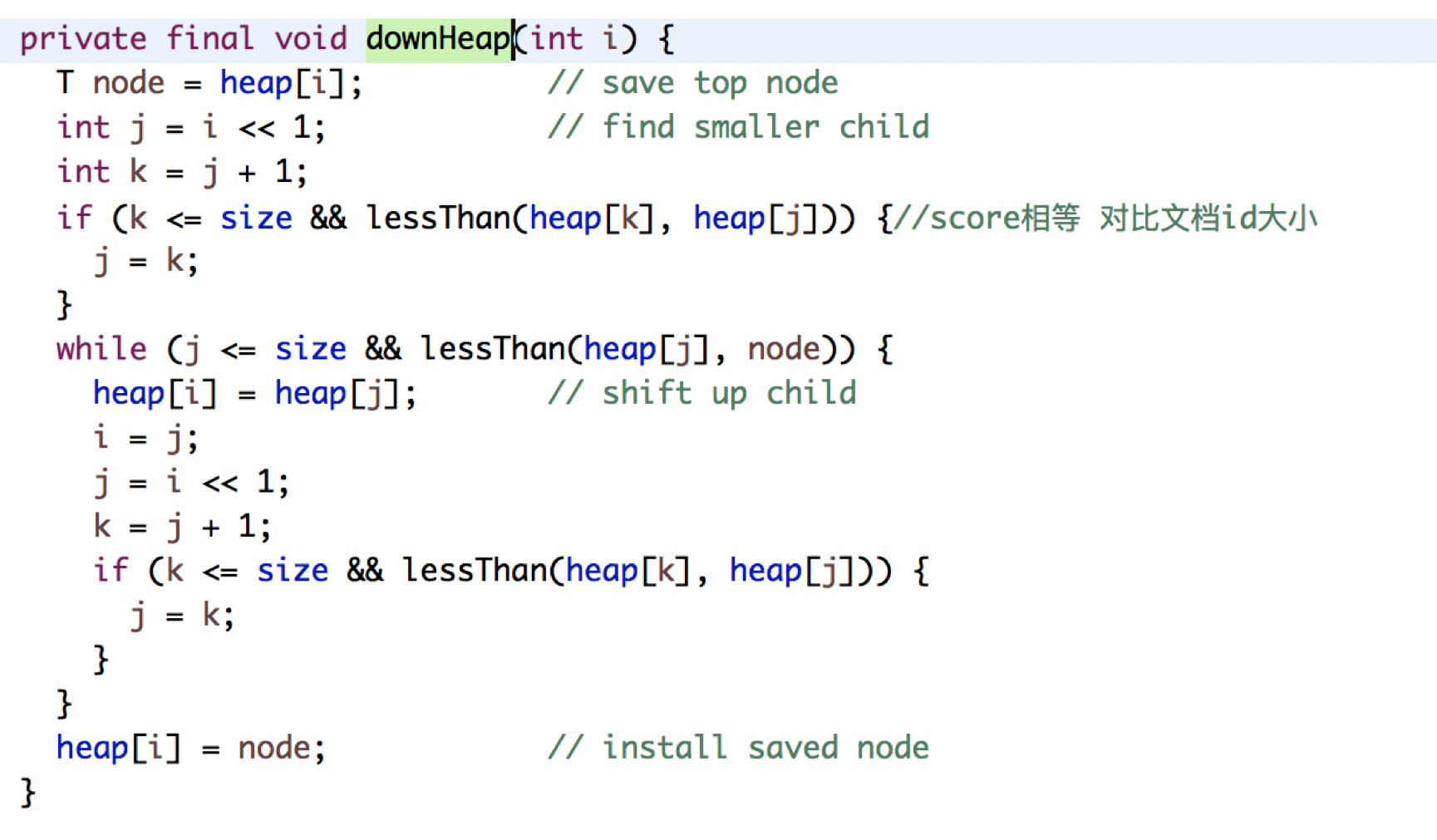
当score分数一样的时候会对比文档大小,最后是按照文档id的大小进行排列的
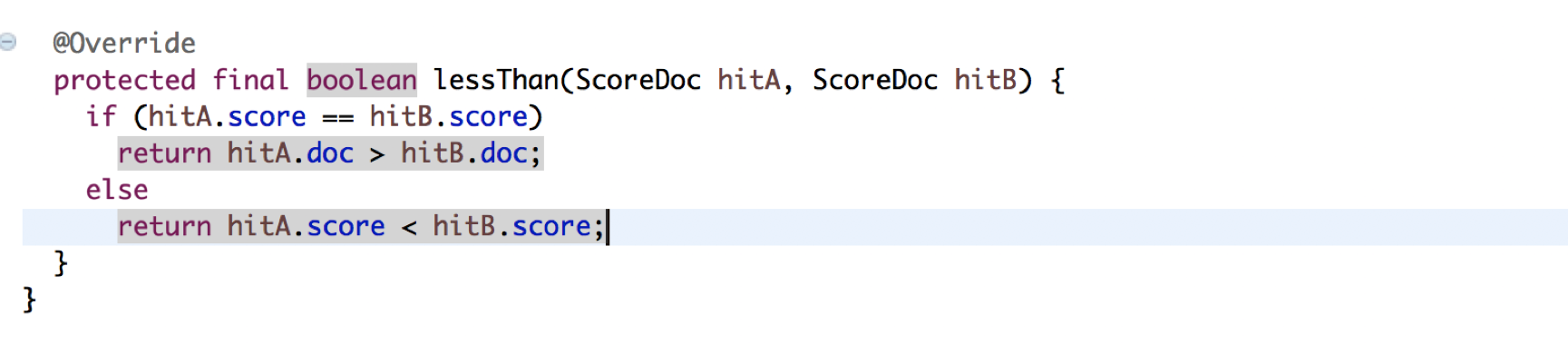
说白了searchAfter也是全部搜索了一遍只不过在collect过程中添加了一个上一页最后doc和当前返回的doc对比,这个过程时间复杂度为o(n),而用普通的查询这个过程会没有从某种程度上来说兴许速度还会由于searchAfter
最新文章
- 记录下帮助一位网友解决的关于android子控件的onTouch或onClick和父OnTouch 冲突的问题。
- 关于Unity的网络框架
- 自定义UICollectinviewFlowLayout,即实现瀑布流
- Buffer Cache
- [css]《CSS知多少》
- 浏览器打开应用指定的界面-b
- 《Python爬虫学习系列教程》学习笔记
- HTML5它contenteditable属性
- 浅析如何在Nancy中生成API文档
- Python丨Python 性能分析大全
- eclipse中的System.getProperty("user.dir")
- SSM-Spring-09:Spring中jdk动态代理
- js 向上和向下取整
- mumu模拟器设置代理/打开网络连接(windows)
- POJ - 1062(昂贵的聘礼)(有限制的spfa最短路)
- swift - 3D 视图,截图,关键字搜索
- 给dede添加栏目图片和栏目描述
- 在NGUI中高效优化UIScrollView之UIWrapContent的简介以及使用
- 5.3.1 RPC端点RpcEndpoint
- Netty4.x中文教程系列(六) 从头开始Bootstrap