老的API实现WordCount
2024-09-01 06:41:34
使用Hadoop版本0.x实现单词统计
package old; import java.io.IOException;
import java.net.URI;
import java.util.Iterator; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.FileInputFormat;
import org.apache.hadoop.mapred.FileOutputFormat;
import org.apache.hadoop.mapred.JobClient;
import org.apache.hadoop.mapred.JobConf;
import org.apache.hadoop.mapred.MapReduceBase;
import org.apache.hadoop.mapred.Mapper;
import org.apache.hadoop.mapred.OutputCollector;
import org.apache.hadoop.mapred.Reducer;
import org.apache.hadoop.mapred.Reporter; /**
* 老API实现单词统计
*
*/
/**
* hadoop版本1.x的包一般是mapreduce
*
* hadoop版本0.x的包一般是mapred
*
*/ public class OldApp { static final String INPUT_PATH = "hdfs://chaoren:9000/hello";
static final String OUT_PATH = "hdfs://chaoren:9000/out"; public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
FileSystem fileSystem = FileSystem.get(new URI(INPUT_PATH), conf);
Path outPath = new Path(OUT_PATH);
if (fileSystem.exists(outPath)) {
fileSystem.delete(outPath, true);
}
/**
* 改动1:不再使用Job,而是使用JobConf
*
* 改动2:类的包名不再使用mapreduce,而是使用mapred
*
* 改动3:不再使用job.waitForCompletion(true)提交作业,而是使用JobClient.runJob(job);
*/
JobConf job = new JobConf(conf, OldApp.class); // 1.1指定读取的文件位于哪里
FileInputFormat.setInputPaths(job, INPUT_PATH);
// 指定如何对输入的文件进行格式化,把输入文件每一行解析成键值对
// job.setInputFormatClass(TextInputFormat.class); // 1.2指定自定义的map类
job.setMapperClass(MyMapper.class);
// map输出的<k,v>类型。如果<k3,v3>的类型与<k2,v2>类型一致,则可以省略
// job.setOutputKeyClass(Text.class);
// job.setOutputValueClass(LongWritable.class); // 1.3分区
// job.setPartitionerClass(org.apache.hadoop.mapreduce.lib.partition.HashPartitioner.class);
// 有一个reduce任务运行
// job.setNumReduceTasks(1); // 1.4排序、分组 // 1.5归约 // 2.2指定自定义reduce类
job.setReducerClass(MyReducer.class);
// 指定reduce的输出类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class); // 2.3指定写出到哪里
FileOutputFormat.setOutputPath(job, outPath);
// 指定输出文件的格式化类
// job.setOutputFormatClass(TextOutputFormat.class); // 把job提交给jobtracker运行
JobClient.runJob(job);
} /**
* 新API:extends Mapper
*
* 老API:extends MapReduceBase implements Mapper
*/
static class MyMapper extends MapReduceBase implements
Mapper<LongWritable, Text, Text, LongWritable> {
public void map(LongWritable k1, Text v1,
OutputCollector<Text, LongWritable> collector, Reporter reporter)
throws IOException {
String[] split = v1.toString().split("\t");
for (String word : split) {
collector.collect(new Text(word), new LongWritable(1));
}
}
} static class MyReducer extends MapReduceBase implements
Reducer<Text, LongWritable, Text, LongWritable> {
public void reduce(Text k2, Iterator<LongWritable> v2s,
OutputCollector<Text, LongWritable> collector, Reporter reporter)
throws IOException {
long times = 0L;
while (v2s.hasNext()) {
long temp = v2s.next().get();
times += temp;
}
collector.collect(k2, new LongWritable(times));
}
} }
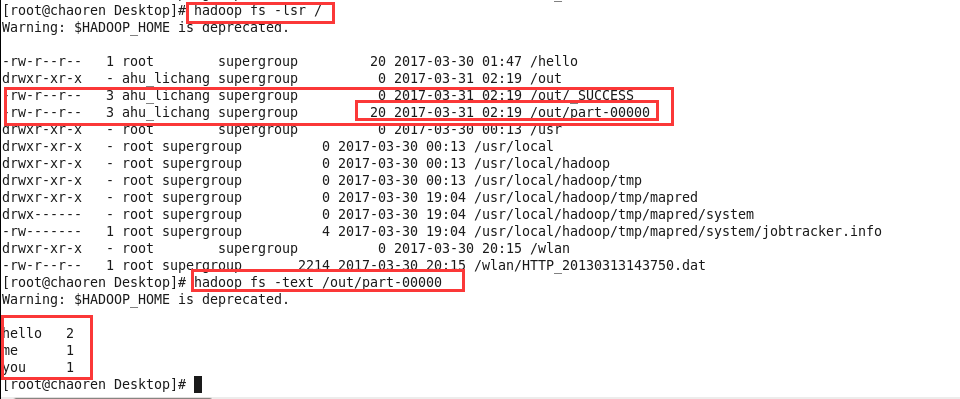
查看结果:
最新文章
- 修改git remote url
- c#后台进行窗体切换的方法
- WebStorm 11激活方法
- UVA 11827 Maximum GCD
- 《DSP using MATLAB》示例Example5.6
- .net委托(转载)
- Asp.Net Web API 2第十七课——Creating an OData Endpoint in ASP.NET Web API 2(OData终结点)
- 安装chocolatey
- Chrome浏览器的密码隐患
- uuid-不好之处
- java对身份证验证及正则表达式解析
- [codility]Grocery-store
- Java 编程的动态性,第 6 部分: 利用 Javassist 进行面向方面的更改--转载
- PHP读取CSV大文件导入数据库的示例
- appium+python做移动端自动化测试
- Mac下配置Nginx负载均衡
- CentOS 6.5 Tomcat安装及配置
- 闲话ACES(修订)
- Linux性能查询常用指令
- break与continue关键字的使用
热门文章
- linux下yum错误:[Errno 14] problem making ssl connection Trying other mirror.
- Mongodb 笔记06 副本集的组成、从应用程序连接副本集、管理
- SQL语句(十七)综合练习_分组查询_内嵌查询_视图使用
- Android端抓取日志
- 20155305乔磊2016-2017-2《Java程序设计》第八周学习总结
- 判断html是否含有图片
- kafka入门(1)- 基本概念
- Rest-Framework组件源码之认证、频率、权限
- Python练习-天已经亮了计算器也终于完成了
- 差分约束系统 + spfa(A - Layout POJ - 3169)