Hadoop(七):自定义输入输出格式
MR输入格式概述
数据输入格式 InputFormat。
用于描述MR作业的数据输入规范。
输入格式在MR框架中的作用:
文件进行分块(split),1个块就是1个Mapper任务。
从输入分块中将数据记录逐一读出,并转换为Map的输入键值对。
如果想自定义输入格式,需要实现:
顶级输入格式类:org.apache.hadoop.mapreduce.InputFormat
顶级块类:org.apache.hadoop.mapreduce.InputSplit
顶级块数据读取类:org.apache.hadoop.mapreduce.RecordReader
Hadoop内置输入格式
Hadoop提供了大量的内置数据输入格式,包括:CombineFileInputFormat、SequenceFileInputFormat、SequenceFileAsTextInputFormat、NlineInputFormat、FileInputFormat、TextInputFormat、KeyValueTextInputFormat等。最常用的是TextInputFormat和KeyValueTextInputFormat这两种。
TextInputFormat是MR框架默认的数据读入格式(一般学习的第一个例子wordcount就是用的这个格式),
可以将文本文件分块逐行读入一遍Map节点处理。
key为当前行在整个文本文件中的字节偏移量,value为当前行的内容。
KeyValueTextInputFormat。
可以将一个按照<key,value>格式逐行保存的文本文件逐行读出,并自动解析为相对于的key和value。默认按照'\t'分割。
也就是说1行的\t前的内容是key,后面是value。
如果没有\t,value就设置为empty。
自定义输入格式从MySQL中取数
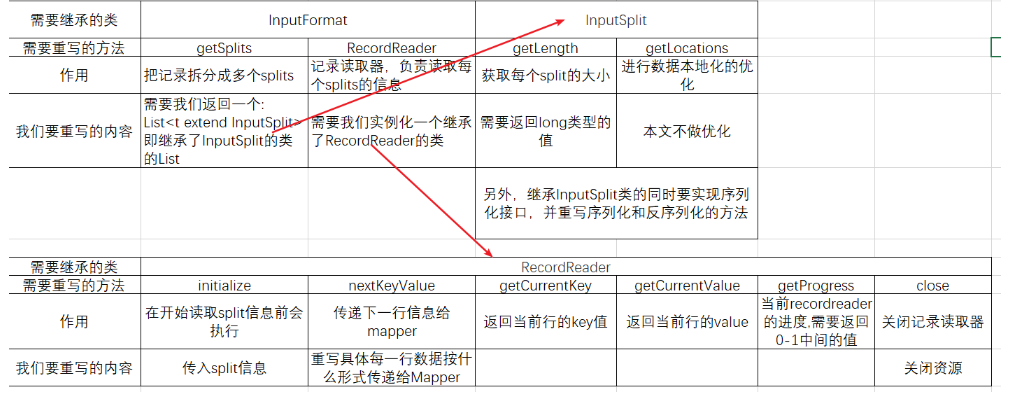
自定义输入格式,我们需要继承InputFormat,InputSplit和RecordReader三个类,并重写以下方法:
基本的作用和我们要重写的内容见下表。
下表内容并不限定于MySQL中取数(就是从文件取数也要实现这些)。
1个split就是一个Map,和Reduce的个数不同,Mapper的任务个数是InputFormat决定的,Reduce任务个数是客户决定的。
自定义输入Value抽象类,因为我们从MySQL中读取的是一行数据,必然要使用一个对象来存储这些数据,我们先定义这个对象的抽象类,这样可以先暂时跳过这个类具体的内容。
package com.rzp.ifdemo;
import org.apache.hadoop.io.Writable;
import java.sql.ResultSet;
import java.sql.SQLException;
/**
* mysql输入的value类型,其实应用中使用到的数据类型必须继承自该类
*/
public abstract class MysqlInputValue implements Writable {
//从数据库返回链接中读取字段信息
public abstract void readFields(ResultSet rs) throws SQLException;
}
自定义输入格式
package com.rzp.ifdemo;
import com.rzp.pojo.UrlCountMapperInputValue;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Writable;
import org.apache.hadoop.mapred.MapTask;
import org.apache.hadoop.mapreduce.*;
import org.apache.hadoop.util.ReflectionUtils;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import java.sql.*;
import java.util.ArrayList;
import java.util.HashSet;
import java.util.List;
/**
*
*/
public class MysqlInputFormat<V extends MysqlInputValue> extends InputFormat<LongWritable,V> {
public static final String MYSQL_INPUT_DRIVER_KEY = "mysql.input.driver"; //数据库链接drive,后续在主方法会重新传参数
public static final String MYSQL_INPUT_URL_KEY = "mysql.input.url"; //数据库链接url,后续在主方法会重新传参数
public static final String MYSQL_INPUT_USERNAME_KEY = "mysql.input.username"; //数据库链接username,后续在主方法会重新传参数
public static final String MYSQL_INPUT_PASSWORD_KEY = "mysql.input.password"; //数据库链接password,后续在主方法会重新传参数
public static final String MYSQL_SELECT_KEY = "mysql.input.select"; //查询总记录数量的sql,后续在主方法会重新传参数
public static final String MYSQL_SELECT_RECORD_KEY = "mysql.input.select.record"; //查询记录的sql,后续在主方法会重新传参数
public static final String MYSQL_INPUT_SPLIT_KEY = "mysql.input.split.pre.record.count"; //决定多少条记录1个split,后续在主方法会重新传参数
public static final String MYSQL_OUTPUT_VALUE_CLASS_KEY = "mysql.output.value.class"; //最终输出的value,暂时不管
@Override
public List<InputSplit> getSplits(JobContext context) throws IOException, InterruptedException {
//该方法的作用就是返回数据分块,ApplicationMaster根据分块信息数量决定map task的数量
Configuration conf = context.getConfiguration();
Connection conn = null; //Mysql链接
PreparedStatement pstmt = null;
ResultSet rs = null;
String sql = conf.get(MYSQL_SELECT_KEY);
long recordCount = 0;//总记录数量
try {
conn = this.getConnection(conf);
//传入的sql是查询总数量的,在执行主程序中会传入select count(*) from
pstmt = conn.prepareStatement(sql);
rs = pstmt.executeQuery();
if (rs.next()){
//recordCount = 表的总行数
recordCount = rs.getLong(1); //获取数量
}
} catch (Exception e) {
e.printStackTrace();
}finally {
this.closeConnection(conn,pstmt,rs);
}
//开始处理生成input split
List<InputSplit> list = new ArrayList<InputSplit>();
//把配置文件中的MYSQL_INPUT_SPLIT_KEY对应的value取出来,如果没找到,则取默认值(100)
long preRecordCountOfSplit = conf.getLong(MYSQL_INPUT_SPLIT_KEY,100);
int numSplits = (int)(recordCount / preRecordCountOfSplit + (recordCount % preRecordCountOfSplit ==0 ? 0:1));
for (int i = 0; i < numSplits; i++) {
if (i != numSplits-1){
list.add(new MysqlInputSplit(i*preRecordCountOfSplit,(i+1)*preRecordCountOfSplit));
}else{
list.add(new MysqlInputSplit(i*preRecordCountOfSplit,recordCount));
}
}
return list;
}
@Override
public RecordReader<LongWritable, V> createRecordReader(InputSplit split, TaskAttemptContext context) throws IOException, InterruptedException {
//返回具体处理分块数据的recordReader类对象
RecordReader<LongWritable,V> reader = new MysqlRecordReader();
// reader.initialize(split,context);
return reader;
}
//根据配置信息获取数据库链接
private Connection getConnection(Configuration conf) throws SQLException, ClassNotFoundException {
String driver = conf.get(MYSQL_INPUT_DRIVER_KEY);
String url = conf.get(MYSQL_INPUT_URL_KEY);
String username = conf.get(MYSQL_INPUT_USERNAME_KEY);
String password = conf.get(MYSQL_INPUT_PASSWORD_KEY);
Class.forName(driver);
return DriverManager.getConnection(url,username,password);
}
//关闭链接
private void closeConnection(Connection conn,Statement state,ResultSet rs) {
try {
if (rs!=null)rs.close();
if (state!=null)state.close();
if (conn!=null)conn.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
//自定义读取数据的recordReader类
public class MysqlRecordReader extends RecordReader<LongWritable,V>{
private Connection conn;
private Configuration conf;
private MysqlInputSplit split;
private LongWritable key = null;
private V value = null;
private ResultSet resultSet = null;
private long post = 0; //位置信息
@Override
public void initialize(InputSplit split, TaskAttemptContext context) throws IOException, InterruptedException {
//传入分块信息,当我们传入的mysplit是1-4时,查询的结果就是1-4行记录
this.split = (MysqlInputSplit) split;
this.conf = context.getConfiguration();
}
//创建value对象
private V createValue(){
Class<? extends MysqlInputValue> clazz= this.conf.getClass(MYSQL_OUTPUT_VALUE_CLASS_KEY,NullMysqlInputValue.class,MysqlInputValue.class);
return (V) ReflectionUtils.newInstance(clazz,this.conf);
}
//获取查询sql
private String getQuerqSql(){
String sql = this.conf.get(MYSQL_SELECT_RECORD_KEY);
try {
//根据传入的split数值,形成查询数据的sql,当我们传入的mysplit是1-4时,查询的结果就是1-4行记录
sql += " limit "+ this.split.getLength();
sql += " offset "+ this.split.getStart();
} catch (Exception e) {
e.printStackTrace();
}
return sql;
}
//重写方法--获取下一行的value
@Override
public boolean nextKeyValue() throws IOException, InterruptedException {
//防止key、value、链接为空
if(this.key == null){
this.key = new LongWritable();
}
if(this.value == null){
this.value = this.createValue();
}
if(this.conn==null){
try {
this.conn = MysqlInputFormat.this.getConnection(this.conf);
} catch (Exception e) {
e.printStackTrace();
}
}
try {
//还没查数据库时才需要查resuleSet
if(resultSet ==null){
//调用getQuerqSql方法查询当前split的数据
String sql = this.getQuerqSql();
PreparedStatement pstmt = this.conn.prepareStatement(sql);
//把查询到的数据输入到resultSet中
this.resultSet = pstmt.executeQuery();
}
//正式的进行处理操作
if(!this.resultSet.next()){
return false;//resultSet没有结果了
}
//Mapper会调用run方法循环执行nextKeyValue()(就是我们重写的这个方法)
//备注(Mapper不是直接调用我们的方法,中间经过很多层,比如MapTask类,里面还会执行进度(progress的修改)
//因此我们实现的时候只需要写每一行是如何传入value的就可以了
//这里我们调用了UrlCountMapperInputValue实体类的写参数的方法
this.value.readFields(this.resultSet);
this.key.set(this.post);
this.post++;
return true;
} catch (SQLException e) {
e.printStackTrace();
}
return false;
}
//重写方法,返回当前行的key值
@Override
public LongWritable getCurrentKey() throws IOException, InterruptedException {
return this.key;
}
//重写方法,返回当前行的value
@Override
public V getCurrentValue() throws IOException, InterruptedException {
return this.value;
}
//重写方法,当前recordreader的进度,需要返回0-1中间的值
//所以返回了当前位置和本块总的长度
@Override
public float getProgress() throws IOException, InterruptedException {
return this.post/this.split.getLength();
}
//重写方法,关闭记录读取器--因此添加关闭连接的代码
@Override
public void close() throws IOException {
MysqlInputFormat.this.closeConnection(this.conn,null,this.resultSet);
}
}
//默认的空输出对象
public class NullMysqlInputValue extends MysqlInputValue{
@Override
public void readFields(ResultSet rs) throws SQLException {}
public void write(DataOutput out) throws IOException {}
public void readFields(DataInput in) throws IOException {}
}
//继承InputSplit类,重写数据分块的方法
//继承InputSplit的时候一定要同时实现序列化接口,否则会报错
//使用内部类的时候序列化必须要static
public static class MysqlInputSplit extends InputSplit implements Writable {
private String[] emptyLocation = new String[0];
private long start;//从第几行开始读数据(包含这一行)
private long end;//读到第几行(不包含)
@Override
public long getLength() throws IOException, InterruptedException {
//分片大小,就是读了几行数据
return this.end-this.start;
}
@Override
public String[] getLocations() throws IOException, InterruptedException {
// 返回一个空的数组,表示不进行数据本地化的优化,那么map执行节点随机选择
//虽然是随机选择但是Hadoop默认会使用同一节点执行计算
return emptyLocation;
}
//重写序列化方法
public void write(DataOutput out) throws IOException {
out.writeLong(this.start);
out.writeLong(this.end);
}
//重写反序列化方法
public void readFields(DataInput in) throws IOException {
this.start = in.readLong();
this.end = in.readLong();
}
//下面是set/get和构造器
public long getStart() {
return start;
}
public void setStart(long start) {
this.start = start;
}
public long getEnd() {
return end;
}
public void setEnd(long end) {
this.end = end;
}
public MysqlInputSplit() {
}
public MysqlInputSplit(long start, long end) {
this.start = start;
this.end = end;
}
}
}
MR输出格式概述
数据输出格式(OutputFormat)
用于描述MR作业的数据输出规范。
输出格式作用:
输出规范检查(如检查HDFS文件目录是否存在等)
提供作业结果数据输出等功能。
自定义输出格式需要实现:
顶级输出格式类为:org.apache.hadoop.mapreduce.OutputFormat
顶级数据写出类为:org.apache.hadoop.mapreduce.RecordWriter
Hadoop内置输出格式
Hadoop提供了大量的内置数据输出格式,包括:MapFileOutputFormat、SequenceFileOutputFormat、SequenceFileAsBinaryOutputFormat、TextOutputFormat等。最常用的是TextOutputFormat
TextOutputFormat是MR框架默认的数据输出格式。
可以将计算结果以key+"\t"+value的形式逐行输出到文本文件中。
当key或者value有一个为NullWritable或者为null的时候,当前为空的值不进行输出,只输出不为空的值。对应的数据输出类为LineRecordWriter(按行输出)。
分隔符由参数mapreduce.output.textoutputformat.separator指定(默认是\t)
自定义MySQL输出格式
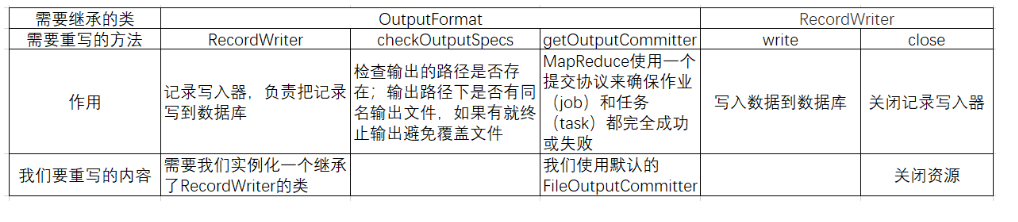
自定义输出格式,我们需要继承OutputFormat和RecordWriter两个类,并重写以下方法:
基本的作用和我们要重写的内容见下表。
下表内容并不限定于MySQL中取数(就是从文件取数也要实现这些)
自定义输出格式抽象类,和输入的类似,先定义一个输出到MySQL的抽象类
package com.rzp.ofdemo;
import org.apache.hadoop.io.Writable;
import java.sql.PreparedStatement;
import java.sql.SQLException;
/**
* mysql定义的输出value顶级父类
*/
public abstract class MysqlOutputValue implements Writable {
//获取数据库连接的sql语句
public abstract String getInsertOrUpdateSql();
//设置数据输出参数
public abstract void setPreparedStatementParameters(PreparedStatement pstmt) throws SQLException;
}
自定义输出格式
package com.rzp.ofdemo;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.mapreduce.lib.output.FileOutputCommitter;
import org.apache.hadoop.mapreduce.*;
import org.apache.hadoop.conf.Configuration;
import java.io.IOException;
import java.sql.*;
import java.util.HashMap;
import java.util.Map;
/**
* 自定义OutputFormat类,输出key/value到mysql数据库中
* 要求key为NullWritable
*/
public class MysqlOuputFormat<V extends MysqlOutputValue> extends OutputFormat<NullWritable,V> {
public static final String MYSQL_OUTPUT_DRIVER_KEY = "mysql.input.driver";
public static final String MYSQL_OUTPUT_URL_KEY = "mysql.input.url";
public static final String MYSQL_OUTPUT_USERNAME_KEY = "mysql.input.username";
public static final String MYSQL_OUTPUT_PASSWORD_KEY = "mysql.input.password";
public static final String MYSQL_OUTPUT_BATCH_SIZE_KEY = "mysql.input.batch.size";
public MysqlOuputFormat() {
super();
}
//重写方法,返回一个继承了RecordWriter的类
@Override
public RecordWriter<NullWritable, V> getRecordWriter(TaskAttemptContext context) throws IOException, InterruptedException {
return new MysqlRecordWriter(context.getConfiguration());
}
//重写方法--检查输出路径是否规范
//1.输出路径是否存在
//2.输出路径下是否已经有了输出文件
//我们输出到MySQL的表的情况下,只要检查链接是否正常即可
@Override
public void checkOutputSpecs(JobContext context) throws IOException, InterruptedException {
Connection conn = null;
try {
conn = this.getConnection(context.getConfiguration());
} catch (ClassNotFoundException e) {
e.printStackTrace();
} catch (SQLException e) {
e.printStackTrace();
}finally {
this.closeConnection(conn,null,null);
}
}
//Hadoop的事务,我们使用默认的FileOutputCommitter
@Override
public FileOutputCommitter getOutputCommitter(TaskAttemptContext context) throws IOException, InterruptedException {
return new FileOutputCommitter(null,context);
}
//根据配置信息获取数据库链接
private Connection getConnection(Configuration conf) throws ClassNotFoundException, SQLException {
String driver = conf.get(MYSQL_OUTPUT_DRIVER_KEY);
String url = conf.get(MYSQL_OUTPUT_URL_KEY);
String username = conf.get(MYSQL_OUTPUT_USERNAME_KEY);
String password = conf.get(MYSQL_OUTPUT_PASSWORD_KEY);
Class.forName(driver);
return DriverManager.getConnection(url,username,password);
}
//关闭连接
private void closeConnection(Connection conn, Statement state, ResultSet rs){
try {
if (rs!=null)rs.close();
if (state!=null)state.close();
if (conn!=null)conn.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
//自定义的输出到Mysql的record writer类
public class MysqlRecordWriter extends RecordWriter<NullWritable,V>{
private Connection conn = null;
private Map<String,PreparedStatement> pstmtCache = new HashMap<String,PreparedStatement> ();
private Map<String,Integer> batchCache = new HashMap<String, Integer>();
private Configuration conf = null;
private int batchSize = 100; //每100行数据commit一次到数据库
//因为每次一行一行写效率太低,我们使用prepareStatement的batch机制
//和输入类似,会循环执行write方法
@Override
public void write(NullWritable key, V value) throws IOException, InterruptedException {
if (this.conn==null){
try {
this.conn = getConnection(conf);
this.conn.setAutoCommit(false); //取消自动提交
} catch (Exception e) {
e.printStackTrace();
}
}
String sql = value.getInsertOrUpdateSql();//获取Insert的sql
//注意sql一直都是“INSERT INTO stats_uv(url,date,uv) VALUES(?,?,?)”,所以一直都是一个key
PreparedStatement pstmt = this.pstmtCache.get(sql);
System.out.println(sql);
System.out.println(pstmt==null);
System.out.println(pstmt);
if(pstmt==null){
//创建pstmt对象并存入pstmtCache中
try {
pstmt = this.conn.prepareStatement(sql);
this.pstmtCache.put(sql,pstmt);
} catch (SQLException e) {
e.printStackTrace();
}
}
//计算这一Batch正在插入第几条数据,并放入到BatchCache中
Integer count = this.batchCache.get(sql);
if (count==null){
count = 0;
}
//设置往数据库写入的值
try {
value.setPreparedStatementParameters(pstmt);
count++;
//数量超过100行就提交
if (count>this.batchSize){
pstmt.executeBatch(); //进行批量执行
this.conn.commit();//提交
count = 0; //重置计数器
}
this.batchCache.put(sql,count); //修改计数器
pstmt.addBatch(); //添加到batch,后续批量执行
} catch (SQLException e) {
e.printStackTrace();
}
}
//关闭RecordWriter,把未提交的所有记录都提交
@Override
public void close(TaskAttemptContext context) {
if(this.conn!=null){
for(Map.Entry<String,PreparedStatement> entry :this.pstmtCache.entrySet()){
try {
entry.getValue().executeBatch();
this.conn.commit();
} catch (SQLException e) {
e.printStackTrace();
}
}
}
}
public MysqlRecordWriter() {
}
public MysqlRecordWriter(Configuration conf) {
this.conf = conf;
this.batchSize = this.conf.getInt(MYSQL_OUTPUT_BATCH_SIZE_KEY,this.batchSize);
}
}
}
测试
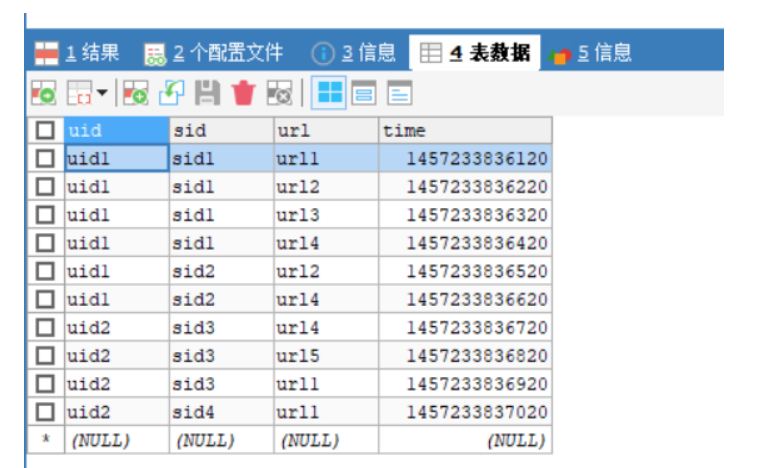
统计event_logs这个表中不同url的登录次数,相同uid和sid的只算一次,输出到另一个表中。
Mapper输入bean
package com.rzp.pojo;
import com.rzp.ifdemo.MysqlInputValue;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import java.sql.ResultSet;
import java.sql.SQLException;
//自定义输入value对象
public class UrlCountMapperInputValue extends MysqlInputValue {
private String uid;
private String sid;
private String url;
private long time;
public void write(DataOutput out) throws IOException {
out.writeUTF(this.uid);
out.writeUTF(this.sid);
out.writeUTF(this.url);
out.writeLong(this.time);
}
public void readFields(DataInput in) throws IOException {
this.uid = in.readUTF();
this.sid = in.readUTF();
this.url = in.readUTF();
this.time = in.readLong();
}
@Override
public void readFields(ResultSet rs) throws SQLException {
this.uid = rs.getString("uid");
this.sid = rs.getString("sid");
this.url = rs.getString("url");
this.time = rs.getLong("time");
}
public String getUid() {
return uid;
}
public void setUid(String uid) {
this.uid = uid;
}
public String getSid() {
return sid;
}
public void setSid(String sid) {
this.sid = sid;
}
public String getUrl() {
return url;
}
public void setUrl(String url) {
this.url = url;
}
public long getTime() {
return time;
}
public void setTime(long time) {
this.time = time;
}
}
Mapper输出key bean,注意键值要重写Hashcode和equals方法
package com.rzp.pojo;
import com.google.common.base.Objects;
import org.apache.commons.lang.builder.EqualsBuilder;
import org.apache.commons.lang.builder.HashCodeBuilder;
import org.apache.hadoop.io.WritableComparable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
//自定义Mapper输出key
public class UrlCountMapperOutputKey implements WritableComparable<UrlCountMapperOutputKey> {
private String url;
private String date; //yyyy-mm-dd
public void write(DataOutput out) throws IOException {
out.writeUTF(this.url);
out.writeUTF(this.date);
}
public void readFields(DataInput in) throws IOException {
this.url = in.readUTF();
this.date = in.readUTF();
}
public int compareTo(UrlCountMapperOutputKey o) {
int tmp = this.url.compareTo(o.url);
if(tmp!=0){
return tmp;
}
return this.date.compareTo(o.date);
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
UrlCountMapperOutputKey that = (UrlCountMapperOutputKey) o;
if (!url.equals(that.url)) return false;
return date.equals(that.date);
}
@Override
public int hashCode() {
int result = url.hashCode();
result = 31 * result + date.hashCode();
return result;
}
public String getUrl() {
return url;
}
public void setUrl(String url) {
this.url = url;
}
public String getDate() {
return date;
}
public void setDate(String date) {
this.date = date;
}
}
Mapper输出value bean
package com.rzp.pojo;
import org.apache.hadoop.io.Writable;
import org.apache.hadoop.io.WritableComparable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
//自定义Mapper输出key
public class UrlCountMapperOutputValue implements Writable {
private String uid;
private String sid;
public void write(DataOutput out) throws IOException {
if(this.uid==null){
out.writeBoolean(false);
}else {
out.writeBoolean(true);
out.writeUTF(this.uid);
}
if(this.sid==null){
out.writeBoolean(false);
}else {
out.writeBoolean(true);
out.writeUTF(this.sid);
}
}
public void readFields(DataInput in) throws IOException {
this.uid = in.readBoolean()?in.readUTF():null;
this.sid = in.readBoolean()?in.readUTF():null;
}
public String getUid() {
return uid;
}
public void setUid(String uid) {
this.uid = uid;
}
public String getSid() {
return sid;
}
public void setSid(String sid) {
this.sid = sid;
}
}
reduce输出value bean
package com.rzp.pojo;
import com.rzp.ofdemo.MysqlOutputValue;
import org.apache.hadoop.io.Writable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import java.sql.PreparedStatement;
import java.sql.SQLException;
//自定义reducer输出类
public class UrlCountReducerOutputValue extends MysqlOutputValue {
private String url;
private String date;
private int uv;
@Override
public String getInsertOrUpdateSql() {
return "INSERT INTO stats_uv(url,date,uv) VALUES(?,?,?)";
}
@Override
public void setPreparedStatementParameters(PreparedStatement pstmt) throws SQLException {
pstmt.setString(1, this.url);
pstmt.setString(2, this.date);
pstmt.setInt(3, this.uv);
}
public void write(DataOutput out) throws IOException {
out.writeUTF(this.url);
out.writeUTF(this.date);
out.writeInt(this.uv);
}
public void readFields(DataInput in) throws IOException {
this.url = in.readUTF();
this.date = in.readUTF();
this.uv = in.readInt();
}
public String getUrl() {
return url;
}
public void setUrl(String url) {
this.url = url;
}
public String getDate() {
return date;
}
public void setDate(String date) {
this.date = date;
}
public int getUv() {
return uv;
}
public void setUv(int uv) {
this.uv = uv;
}
}
Mapper
package com.rzp.urlcount;
import com.rzp.pojo.UrlCountMapperInputValue;
import com.rzp.pojo.UrlCountMapperOutputKey;
import com.rzp.pojo.UrlCountMapperOutputValue;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
import java.text.SimpleDateFormat;
import java.util.Calendar;
import java.util.Date;
import java.util.logging.SimpleFormatter;
/**
* 自定义数据输入/输出格式验证案例
* 计算uv值
*/
public class UrlCountMapper extends Mapper<LongWritable, UrlCountMapperInputValue, UrlCountMapperOutputKey, UrlCountMapperOutputValue> {
private UrlCountMapperOutputKey outputKey = new UrlCountMapperOutputKey();
private UrlCountMapperOutputValue outputValue = new UrlCountMapperOutputValue();
private SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd");
private Calendar calendar = Calendar.getInstance();
@Override
protected void map(LongWritable key, UrlCountMapperInputValue value, Context context) throws IOException, InterruptedException {
String url = value.getUrl();
if(url!=null){
calendar.setTimeInMillis(value.getTime()); //设置毫秒级时间
long time = value.getTime();
this.outputKey.setUrl(url);
this.outputKey.setDate(this.sdf.format(calendar.getTime()));
this.outputValue.setUid(value.getUid());
this.outputValue.setSid(value.getSid());
context.write(this.outputKey,this.outputValue);
}
}
}
Reduce
package com.rzp.urlcount;
import com.rzp.pojo.UrlCountMapperOutputKey;
import com.rzp.pojo.UrlCountMapperOutputValue;
import com.rzp.pojo.UrlCountReducerOutputValue;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
import java.util.HashSet;
import java.util.Set;
//计算uv的reducer类
public class UrlCountReducer extends Reducer<UrlCountMapperOutputKey, UrlCountMapperOutputValue, NullWritable, UrlCountReducerOutputValue> {
private UrlCountReducerOutputValue outputValue = new UrlCountReducerOutputValue();
@Override
protected void reduce(UrlCountMapperOutputKey key, Iterable<UrlCountMapperOutputValue> values, Context context) throws IOException, InterruptedException {
Set<String> set = new HashSet<String>();
for (UrlCountMapperOutputValue value : values) {
set.add(value.getSid());
}
int uv = set.size();
this.outputValue.setUrl(key.getUrl());
this.outputValue.setDate(key.getDate());
this.outputValue.setUv(uv);
context.write(NullWritable.get(),this.outputValue);
}
}
runner
package com.rzp.service;
import com.rzp.ifdemo.MysqlInputFormat;
import com.rzp.ifdemo.MysqlInputValue;
import com.rzp.ofdemo.MysqlOuputFormat;
import com.rzp.pojo.UrlCountMapperInputValue;
import com.rzp.pojo.UrlCountMapperOutputKey;
import com.rzp.pojo.UrlCountMapperOutputValue;
import com.rzp.pojo.UrlCountReducerOutputValue;
import com.rzp.urlcount.UrlCountMapper;
import com.rzp.urlcount.UrlCountReducer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
import java.io.InputStream;
import java.io.OutputStream;
public class UrlCountRunner implements Tool {
private Configuration conf = new Configuration();
public void setConf(Configuration conf) {
this.conf = conf;
this.conf.set("mapreduce.framework.name","local");;
}
public Configuration getConf() {
return this.conf;
}
public int run(String[] args) throws Exception {
Configuration conf = this.getConf();
Job job = Job.getInstance(conf,"test-format");
job.setJarByClass(UrlCountRunner.class);
//后面直接修改conf,可以直接传递到job中去
conf = job.getConfiguration();
//job设置
conf.set(MysqlInputFormat.MYSQL_INPUT_DRIVER_KEY,"com.mysql.cj.jdbc.Driver");
conf.set(MysqlInputFormat.MYSQL_INPUT_URL_KEY,"jdbc:mysql://localhost:3308/mybatis?useUnicode=true&characterEncoding=utf8&useSSL=true&serverTimezone=GMT%2B8");
conf.set(MysqlInputFormat.MYSQL_INPUT_USERNAME_KEY,"root");
conf.set(MysqlInputFormat.MYSQL_INPUT_PASSWORD_KEY,"mysql");
conf.set(MysqlInputFormat.MYSQL_SELECT_KEY,"select count(1) from event_logs");
conf.set(MysqlInputFormat.MYSQL_SELECT_RECORD_KEY,"select uid,sid,url,time from event_logs");
conf.setLong(MysqlInputFormat.MYSQL_INPUT_SPLIT_KEY,5);
conf.setClass(MysqlInputFormat.MYSQL_OUTPUT_VALUE_CLASS_KEY, UrlCountMapperInputValue.class,MysqlInputValue.class);
job.setInputFormatClass(MysqlInputFormat.class);
//设置mapper
job.setMapperClass(UrlCountMapper.class);
job.setMapOutputKeyClass(UrlCountMapperOutputKey.class);
job.setMapOutputValueClass(UrlCountMapperOutputValue.class);
//设置reducer
job.setReducerClass(UrlCountReducer.class);
job.setOutputKeyClass(NullWritable.class);
job.setOutputValueClass(UrlCountReducerOutputValue.class);
//设置outputformat
conf.set(MysqlOuputFormat.MYSQL_OUTPUT_DRIVER_KEY,"com.mysql.cj.jdbc.Driver");
conf.set(MysqlOuputFormat.MYSQL_OUTPUT_URL_KEY,"jdbc:mysql://localhost:3308/mybatis?useUnicode=true&characterEncoding=utf8&useSSL=true&serverTimezone=GMT%2B8");
conf.set(MysqlOuputFormat.MYSQL_OUTPUT_USERNAME_KEY,"root");
conf.set(MysqlOuputFormat.MYSQL_OUTPUT_PASSWORD_KEY,"mysql");
conf.setInt(MysqlOuputFormat.MYSQL_OUTPUT_BATCH_SIZE_KEY,10);
job.setOutputFormatClass(MysqlOuputFormat.class);
return job.waitForCompletion(true) ?0:1;
}
public static void main(String[] args) throws Exception {
ToolRunner.run(new UrlCountRunner(),args);
}
}
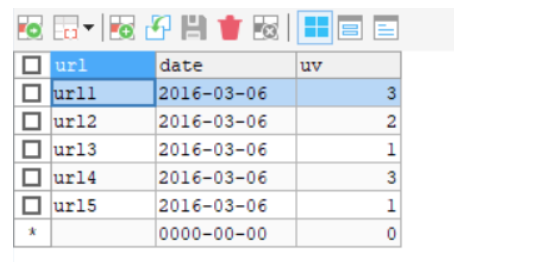
输出结果
最新文章
- ubuntu 入门
- 使用SQL语句查询日期(当月天数,当月第一天,当月最后一天,本年最后一天,当月第一个星期) 日期转字符串
- fir.im Weekly - 1000 个 Android 开源项目集合
- MVP 实例
- Mysql-通过case..when实现oracle decode()函数进行多值多结果判断
- 浅谈java性能分析
- sasscore学习之_mixin.scss
- fetch API
- 什么是Nib文件?(Nib文件是一种特殊类型的资源文件,它用于保存iPhone OS或Mac OS X应用程序的用户接口)
- maven的update project是什么意思
- 网页抓取:PHP实现网页爬虫方式小结
- hibernate篇章六--demo(0.准备工作)
- java代码中获取进程process id(转)
- android圆角View实现及不同版本号这间的兼容
- Struts2第四篇【请求数据自动封装、Action得到域对象】
- File类_常见的方法(获取目录中指定规则的内容)_listFiles
- 黄聪:浓缩的才是精华:浅析GIF格式图片的存储和压缩(转)
- Linux quotacheck失败
- Android Studio 通过 git update 或者 pull 的时候出错及解决办法
- Haskell语言学习笔记(39)Category