MATLAB神经网络(1) BP神经网络的数据分类——语音特征信号分类
1.1 案例背景
1.1.1 BP神经网络概述
BP神经网络是一种多层前馈神经网络,该网络的主要特点是信号前向传递,误差反向传播。在前向传递中,输入信号从输入层经隐含层逐层处理,直至输出层。每一层的神经元状态只影响下一层神经元状态。如果输出层得不到期望输出,则转入反向传播,根据预测误差调整网络权值和阔值,从而使BP神经网络预测输出不断逼近期望输出。
当输入节点数为$n$、输出节点数为$m$时, BP 神经网络就表达了从$n$个自变量到$m$个因变量的函数映射关系。
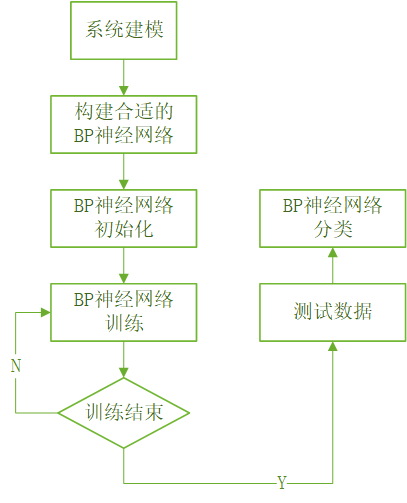
BP 神经网络预测前首先要训练网络,通过训练使网络具有联想记忆和预测能力。 BP神经网络的训练过程包括以下几个步骤:
- 网络初始化:根据系统输入输出序列($X$,$Y$)确定网络输入层节点数$n$、隐含层节点数$l$,输出层节点数$m$,初始化输入层、隐含层和输出层神经元之间的连接权值$\omega_{ij}$、$\omega_{jk}$,初始化隐含层阈值$a$、输出层阈值$b$,给定学习速率和神经元激励函数。
- 隐含层输出计算:根据输入变量$X$,输入层和隐含层间连接权值$\omega_{ij}$以及隐含层阁值$a$,计算隐含层输出$H$。\[{H_j} = f\left( {\sum\limits_{i = 1}^n {{\omega _{ij}}{x_i} - {a_j}} } \right){\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} j = 1,2, \ldots ,l\]式中,$l$为隐含层节点数,$f$为隐含层激励函数,该函数有多种表达形式,此处所选函数为\[f(x) = \frac{1}{{1 + {e^{ - x}}}}\]
- 输出层输出计算。根据隐含层输出$H$,连接权值$\omega_{jk}$和阔值$b$,计算BP神经网络预测输出$O$。\[{O_k} = \sum\limits_{j = 1}^l {{H_j}{\omega _{jk}} - {b_k}} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} k = 1,2, \ldots ,m\]
- 误差计算:根据网络预测输出$O$和期望输出$Y$,计算网络预测误差$e$。\[{e_k} = {Y_k} - {O_k}\]
- 权值更新:根据网络预测误差$e$更新网络连接权值$\omega_{ij}$、$\omega_{jk}$。\[\begin{array}{l} {\omega _{ij}} = {\omega _{ij}} + \eta {H_j}(1 - {H_j})x(i)\sum\limits_{k = 1}^m {{\omega _{jk}}{e_k}} \\ {\omega _{jk}} = {\omega _{jk}} + \eta {H_j}{e_k}{\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} i = 1,2, \ldots ,n;j = 1,2, \ldots ,l;k = 1,2, \ldots ,m \end{array}\]式中,$\eta$为学习速率。
- 阈值更新:根据网络预测误差$e$更新网络节点阔值$a$、$b$。\[\begin{array}{l} {a_j} = {a_j} + \eta {H_j}(1 - {H_j})\sum\limits_{k = 1}^m {{\omega _{jk}}{e_k}} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} j = 1,2, \ldots ,l\\ {b_k} = {b_k} + \eta {e_k}{\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} k = 1,2, \ldots ,m \end{array}\]
- 判断算法迭代是否结束,若没有结束,返回步骤2。
1.1.2 语音特征信号识别
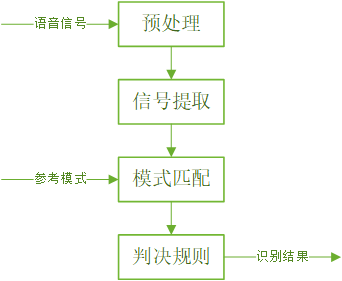
语音特征信号识别是语音识别研究领域中的一个重要方面,一般采用模式匹配的原理解决。语音识别的运算过程为:首先,待识别语音转化为电信号后输入识别系统,经过预处理后用数学方法提取语音特征信号,提取出的语音特征信号可以看成该段语音的模式;然后,将该段语音模型同已知参考模式相比较,获得最佳匹配的参考模式为该段语音的识别结果。
1.2 模型建立
民歌、古筝、摇滚、流行
倒谱系数法:500组24维语音特性信号
subplot(4,1,1)
plot(c1)
ylabel("民歌");
title("语音特征信号");
subplot(4,1,2)
plot(c2)
ylabel("古筝");
subplot(4,1,3)
plot(c3)
ylabel("摇滚");
subplot(4,1,4)
plot(c4)
xlabel("语音帧");
ylabel("流行");
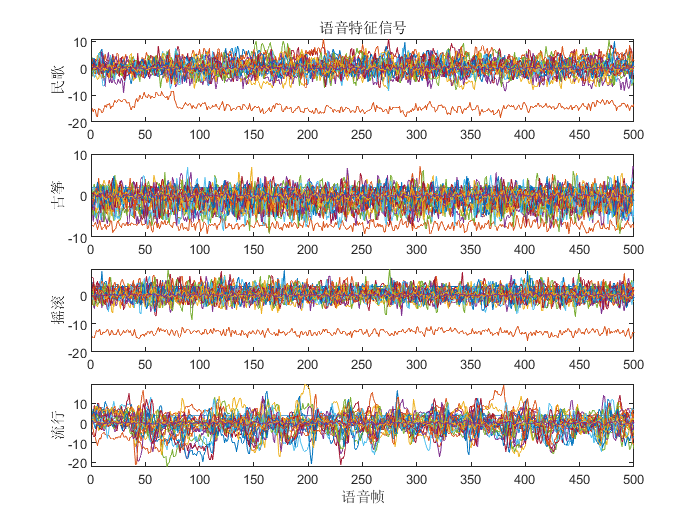
神经网络结构:24-25-4
1.3 MATLAB实现
1.3.1 归一化方法
- mapminmax:Processes matrices by normalizing the minimum and maximum values of each row to [YMIN,YMAX], [-1, 1] by default.
- [Y,PS] = mapminmax(X,YMIN,YMAX)
- [Y,PS] = mapminmax(X,FP)
- Y = mapminmax('apply',X,PS)
- X = mapminmax('reverse',Y,PS)
- dx_dy = mapminmax('dx_dy',X,Y,PS)
PS: Process settings that allow consistent processing of values.
1.3.2 数据选择和归一化
%% 基于BP网络的语言识别 %% 清空环境变量
clc
clear %% 训练数据预测数据提取及归一化 %加载四类语音信号
load('data1.mat')
load('data2.mat')
load('data3.mat')
load('data4.mat') %四个特征信号矩阵合成一个矩阵
data(1:500,:)=c1(1:500,:);
data(501:1000,:)=c2(1:500,:);
data(1001:1500,:)=c3(1:500,:);
data(1501:2000,:)=c4(1:500,:); size(data)
%从1到2000间随机排序
k=rand(1,2000);
[m,n]=sort(k);
[B,I] = sort(A) sorts the elements of A in ascending order. I is the same size as A and describes the arrangement of the elements of A into B along the sorted dimension. For example, if A is a vector, then B = A(I).
%输入输出数据
input=data(:,2:25);
output1 =data(:,1); %把输出从1维变成4维
output=zeros(2000,4);
for i=1:2000
switch output1(i)
case 1
output(i,:)=[1 0 0 0];
case 2
output(i,:)=[0 1 0 0];
case 3
output(i,:)=[0 0 1 0];
case 4
output(i,:)=[0 0 0 1];
end
end %随机提取1500个样本为训练样本,500个样本为预测样本
input_train=input(n(1:1500),:)';
output_train=output(n(1:1500),:)';
input_test=input(n(1501:2000),:)';
output_test=output(n(1501:2000),:)'; %输入数据归一化
[inputn,inputps]=mapminmax(input_train);
1.3.3 BP神经网络结构初始化
%% 网络结构初始化
innum=24;
midnum=25;
outnum=4; %权值初始化
w1=rands(midnum,innum);
b1=rands(midnum,1);
w2=rands(midnum,outnum);
b2=rands(outnum,1); %学习率
xite=0.1; %学习速率
loopNumber=10; %循环次数
I=zeros(1,midnum);
Iout=zeros(1,midnum);
FI=zeros(1,midnum);
dw1=zeros(innum,midnum);
db1=zeros(1,midnum);
1.3.4 BP神经网络训练
%% 网络训练
E=zeros(1,loopNumber);
for ii=1:loopNumber
for i=1:1:1500
%% 网络预测输出
x=inputn(:,i);
% 隐含层输出
for j=1:1:midnum
I(j)=inputn(:,i)'*w1(j,:)'+b1(j); %矩阵乘法,inputn是n×1500,w1是l×n
%inputn(:,i)'是1×n,w1(j,:)'是n×1
Iout(j)=1/(1+exp(-I(j))); %Iout是1×l
end
% 输出层输出
yn=w2'*Iout'+b2; %矩阵乘法,w2是l×m,Iout是1×l
%w2'是m×l,Iout'是l×1,yn是m×1 %% 权值阀值修正
%计算误差
e=output_train(:,i)-yn;
E(ii)=E(ii)+sum(abs(e)); %计算权值变化率
dw2=e*Iout; %m×l
db2=e'; for j=1:1:midnum
S=1/(1+exp(-I(j)));
FI(j)=S*(1-S);
end
for k=1:1:innum
for j=1:1:midnum
dw1(k,j)=FI(j)*x(k)*sum(e'*w2(j,:)');
db1(j)=FI(j)*sum(e'*w2(j,:)');
end
end w1=w1+xite*dw1';
b1=b1+xite*db1';
w2=w2+xite*dw2';
b2=b2+xite*db2';
end
end
1.3.5 BP神经网络分类
%% 语音特征信号分类
inputn_test=mapminmax('apply',input_test,inputps);
fore=zeros(4,500);
for ii=1:1
for i=1:500%1500
%隐含层输出
for j=1:1:midnum
I(j)=inputn_test(:,i)'*w1(j,:)'+b1(j);
Iout(j)=1/(1+exp(-I(j)));
end
fore(:,i)=w2'*Iout'+b2;
end
end
1.3.6 结果分析
%% 结果分析
%根据网络输出找出数据属于哪类
output_fore=zeros(1,500);
for i=1:500
output_fore(i)=find(fore(:,i)==max(fore(:,i)));
end %BP网络预测误差
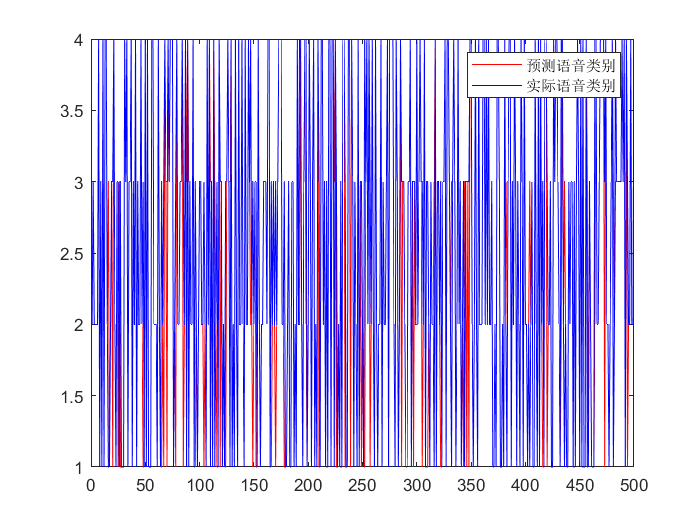
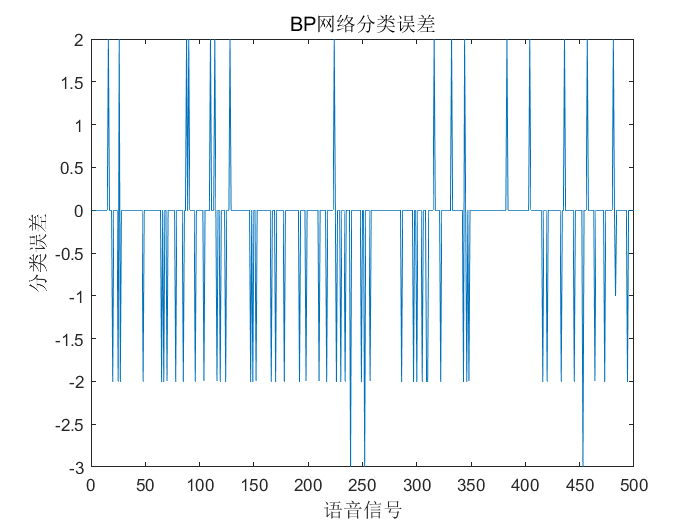
error=output_fore-output1(n(1501:2000))'; %画出预测语音种类和实际语音种类的分类图
figure(1)
plot(output_fore,'r')
hold on
plot(output1(n(1501:2000))','b')
legend('预测语音类别','实际语音类别')
%画出误差图
figure(2)
plot(error)
title('BP网络分类误差','fontsize',12)
xlabel('语音信号','fontsize',12)
ylabel('分类误差','fontsize',12)
[tbl,chi2,p] = crosstab(x1,x2,...,xn) returns a multi-dimensional cross-tabulation, tbl, of data for multiple input vectors, x1, x2, ..., xn, and also the chi-square statistic, chi2, and itsp-value, p, for a test that tbl is independent in each dimension.
[tbl,chi2,p]=crosstab(output_fore,output1(n(1501:2000))')

%正确率
rightridio=zeros(1,4);
ss=sum(tbl);
for i=1:4
rightridio(i)=tbl(i,i)./ss(i);
end
disp(rightridio);
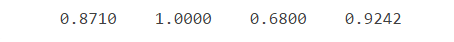
plot(E)
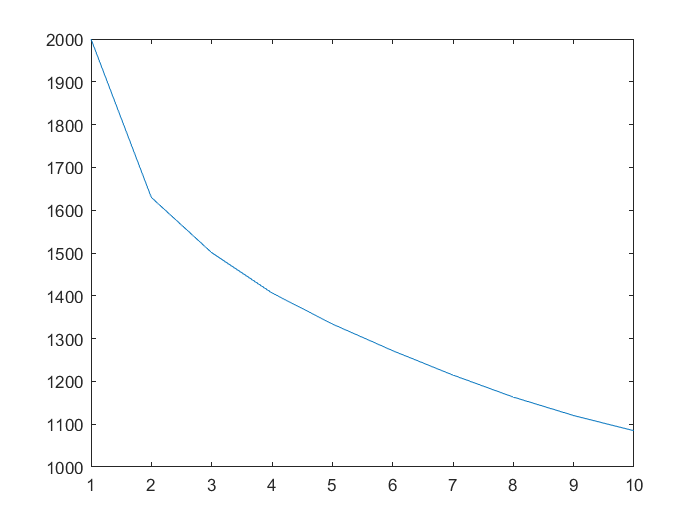
上图展现了10次迭代过程中,总误差绝对值之和的变化趋势。
1.4 扩展
1.4.1 隐含层节点数
参考公式:
\[\begin{array}{l}
l < n - 1\\
l < \sqrt {m + n} + a\\
l = {\log _2}n
\end{array}\]
$a$为0到10之间的常数。
1.4.2 附加动量方法
BP 神经网络的采用梯度修正法作为权值和阔值的学习算法,从网络预测误差的负梯度方向修正权值和阔值,没有考虑以前经验的积累,学习过程收敛缓慢。对于这个问题,可以采用附加动量方法来解决,带附加动量的权值学习公式为\[\omega (k) = \omega (k - 1) + {\eta _1}\Delta \omega (k) + {\eta _2}[\omega (k - 1) - \omega (k - 2)]\]式中${\eta _1}$、${\eta_2}$为学习率。
1.4.3 变学习率学习算法
BP神经网络学习率的取值在[0,1]之间,学习率越大,对权值的修改越大,网络学习速度越快。但过大的学习速率将使权值学习过程产生震荡,过小的学习率使网络收敛过慢,权值难以趋于稳定。变学习率方法是指学习率在BP神经网络进化初期较大,网络收敛迅速,随着学习过程的进行,学习率不断减小,网络趋于稳定.变学习率计算公式为\[\eta (t) = {\eta _{\max }} - t({\eta _{\max }} - {\eta _{\min }})/{t_{\max }}\]式中$\eta_{max}$为最大学习率,$\eta_{min}$为最小学习率,$t_{max}$为最大迭代次数,$t$为当前迭代次数。
最新文章
- 使用nginx部署Yii 2.0\yii-advanced-app-2.0.6
- 【转载】关于.NET里的内存泄漏
- Malformed \uxxxx encoding解决方法
- Do It Wrong, Get It Right
- php 安全过滤函数代码
- new Date参数问题
- Java 并发编程(三)为线程安全类中加入新的原子操作
- angular中的cookie读写
- [uva11992]Fast Matrix Operations(多延迟标记,二维线段树,区间更新)
- 设置PL/SQL 快捷键
- java上传文件常见几种方式
- Java并发编程(六)-- 同步块
- Linux命令第一篇
- 10.Oracle Golden Date(ogg)的搭建和管理
- MySQL开发——【高级操作、五子句】
- ASP.NET Web API中通过URI显示实体中的部分字段
- Eclipse添加tomcat服务器以及解决404的问题
- 虚拟机 VMware Tools 安装
- windows 2003 iis php
- librdkafka 源码分析