Redis五种基础与三种高级数据结构解析
记得点赞+关注呦。
前言
在 Redis 最重要最基础就属 它丰富的数据结构了,Redis 之所以能脱颖而出很大原因是他数据结构丰富,可以支持多种场景。并且 Redis 的数据结构实现以及应用场景在面试中是相当常见的,接下来就和大家聊聊 Redis 的数据结构。
Redis数据结构有:string、list、hash、set、sorted set 这五个是大家都知道的,但Redis还有更高级得数据结构,比如:HyperLogLog、Geo、BloomFilter 这几个数据结构,接下来聊聊Redis得这些数据结构吧。
String
基本概念:String 是 Redis 最简单最常用的数据结构,也是 Memcached 唯一的数据结构。在平时的开发中,String 可以说是使用最频繁的了。
底层实现:
- 如果一个字符串对象保存的是整数值, 并且这个整数值可以用 long 类型来表示, 那么字符串对象会将整数值保存在字符串对象结构的 ptr 属性里面(将 void* 转换成 long ), 并将字符串对象的编码设置为 int 。
- 如果字符串对象保存的是一个字符串值, 并且这个字符串值的长度大于 39 字节, 那么字符串对象将使用一个简单动态字符串(SDS)来保存这个字符串值, 并将对象的编码设置为 raw。
- 如果字符串对象保存的是一个字符串值, 并且这个字符串值的长度小于等于 39 字节, 那么字符串对象将使用 embstr 编码的方式来保存这个字符串值。
使用:
> redis_cli # 启动redis-cli 客户端
> set hello world # 将键 hello 的值设置为 world
OK # set 命令成功后 会返回 OK
> get hello # 通过 get 命令获取 键为 hello 的值
"world" # 获得到的值
> del hello # 删除键为 hello 的值
(integer) 1 # 返回的是删除的数量
> mset a 10 b 20 c 30 # 批量的设置值
OK
> mget a b c # 批量的返回值
1)"10"
2)"20"
3)"30"
> exists hello # 是否存在该键
(integer) 1 # 1 表示存在,0 表示不存在
> expire hello 10 # 给 hello 设置过期时间,单位,秒
(integer) 1 # 返回1代表成功,0代表key不存在或无法设置过期时间
> pexpire hello 10 # 给 hello 设置过期时间,单位,毫秒
(integer) 1 # 返回1代表成功,0代表key不存在或无法设置过期时间
接下来会重点讲一下 set key value [EX seconds] [PX milliseconds] [NX|XX] 这个一系列命令,这块还是挺重要的,也很容易混淆。
reids 每次对 以前的值覆盖时,会 清空 TLL 值。(TTL 是过期时间)
- EX second:设置键的过期时间为 second 秒。 SET key value EX second 效果等同于 SETEX key second value 。
- PX millisecond :设置键的过期时间为 millisecond 毫秒。 SET key value PX millisecond 效果等同于 PSETEX key millisecond value 。
- NX :只在键不存在时,才对键进行设置操作。 SET key value NX 效果等同于 SETNX key value 。
- XX :只在键已经存在时,才对键进行设置操作。
# 使用 EX 选项
> set key1 hello EX 1000 # 设置 过期时间 1000s
OK
> ttl hello # 获取 hello 的过期时间
(integer) 1000
# 使用 PX 选项
> set key1 hello PX 1000 # 设置 过期时间 1000ms
OK
> ttl hello # 获取 hello 的过期时间
(integer) 1000
# 使用 NX 选项
> set hello world NX
OK # 键不存在,设置成功
> get hello
"value"
> set hello world NX
(nil) # 键已经存在,设置失败
> get hello
"world" # 维持原值不变
# 使用 XX 选项
> exists hello # 先确定 hello 不存在
(integer) 0
> set hello world XX
(nil) # 因为键不存在,设置失败
> set hello wolrd # 先给 hello 设置一个值
OK
> set hello newWolrd XX
OK # 这回设置成功了
> get hello
"newWorld"
# NX 或 XX 可以和 EX 或者 PX 组合使用
> set hello world EX 1000 NX
OK
> get hello
"world"
> ttl hello
(integer)1000
> set hello wolrd PX 30000 NX
OK
> pttl hello
(integer)30000 # 实际操作中 这个值肯定小于 30000,这次是为了效果才这么写的
# EX 和 PX 可以同时出现,但后面给出的选项会覆盖前面给出的选项
> set hello wolrd EX 1000 PX 30000
OK
> ttl hello
(integer)30 # 这个是 PX 设置的参数,
> pttl hello
(integer)30000
> set number 1
OK
> incr number # 对 number 做自增操作
(integer) 2
在开发过程中,用 redis 来实现锁是很常用的操作。结合 NX 以及 EX 来实现。
> set hello world NX EX 10 # 成功加锁,过期时间是 10s
OK
> set hello wolrd NX EX 10 # 在10s内执行这个命令返回错误,因为上一次的锁还没有释放
(nil)
> del hello # 释放了锁
OK
> set hello world NX EX 10 # 成功加锁,过期时间是 10s
OK
> setnx hello world # 也可以这么写
> setex hello 10 wolrd
锁可以通过设置过期时间以及手动 del 删除来释放锁。
string 的命令比较常用就多介绍了点,下面的命令我就挑重点介绍了。
应用场景:
- 缓存功能:string 最常用的就是缓存功能,会将一些更新不频繁但是查询频繁的数据缓存起来,以此来减轻 DB 的压力。
- 计数器:可以用来计数,通过 incr 操作,如统计网站的访问量、文章访问量等。
List
基本概念: list 是有序可重复列表,和 Java 的 List 蛮像的,查询速度快,可以通过索引查询;插入删除速度慢。
底层实现:
- 列表对象的编码可以是 ziplist 或者 linkedlist 。
- 列表对象保存的所有字符串元素的长度都小于 64 字节并且保存的元素数量小于 512 个,使用 ziplist 编码;否则使用 linkedlist;
使用:
> lpush mylist a # 从左边插入数据
(ineteger)1
> lpush mylist b
(integer)1
> rpush mylist c # 从右边插入数据
(integer)1
> lrange mylist 0 -1 # 检索数据,lrange 需要两个索引,左闭右闭;0 就是从第 0 个,-1 是倒数第一个,-2 倒数第二个...以此类推
1)"b"
2)"a"
3)"c"
> lrange mylist 0 -2 # 0 到 倒数第 2 个
1)"b"
2)"a"
> lpush mylist a b c # 批量插入
(integer)3
> lpop mylist # 从左侧弹出元素
"b"
> rpop mylist # 从右侧弹出元素
"c"
> rpop mylist # 当列表中没有元素时返回 null
(nil)
> brpoop mylist 5 # 从右侧弹出元素,如果列表没有元素,会阻塞住,如果 5 s后还是没有元素则返回
1)"mylist" # 列表名
2)"b" # 弹出元素
> del mylist # 删除列表
(integer)1
使用场景:
- 消息队列:Redis 的 list 是有序的列表结构,可以实现阻塞队列,使用左进右出的方式。Lpush 用来生产 从左侧插入数据,Brpop 用来消费,用来从右侧 阻塞的消费数据。
- 数据的分页展示: lrange 命令需要两个索引来获取数据,这个就可以用来实现分页,可以在代码中计算两个索引值,然后来 redis 中取数据。
- 可以用来实现粉丝列表以及最新消息排行等功能。
Hash
简介:Redis 散列可以存储多个键值对之间的映射。和字符串一样,散列存储的值既可以是字符串又可以是数值,并且用户同样可以对散列存储的数字值执行自增或自减操作。这个和 Java 的 HashMap 很像,每个 HashMap 有自己的名字,同时可以存储多个 k/v 对。
底层实现:
- 哈希对象的编码可以是 ziplist 或者 hashtable 。
- 哈希对象保存的所有键值对的键和值的字符串长度都小于 64 字节并且保存的键值对数量小于 512 个,使用ziplist 编码;否则使用hashtable;
使用:
> hset student name 张三 # 可以理解为忘名叫student的map中添加 kv 键值对
(integer)1 # 返回1 代表 不存在这个key,并且添加成功
> hset student sex 男
(integer)1
> hset student name 张三
(integer)0 # 返回0 因为这个key已经存在
> hgetall student
1)"name"
2)"张三"
3)"sex"
4)"男"
> hdel student name #删除这key
(integer)1 # 返回 1 同样代表整个 key 存在 并且删除成功
> hdel student name
(integer)0 # 返回 0 是因为 该 key 已经不存在
应用场景:
- Hash 更适合存储结构化的数据,比如 Java 中的对象;其实 Java 中的对象也可以用 string 进行存储,只需要将 对象 序列化成 json 串就可以,但是如果这个对象的某个属性更新比较频繁的话,那么每次就需要重新将整个对象序列化存储,这样消耗开销比较大。可如果用 hash 来存储 对象的每个属性,那么每次只需要更新要更新的属性就可以。
- 购物车场景:可以以用户的id为key,商品的id 为存储的field,商品数量为键值对的value,这样就构成了购物车的三个要素。
Set
基本概念:Redis 的set和list都可以存储多个字符串,他们之间的不同之处在于,list是有序可重复,而set是无序不可重复。
底层实现:
- 集合对象的编码可以是 intset 或者 hashtable 。
- 集合对象保存的所有元素都是整数值并且保存的元素数量不超过 512 个,使用intset 编码;否则使用hashtable;
使用:
> sadd family mother # 尝试将 mother 添加进 family 集合中
(integer)1 # 返回 1 表示添加成功,0 表示元素已经存在集合中
> sadd family father
(integer)1
> sadd family father
(intger)0
> smembers family # 获取集合中所有的元素
1)"mother"
2)"father"
> sismember family father # 判断 father 是否在 family 集合中
(integer)1 # 1 存在;0 不存在
> sismber family son
(integer)0
> srem family son # 移除 family 集合中元素 son
(integer)1 # 1 表示存在并且移除成功;0 表示存在该元素
> srem family som
(integer)0
> sadd family1 mother
(integer)1
> smembers family
1)"mother"
2)"father"
> smember family1
1)"mother"
> sinter family family1 # 获取 family 和 family1 的交集
1)"mother"
> sadd family1 son
(integer)1
> sunion family family1 # 获取 family 和 family1 的并集
1)"mother"
2)"father"
> sdiff family family1 # 获取 family 和 family1 的差集(就是family有但是family1没有的元素)
1)"father"
应用场景:
- 标签:可以将博客网站每个人的标签用 set 集合存储,然后还按每个标签 将用户进行归并。
- 存储好友/粉丝:set 具有去重功能;还可以利用set并集功能得到共同好友之类的功能。
Sorted Set
基本概念:有序集合和散列一样,都用于存储键值对:其中有序集合的每个键称为成员(member),都是独一无二的,而有序集合的每个值称为分值(score),都必须是浮点数。可以根据分数进行排序,有序集合是Redis里面唯一既可以根据成员访问元素(这一点和散列一样),又可以根据分值以及分值的排列顺序来访问元素的结构。和Redis的其他结构一样,用户可以对有序集合执行添加、移除和获取等操作。
底层实现:
- 有序集合的编码可以是 ziplist 或者 skiplist
- 有序集合保存的元素数量小于 128 个并且保存的所有元素成员的长度都小于 64 字节。使用 ziplist 编码;否则使用skiplist;
使用:
> zadd class 100 member1 # 将member1元素及其score值100加入到 有序集合 class中
(integer)1
> zadd class 90 member2 80 member3 # 批量添加
(integer)2
> zrange class 0 -1 withscores # 获取有序集合中的值与score,并按 score 排序
1)"member3"
2)"80"
3)"member2"
4)"90"
5)"member1"
6)"100"
> zrem class member1 # 删除 class 中 的member1
(integer)1
应用场景:
- 排行榜:有序集合最常用的场景。如新闻网站对热点新闻排序,比如根据点击量、点赞量等。
- 带权重的消息队列:重要的消息 score 大一些,普通消息 score 小一些,可以实现优先级高的任务先执行。
HyperLogLog
基本概念:
Redis 在 2.8.9 版本添加了 HyperLogLog 结构。
Redis HyperLogLog 是用来做基数统计的算法,HyperLogLog 的优点是,在输入元素的数量或者体积非常非常大时,计算基数所需的空间总是固定 的、并且是很小的。
在 Redis 里面,每个 HyperLogLog 键只需要花费 12 KB 内存,就可以计算接近 2^64 个不同元素的基 数。这和计算基数时,元素越多耗费内存就越多的集合形成鲜明对比。
但是,因为 HyperLogLog 只会根据输入元素来计算基数,而不会储存输入元素本身,所以 HyperLogLog 不能像集合那样,返回输入的各个元素。
使用:
这里就拿一个统计网站2021年5月23日,有多少用户登录举例
> pfadd user_login_20210523 tom # user_login_20210523是key;tom 是登录的用户
(integer)1
> pfadd user_login_20210523 tom jack lilei 的用户
(integer)1
> pfcount user_login_20210523 # 获取 key 对应值的数量,同一个用户多次登录只统计一次
(integer) 3
> pfadd user_login_20210522 sira
(integer)1
> pfcount user_login_20210523 user_login_20210522 # 统计22号和23号一共有多少登陆的用户
(integer)4
>pfmerge user_login_20210522_23 user_login_20210522 user_login_20210523 # 将连个键内容合并
"OK"
> pfcount user_login_20210522_23
(integer)4
应用场景:
- 可以用来统计网站的登陆人数以及其他指标
GEO
基本概念:
在 Redis 3.2 版本中新增了一种叫 geo 的数据结构,它主要用来存储地理位置信息,并对存储的信息进行操作。
使用:
geoadd 用于存储指定的地理空间位置,可以将一个或多个经度(longitude)、纬度(latitude)、位置名称(member)添加到指定的 key 中。
> GEOADD beijing 116.405285 39.912835 "蘑菇睡不着"
(integer)2
geopos 用于从给定的 key 里返回所有指定名称(member)的位置(经度和纬度),不存在的返回 nil。
> GEOPOS beijing "蘑菇睡不着" "故宫"
1) 1)116.405285
2)39.912835
2)(nil)
geodist 用于返回两个给定位置之间的距离。
单位参数:
m :米,默认单位。
km :千米。
mi :英里。
ft :英尺。
> GEOADD beijing 116.403681 39.921156 "故宫"
(integer)1
> GEODIST beijing "蘑菇睡不着" "故宫" km
"0.936"
应用场景:
用于存储地理信息以及对地理信息作操作的场景。
科普一个地理小知识:
经度范围:-180 - 180。从0°经线算起,向东、向西各分作180°,以东的180°属于东经,习惯上用“E”作代号,以西的180°属于西经,习惯上用“W”作代号。0°位置是:英国格林威治(Greenwich)天文台子午仪中心的经线为本初子午线。
纬度范围:-90 - 90。位于赤道以北的点的纬度叫北纬,记为N;位于赤道以南的点的纬度称南纬,记为S。为了研究问题方便,人们把纬度分为低、 中、高纬度。0°~30°为低纬度, 30°~ 60°为中纬度, 60~90°为高纬度。
BloomFilter
基本概念:
一种数据结构,是由一串很长的二进制向量组成,可以将其看成一个二进制数
组。既然是二进制,那么里面存放的不是0,就是1,但是初始默认值都是0。他的主要作用是:判断一个元素是否在某个集合中。比如说,我想判断20亿的号码中是否存在某个号码,如果直接插DB,那么数据量太大时间会很慢;如果将20亿数据放到 缓存 中,缓存也装不下。这个时候用 布隆过滤器 最合适了,布隆过滤器的原理是:
- 添加元素
当要向布隆过滤器中添加一个元素key时,我们通过多个hash函数,算出一个值,然后将这个值所在的方格置为1。
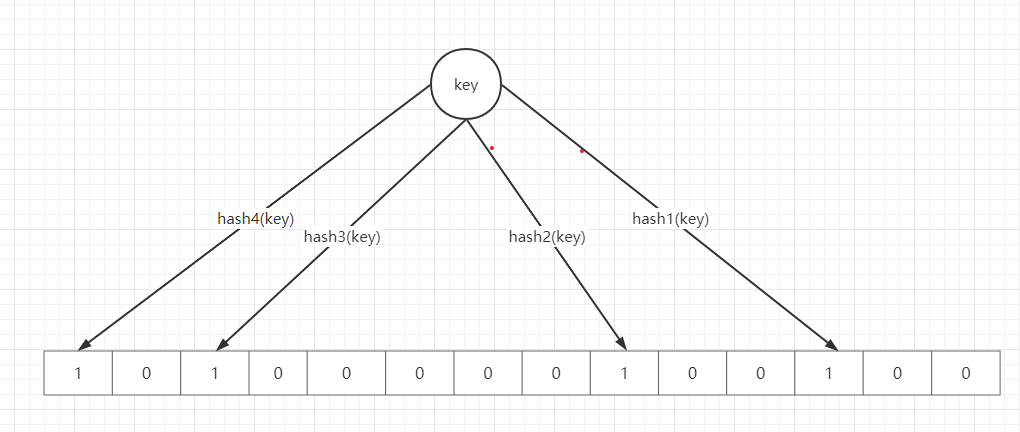
- 判断元素是否存在:
判断元素是否存在,是先将元素经过多个hash函数计算,计算到多个下标值,然后判断这些下标对应的元素值是否都为1,如果存在不是 1 的,那么元素肯定不在集合中;如果都是 1,那么元素大概率在集合中,并不能百分之百肯定元素存在集合中,因为多个不同的数据通过hash函数算出来的结果是会有重复的,所以会存在某个位置是别的数据通过hash函数置为的1。
总的来说:布隆过滤器可以判断某个数据一定不存在,但是无法判断一定存在。 - 布隆过滤器的优缺点:
- 优点:优点很明显,二进制组成的数组,占用内存极少,并且插入和查询速度都足够快。
- 缺点:随着数据的增加,误判率会增加;还有无法判断数据一定存在;另外还有一个重要缺点,无法删除数据。
使用:
redis 4.0 后可以使用 布隆过滤器的插件RedisBloom,命令如下:
bf.add 添加元素到布隆过滤器
bf.exists 判断元素是否在布隆过滤器
bf.madd 添加多个元素到布隆过滤器,bf.add只能添加一个
bf.mexists 判断多个元素是否在布隆过滤器
> bf.add boomFilter tc01
(integer) 1 # 1:存在;0:不存在
> bf.add boomFilter tc02
(integer) 1
> bf.add boomFilter tc03
(integer) 1
> bf.exists boomFilter tc01
(integer) 1
> bf.exists boomFilter tc02
(integer) 1
> bf.exists boomFilter tc03
(integer) 1
> bf.exists boomFilter tc04
(integer) 0
> bf.madd boomFilter tc05 tc06 tc07
1) (integer) 1
2) (integer) 1
3) (integer) 1
> bf.mexists boomFilter tc05 tc06 tc07 tc08
1) (integer) 1
2) (integer) 1
3) (integer) 1
4) (integer) 0
1. Redisson 使用布隆过滤器 :
public static void main(String[] args) {
Config config = new Config();
config.useSingleServer().setAddress("redis://192.168.15.105:6379");
config.useSingleServer().setPassword("password123");
//构造Redisson
RedissonClient redisson = Redisson.create(config);
RBloomFilter<String> bloomFilter = redisson.getBloomFilter("userPhones");
//初始化布隆过滤器:预计元素为500000000L,误差率为3%
bloomFilter.tryInit(500000000L,0.03);
//将号码10086插入到布隆过滤器中
bloomFilter.add("18846014678");
//判断下面号码是否在布隆过滤器中
System.out.println(bloomFilter.contains("18846014678")); //true
System.out.println(bloomFilter.contains("1111111222")); //false
}
2. Guava 使用布隆过滤器:
Guava 是谷歌提供的 Java 工具包,功能非常强大
public static void main(String[] args) {
BloomFilter<String> bloomFilter = BloomFilter.create(Funnels.stringFunnel(Charsets.UTF_8), 500000, 0.01);
bloomFilter.put("18846047789");
System.out.println(bloomFilter.mightContain("18846047789")); // true
System.out.println(bloomFilter.mightContain("1122222")); //false
}
}
应用场景:
解决缓存穿透问题:一般得查询场景都是先去查询缓存,如果缓存没有,那么就去 DB 查询,如果查到了,先存在 缓存 中,然后返回给调用方。如果查不到就返回空。这种情况如果有人频繁的请求缓存中没有得数据,比如id = -1 得数据,那么会对 DB 造成极大得压力,这种情况就可以使用 redis 得布隆过滤器了,可以先将可能得id都存在布隆过滤器中,当查询来的时候,先去布隆过滤器查,如果查不到直接返回,不请求缓存以及DB,如果存在 布隆过滤器 中,那么才去缓存中取数据。
黑名单校验:可以将黑名单中得ip放入到布隆过滤器中,这样不用每次来都去 db 中查询了。
总结
Redis 丰富的数据结构是支撑 Redis 重要基石之一。他使 Redis 可以适应很多复杂的场景。这块的内容在面试中可以说是必考的内容,所以要在这方面要多下些功夫。
更多的知识干货以及leetcode题解析,可以来公众号蘑菇睡不着看看,可能会对你有帮助。
看到这里记得 点赞+关注+转发
最新文章
- Pyqt 基础功能
- css3动画之小牛奔跑
- .NET MVC TempData、ViewData、ViewBag
- time模块
- redis pipeline
- Bungie Interview with Halo3 Developer
- ettercap ARP dns 欺骗
- HTTP请求头host解析
- 解决忽略VScode中Python插件pylint报错的问题
- windows系统命令行
- index.go
- 关于Http协议,你必须要知道的
- curl 向远程服务器传输file文件
- SocketIO Server
- js面向对象实例
- Springboot2.x 集成jsp
- 虚拟机中不能连接usb设备解决办法
- IIS启用GZIP压缩js、css无效的原因及解决方法
- 【BZOJ2141】排队 树状数组+分块
- ChromeSwitchySharp代理设置步骤