MySQL索引的基本理解
之前一致以为索引就是简单的在原表的数据上加了一些编号,让查询更加快捷。后来发现里面还有更深的知识。
索引用于快速查找具有特定列值的行。如果没有索引,MySQL 必须从第一行开始,然后通读整个表以找到相关行。表数据越多,成本就越高。如果表有相关列的索引,MySQL 可以快速确定要在数据文件中间查找的位置,而无需查看所有数据。这比顺序读取每一行要快得多。
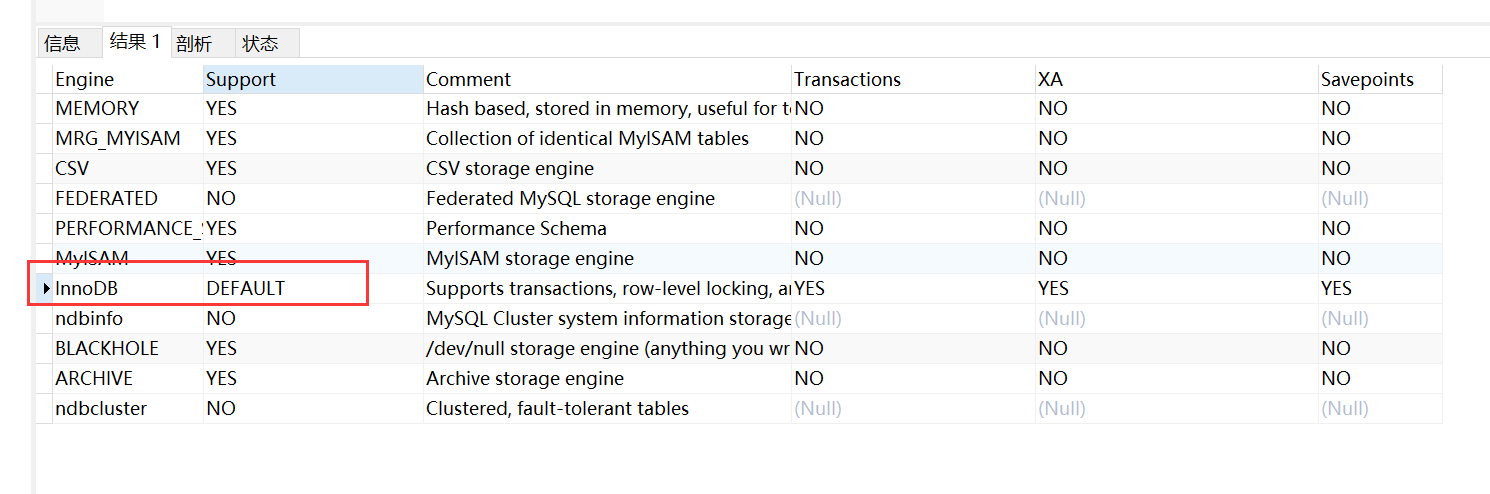
自从MySQL5.5版本之后,MySQL的默认存储引擎就变成了InnoDB。
-- 查看当前数据库支持的搜素引擎
show ENGINES;
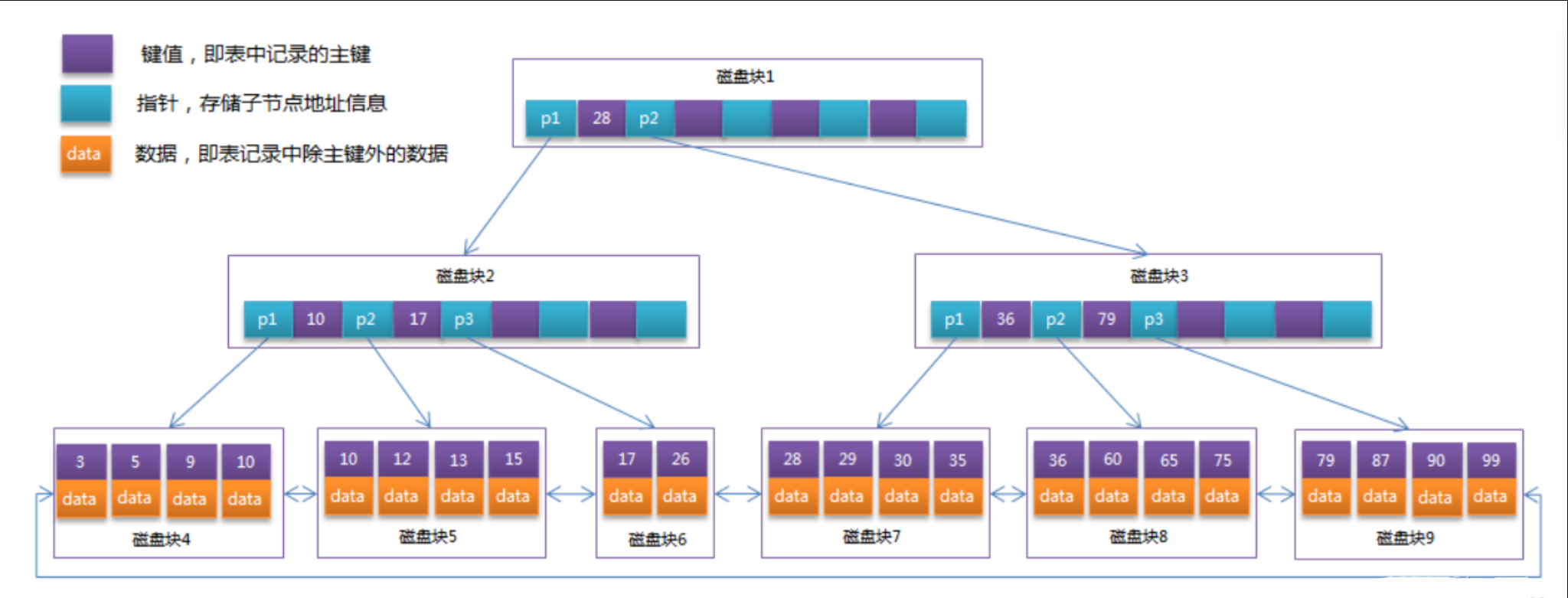
当我们创建一个表时,InnoDB引擎会根据主键给我们创建一个聚簇索引树。
会形成一个只有叶子节【最下面的节点】点存储数据的B+ tree。
除了叶子节点,其余的节点存储的是主键的值以及指向下一个节点的指针信息。
先看官方说明:


简而言之:
InnoDB默认会给创建一个根据主键id的聚簇索引的B+ tree,如果没有主键就根据下面的规则:
InnoDB聚集索引的叶子节点存储行记录,因此, InnoDB必须要有,且只有一个聚集索引:
(1)如果表定义了主键,则主键就是聚集索引;
(2)如果表没有定义主键,则第一个not NULL unique列是聚集索引;
(3)否则,InnoDB会创建一个隐藏的row-id作为聚集索引;
后面我们再创建的索引统一被称之为二级索引(非主键索引、辅助索引),当然也会创建一个B+ tree。
只不过相较于聚簇索引的B+ tree来说,二级索引叶子节点上存储的为数据为主键的值,聚簇索引的叶子节点上存储的为真正的一条数据。
好处:
避免了当数据发生修改的时候,大量B+ tree跟着修改。
那二级索引被触发后,是怎么查询到数据的?
答:
这涉及到了两个概念:
回表
通过二级索引(辅助索引)树查询索引数据,然后再通过聚集索引树查询完整数据的过程称为回表。
覆盖
select字段已经包含在用到的索引中的时候称为覆盖索引。
比如说:我们创建了一个关于
name字段的索引,当我们查询name的时候就会触发覆盖索引
可以通过EXPLAIN关键字查看时候出发了覆盖:
执行计划中出现Using index 字样,表示用到了覆盖索引,没有产生回表的操作。
-- 创建一个组合索引
create index idx_name_sex on t_user(name,sex);
-- 触发了覆盖索引
EXPLAIN SELECT name,sex from t_user where name = 'name4999008'
-- 触发了覆盖索引
EXPLAIN SELECT name from t_user where name = 'name4999008' and sex = '男'
-- 没有触发覆盖索引
EXPLAIN SELECT * from t_user where name = 'name4999008'

最新文章
- Python开发【第二篇】:Python基础知识
- JQ常用代码
- 【转载】LR提交JSON格式的请求
- Atitit Immutability 和final的优点
- Loadrunner之API测试
- [LintCode] Segment Tree Build 建立线段树
- Eclipse 汉化包
- Linux驱动开发之开篇--HelloWorld
- LoadRunner调用Java程序—性能测试-转载
- C++中基类对象的引用
- c语言:链表排序, 链表反转
- CodeForces 618B Guess the Permutation
- 浅谈Activiti Modeler 的扩展
- linux下批量查找UTF-8的BOM文件,并去除BOM
- 【PHP篇】变量与常量
- [转]git图解(3):分支操作
- 大话设计模式(C#)
- linux更换yum源
- Linux内核编译指定输出目录
- EL的隐含对象 (二)【访问作用域范围的隐含对象】
热门文章
- oracle 内置函数(一)数值函数
- Pod控制器详解
- C++编程笔记(GPU并行编程)
- Kafka教程(三):原理及存储
- Java语言进阶 day02【Collection、泛型】
- 【实时数仓】Day01-数据采集层:数仓分层、实时需求、架构分析、日志数据采集(采集到指定topic和落盘)、业务数据采集(MySQL-kafka)、Nginx反向代理、Maxwell、Canel
- 2022年Kubernetes CKA 认证真题解析完整版
- Django框架三板斧本质-jsonResponse对象-form表单上传文件request对象方法-FBV与CBV区别
- 时间片差分调度法-充分利用MCU的资源
- 使用 Helm 安装 MQTT 服务器-EMQX