Pandas复杂查询、数据类型转换、数据排序
2024-09-23 04:32:27
Pandas高级操作
1、复杂查询
(1)逻辑运算
以DataFrame其中一列进行逻辑计算,会产生一个对应的bool值组成的Series
于是我们可以利用返回的bool列表进行一系列的数据查询
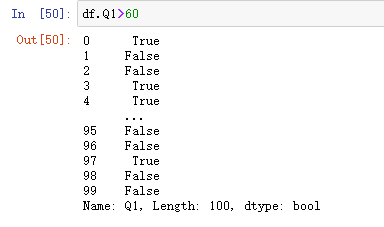
(2)逻辑筛选数据
df[df['Q1'] == 8] # Q1 等于8
df[~(df['Q1'] == 8)] # 不等于8
- 进行与或非的操作时,各个独立的逻辑表达式记得要加括号,不然报错
- df['Q2']等价于df.Q2
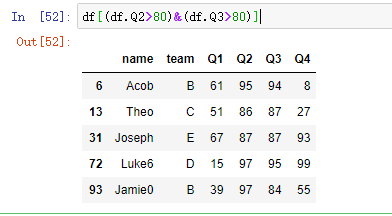
(3)函数筛选
df[lambda df: df['Q1'] == 8] # Q1为8的数据,返回dateframe
df.loc[lambda df: df.Q1 == 8, 'Q1':'Q2'] # Q1为8的, 显示 Q1 Q2
- 表达式可以用lambda函数代替,默认传入的变量是其操作对象
(4)比较函数
df.eq() # 等于相等 ==
df.ne() # 不等于 !=
df.le() # 小于等于 >=
df.lt() # 小于 <
df.ge() # 大于等于 >=
df.gt() # 大于 >
# 都支持 axis{0 or ‘index’, 1 or ‘columns’}, default ‘columns’
df[df.Q1.ne(89)] # Q1 不等于8
df.loc[df.Q1.gt(90) & df.Q2.lt(90)] # and 关系 Q1>90 Q2<90
# isin,该方法返回一个bool列表
df[df.team.isin(['A','B'])] # 包含 AB 两组的
df[df.isin({'team': ['C', 'D'], 'Q1':[36,93]})] # 复杂查询,其他值为 NaN
(5)查询df.query
df.query('Q1 > Q2 > 90') # 直接写类型 sql where 语句
df.query('Q1 + Q2 > 180')
(6)筛选df.filter
df.filter(items=['Q1', 'Q2']) # 选择两列
df.filter(regex='Q', axis=1) # 列名包含Q的数据,返回dataframe
df.filter(regex='1$', axis=0) # 正则, 索引名包含1的
df.filter(like='2', axis=0) # 索引中有2的,返回dataframe
# 索引中2开头列名有Q的
df.filter(regex='^2', axis=0).filter(like='Q', axis=1)
(7)按数据类型查询
df.select_dtypes(include=['float64']) # 选择 float64 型数据
df.select_dtypes(include='bool')
df.select_dtypes(include=['number']) # 只取数字型
df.select_dtypes(exclude=['int']) # 排除 int 类型
2、数据类型转换
(1)推断类型
# 自动转换合适的数据类型
df.convert_dtypes() # 推荐!新的方法,支持 string 类型
df.infer_objects()
(2)指定类型pd.to_xxx()
s = pd.to_numeric(s) # 转成数字
pd.to_datetime(m) # 转成时间
pd.to_timedelta(m) # 转成时差
pd.to_datetime(m, errors='coerce') # 错误处理
pd.to_numeric(m, errors='ignore')
pd.to_numeric(m errors='coerce').fillna(0) # 兜底填充
pd.to_datetime(df[['year', 'month', 'day']]) # 组合成日期
(3)类型转换 astype()
df.dtypes # 查看数据类型
df.index.astype('int64') # 索引类型转换
df.astype('int32') # 所有数据转换为 int32
df.astype({'col1': 'int32'}) # 指定字段转指定类型
3、数据排序
(1)索引排序 sort_index()
s.sort_index() # 升序排列
df.sort_index() # df 也是按索引进行排序
df.team.sort_index()
s.sort_index(ascending=False) # 降序排列
s.sort_index(inplace=True) # 排序后生效,改变原数据
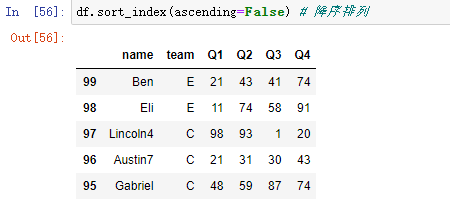
(2)数值排序 df.reindex()
- 指定自己定义顺序的索引,实现行和列的顺序重新定义:
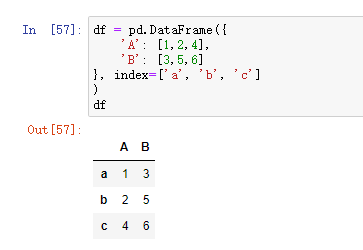

(3)混合排序 sort_values()
# df 按指定字段顺序
df.sort_values(by=['team'])
df.sort_values('Q1')
# 按多个字段,先排 team, 在同 team 内再看 Q1
df.sort_values(by=['team', 'Q1'])
最新文章
- [MongoDB]Profiling性能分析
- Java入门到精通——基础篇之多线程实现简单的PV操作的进程同步
- HTML 5 Audio/Video DOM buffered 属性
- 反汇编动态追踪工具Ollydbg. ALD,ddd,dbg,edb...
- 安装oracle11数据库时,先决条件都失败怎么处理?
- CF #April Fools Day Contest 2016 E Out of Controls
- 记一次调试串口设备Bug的经历
- java面向对象的构造函数
- [LeetCode] Maximum Distance in Arrays 数组中的最大距离
- Appium--入门demo
- ansible命令应用基础
- centos6.5搭建hadoop完整教程
- [Python数据挖掘]第5章、挖掘建模(下)
- E. Thematic Contests 二分,离散化
- Volley Get网络请求
- Java:【面向对象:类的定义,静态变量,成员变量,构造函数,封装与私有,this】
- 强大的矩阵奇异值分解(SVD)
- Spark job 部署模式
- 自然语言交流系统 phxnet团队 创新实训 项目博客 (九)
- minicom的安装和tftp的安装