【小记】golang_map
map
前言:map 几个操作实现有点复杂,即便之前看懂了没过多久也就忘了,这里简单做下记录。为了便于记忆,将 mapassign 的全过程以流程图的方式展示,其他省略
mapassign
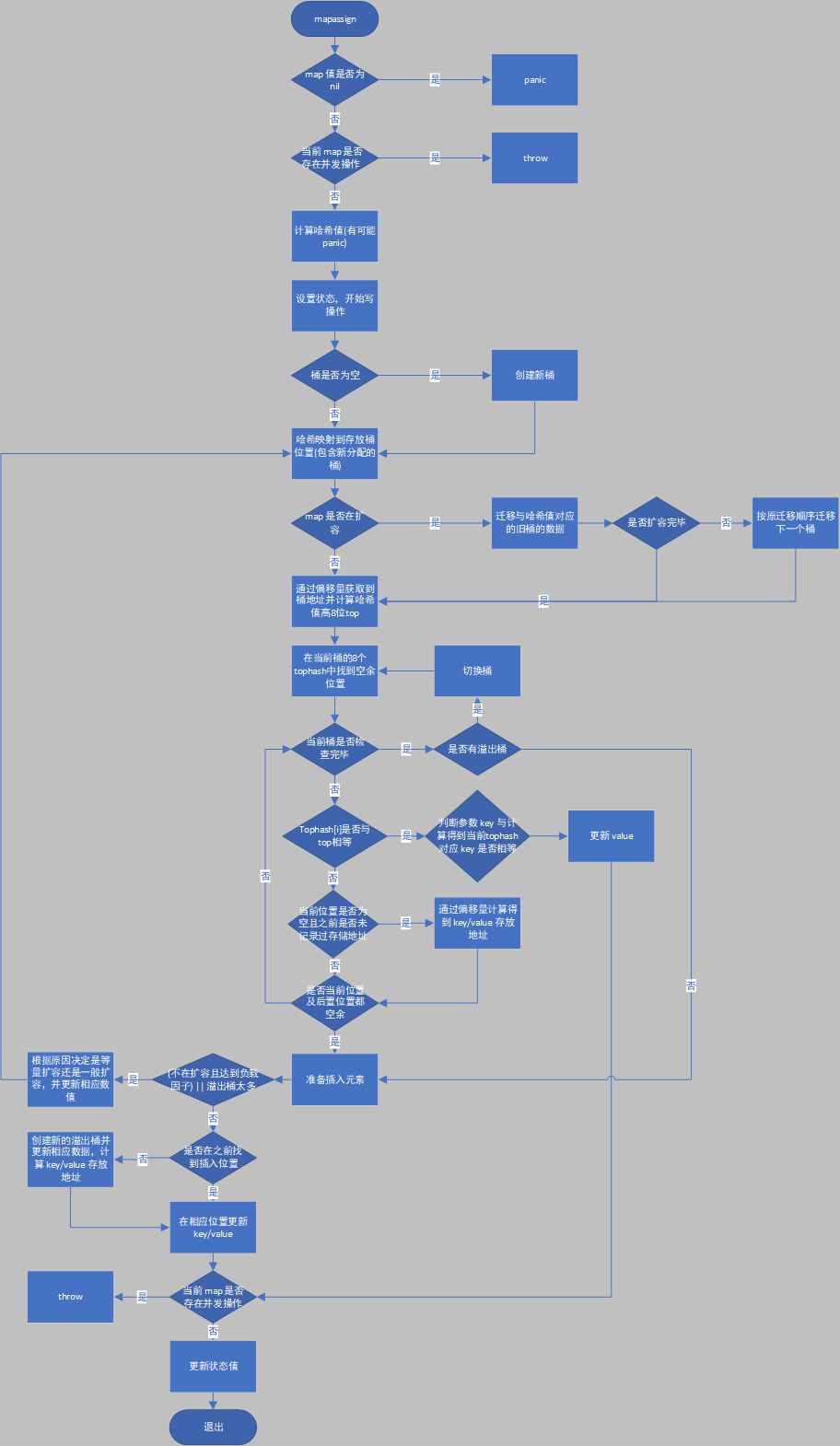
在流程图中可以看到 golang map 在扩容时采取渐进式扩容的策略
mapaccess
- mapaccess1: 用于类似于
val := h[key]只需一个返回值的形式 - mapaccess2: 用于类似于
val, exsit := h[key] - mapaccessK: 用于
for range且特殊时期 - mapaccess_fast<T>: 对 key 为特定类型的优化处理
返回 value 类型的零值
if h == nil || h.count == 0 {
...
return unsafe.Pointer(&zeroVal[0])
}
寻找对应的桶
if c := h.oldbuckets; c != nil {
// 如果存在旧桶数据,说明当前在扩容阶段,且可能查找的数据还未迁移,需要先从旧桶找起
if !h.sameSizeGrow() {
// 一般扩容时,会将容量扩大两倍,因此需要按照之前的数量重新计算哈希值
m >> 1
}
oldb := (*bmap)(add(c, (hash&m)*uintptr(t.bucketsize)))
if !evacuated(oldb) {
// 在 mapassign 的流程图中可以看到,迁移是一个桶带着它的溢出桶全部迁移的
// 所以如果该桶未发生迁移,就在当前桶以及其溢出桶查找即可
b = oldb
}
}
该处可以看到 mapaccess 与 mapassign 在扩容时查找数据的方式是有区别的。mapassign 会先迁移数据再去新桶查找,而 mapaccess 会在新旧桶中抉择
mapdelete
空表删键值对
if h == nil || h.count == 0 {
...
return
}
和 mapaccess 一样,对值为 nil 或不含任何键值对的 map 都可以操作。而 mapassign 不能对值为 nil 的 map 操作
重置状态
当成功删除一个键值对后,该 entry 的 tophash 被置为 emptyOne
// 注:进入后面步骤的前提是已经找到了需要删除的键值对,代码已省略
b.tophash[i] = emptyOne
if i == bucketCnt-1 { // 如果是当前桶最后一个 entry
if b.overflow(t) != nil && b.overflow(t).tophash[0] != emptyRest {
// 下一个溢出桶首个 tophash 不为 emptyRest,停止搜索
goto notLast
}
} else {
if b.tophash[i+1] != emptyRest {
// 下一个 entry 的 tophash 不为 emptyRest, 停止搜索
goto notLast
}
}
for {
// 当前 entry 状态为 emptyOne,且后置位状态为 emptyRest,更新当前位置状态
b.tophash[i] = emptyRest
if i == 0 {
// 当前桶以及其后溢出桶都空了
if b == bOrig {
// 若当前桶为第一个桶,代表已经回到初始桶,直接退出即可
break
}
// 寻找前一个桶,并从最后一个 entry 继续
c := b
for b = bOrig; b.overflow(t) != c; b = b.overflow(t) {}
i = bucketCnt - 1
} else {
// 倒序检查之前的 entry 的状态是否需要更改
i--
}
if b.tophash[i] != emptyOne {
// 遇到有存 key/value 的 entry 时结束
break
}
}
mapclear
停止扩容
h.flags &^ = sameSizeGrow // 停止等量扩容
h.oldbuckets = nil // 停止扩容
h.nevacuate = 0 // 停止迁移
清除内存
// makeBucketArray clears the memory pointed to by h.buckets
// and recovers any overflow buckets by generating them
// as if h.buckets was newly alloced.
// If dirtyalloc is nil a new backing array will be alloced and
// otherwise dirtyalloc will be cleared and reused as backing array.
mapclear 会保留正常桶,但是会清除溢出桶以及正常桶桶内的键值对,并且会根据正常桶数量决定是否重新生成溢出桶。也就是说,mapclear 类似于清空数据的等量扩容,但是并不会真的清空所有存储空间。
因此,如果当你想通过清除所有数据来减小 map 的内存占用,应该使用 make 重新赋值
tophash
tophash 不仅记录哈希值的高 8 位,还记录当前位置的状态值,例如:
- 当前位置的 key/value 被删除后,tophash 被置为 emptyOne,若后面的位置都为空,则进一步更新为 emptyRest。当发生哈希冲突时,可以减少比较次数和内存再分配
哈希冲突
解决哈希冲突的方法:
- Open addressing
- Linear probing
- 优点:简单
- 缺点:有 clustering 趋势:当很多冲突发生在同一个哈希值上,周围多个位置就会被填充满,影响其他要插入的元素
- Rehash
- 优点:在满足表大小为素数的条件下可以解决 clustering 问题
- 缺点:需要计算两次
- Quadratic probing
- Linear probing 的变体
- Linear probing
- Chaining
- 优点:不影响其他位置的元素
- 缺点:
- 当很多冲突发生在同一个哈希值上,那么搜索时复杂度就会退化到 O(n),这和 clustering 的影响一致
- 如果链表节点都是从堆中分配,可能造成内存碎片化
补充说明
- 一次迁移操作是将正常桶以及它的溢出桶全部迁移,每次扩容进行 1-2 次这样的操作
- 只有在赋值(mapassign)和删除键值对(mapdelete)时才会继续扩容(如果需要的话),在访问数据(mapaccess)时是不会进行扩容操作的
疑问
map 在判断并发读写上使用 hashWriting 来判断,但这个还是有几率漏判的吧?
【待补充】
可能会补充。。。
- 扩容细节
- 迁移细节
- 应用于 for range 的 iterator
- 对于计算溢出桶的细节没太看懂,没看懂为什么 - 8
最新文章
- docker学习(6) docker中搭建java服务及nginx反向代理
- 记一次eclipse无法启动的排查过程
- 第1章 UML基础:类的关系
- [Effective JavaScript 笔记] 第8条:尽量少用全局对象
- 一些比较好的shellscript脚本
- [React] React Router: IndexRoute
- UVA 11111-Generalized Matrioshkas(栈)
- 在Linux下如何用Shell脚本读写XML?现有一个config.xml(转)
- Ubuntu各种软件的安装
- iOS基础 - 内存分析
- ABP+AdminLTE+Bootstrap Table权限管理系统第四节--仓储,服务,服务接口及依赖注入
- Spring Security 入门(3-10)Spring Security 的四种使用方式
- centos/linux/ubuntu在局域网上网
- Jenkins安装及配置
- multiDex分包时指定主dex的class列表
- Docker 容器和镜像使用
- ruby中字符串转换为类
- 跟我学SharePoint 2013视频培训课程——排序、过滤在列表、库中的使用(10)
- L1-026 I Love GPLT
- Linux之poll与select20160619