lgb文档学习
1.L1和l2损失是什么意思?



相较于MSE,MAE有个优点,那就是MAE对离群值不那么敏感,可以更好地拟合线性,因为MAE计算的是误差y−f(x)的绝对值,对于任意大小的差值,其惩罚都是固定的。
2.参数:
核心参数:
1.objective:
回归应用:用法都是:objective=type
type:
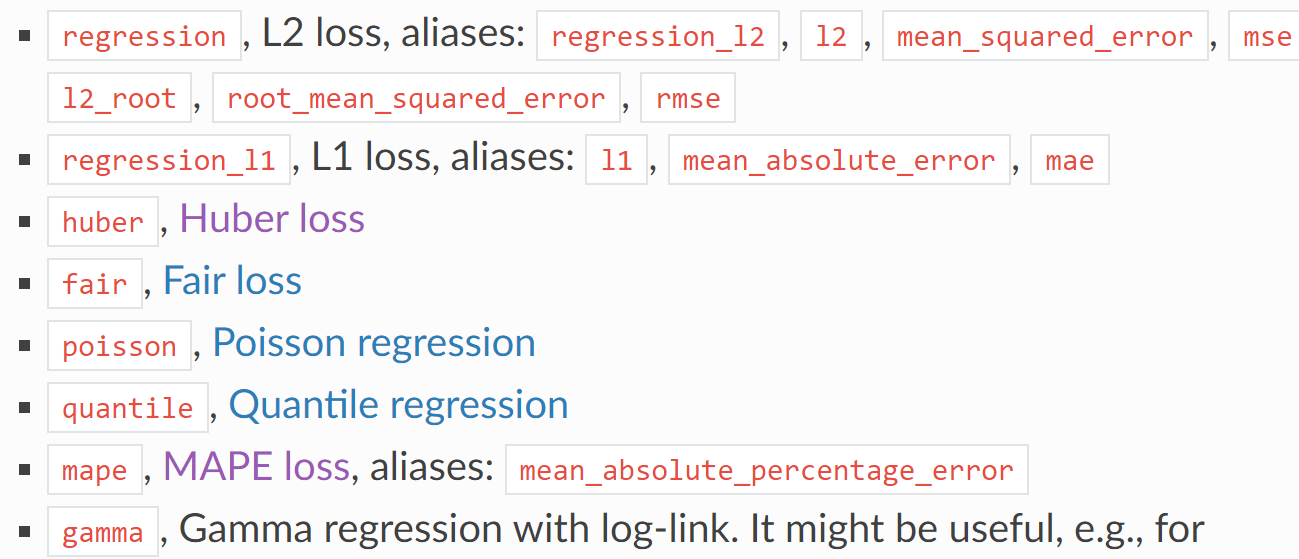
常见的有:
L2(MSE) \L1(MAE)\MAP
二分类应用:

多分类应用:

交叉熵应用:

排序应用:

2.boosting

默认使用gbdt,梯度下降决策树
3.data:

指的是训练数据
4.valid:

指的是验证集(测试集)的路径或文件,支持多个验证集
5.num_iterations:

迭代次数(增益次数)
6.learning_rate:

必须大于零的收缩率,双精度小数
7.num_leaves:

大于1,一颗树中的叶子的最大个数
8.tree _learner:
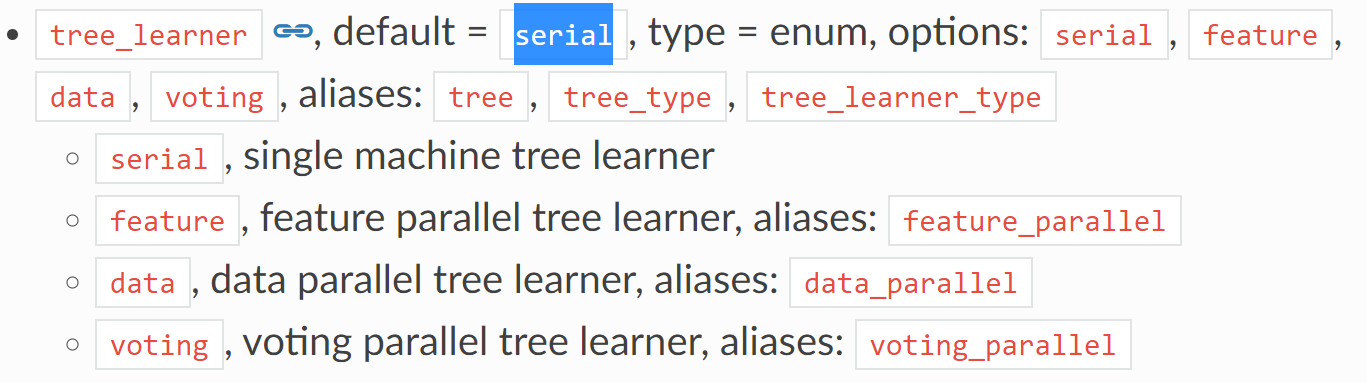
学习器是平行的还是单机学习,是数据平行还是特征平行
9.num_threads

线程数目
10.device_type

建立GPU支持后可以用GPU跑
11.seed

一般都是用random_state,可以时间点。实现每次运行程序划分的训练集和测试集都是同一个
使用控制参数:
1. force_col_wise:

特征非常多,线程数目特别多才会推荐使用
2.histogram_pool_size:

设置直方图的最大缓存数,<0代表没有限制
3.max_depth:

设置最大深度防止过拟合,<=0代表没有限制
4.min_data_in_leaf:

设置一个叶子的最小数据量
5.bagging_fraction:

小部分装袋:防止过拟合和加快训练
6.pos_bagging_fraction

用于二分类问题
7.neg_bagging_fraction

(0,1] 只能用于二分类
8.bagging_freq

每k 此迭代执行一次bagging 随机选择bagging_fraction*100%的数据用于下一次迭代
9.bagging_seed
用于固定打包时间
10.feature_fraction

在训练每棵树前 随机选择feature_fraction*100%的特征,值大小为(0,1]
11.feature_fraction_bynode

在每棵树节点随机选择一个特征子集
12.feature_fraction_seed

用于固定每次的抽取的部分特征
13.extra_trees

使用极度随机的树
14.extra_seed

固定extra_trees的时间
15.early_stopping_round

如果在到达设置的提前停止轮内,验证集的某个评价指标没有提高,训练就会停止.,否则继续训练
16.first_metric_only

17.max_delta_step:

用于限制最大叶子输出
18.
lambda_l1:L1正则项
lambda_l2:L2正则项

19.linear_lambda:

适用于线性回归树
20.min_gain_to_split:

执行分割的最小增益,可用于加速训练
21.drop_rate:
[0,1]

只适用于dart模式下的 丢弃先前的树
22.max_drop

在一次增益迭代中丢弃的最大数目,适用于dart模式
23.skip_drop
取值[0,1],
设置在dart模式下跳过dropout的概率
24.xgboost_dart_mode

设置是否采用xgboost里的dart模块
25.uniform_drop

随机均衡丢弃
26.
drop_seed:

确定选择丢弃模型的时间
goss模型:
27.
top_rate

大梯度数据的保存概率
28.
other_rate:

小梯度数据的保存概率
29.
min_data_per_group
每种类别组的最小数据量的数据

30.max_cat_threshold

为类别特征设置限制分割点数量
类别型特征
类别型特征(Categorical Feature)主要是指只在有限选项内取值的特征。例如性别(男、女)、成绩等级(A、B、C)等。通常以字符串形式输入,除了决策树等少数模型能直接处理字符串形式的输入,逻辑回归、支持向量机等模型的输入必须是数值型特征才能正确工作。
31.cat-l2

类别分割中的正则项
32.cat_smooth

可以降低类别特征中的噪声,尤其是小样本。
33.max_cat_to_onehot

34.top_k

仅仅适用于 voting tree learner
35.monotone_constraints

单调特征
36.monotone_constraints_method

37.monotone_penalty:单调惩罚

38.verbosity

一般就是默认选1,显示信息
39.max_bin

将被分桶的特征值的最大分桶数量
40 max_bin_by_feature:

每个特征的最大分箱数量
41.min_data_in_bin

避免一箱一数据,防止过拟合
42.bin_construct_sample_cnt

被采样用于创建特征离散箱的数据数量
loading data directly from text file
直接从testfile中载入数据
43.label_column:

用于指定标签列
44.weight_column:
用于指定权重列
45.group_column:

46.ignore_column

47.catagorical_feature

规定一些列是类别特征
Predict Parameters3
48.start_iteration_predict:

49.num_iteration_predict

50.predict_raw_score:
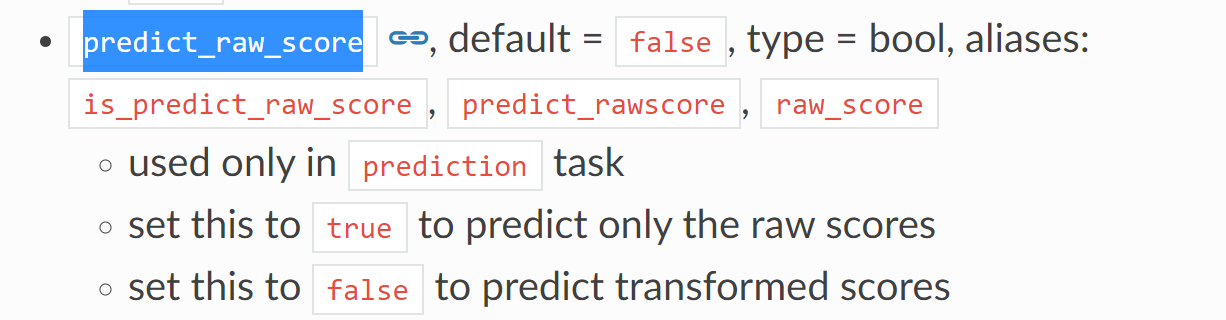
布尔型,=True是只预测初始得分
51 .predict_leaf_index:
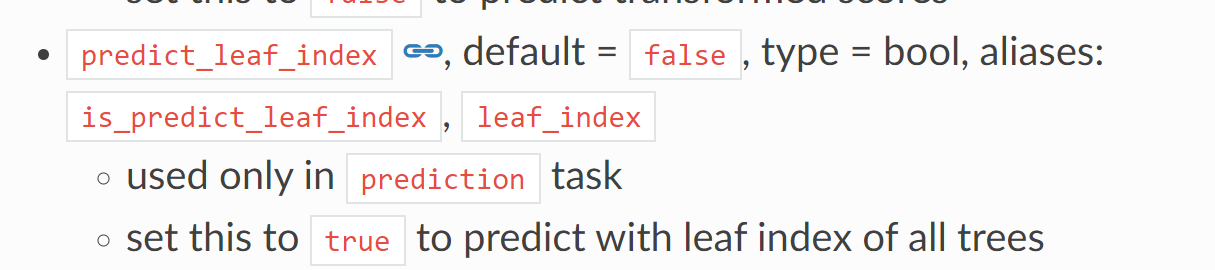
52.pred_early_stop:

仅使用于分类和排序应用
==true会使用early-stopping来加速预测,可能会影响精度
53.pred_early_stop_margin:

在预测中边界的阈值
54.
最新文章
- IIS7.0发布Web服务-0001
- 复选框(checkox)全选、全不选、反选、获得选中项值的用例
- phpstorm git no changes detected
- django--静态文件(九)
- save()、saveOrUpdate()、merge()的区别
- Android 利用xUtils框架实现对sqllite的增删改查
- 基于选择重传ARQ传输协议的数据重传机制方案设计
- callable object与新增的function相关 C++11中万能的可调用类型声明std::function<...>
- Properties vs. Attributes
- BZOJ 4052 Magical GCD
- FreeCodeCamp:Truncate a string
- Aptana Studio 3 官方汉化包汉化
- php Smarty模板引擎配置与测试
- [Shoi2007]Vote 善意的投票
- ultraEdit软件比较两个文件内容的不同处
- Node querystring
- KKT条件原理
- UI设计教程学习分享:APP布局
- JPA(四):EntityManager
- SQL 之 查询操作重复记录
热门文章
- java annotation(如何创建新的注解)小结
- 登录他人mysql
- 第15周作业--JDBC连接数据库
- 【OBS Studio】使用 VLC 视频源播放视频报错:Unhandled exception: c0000005
- laravel Auth的使用
- [*]Quadratic Residual Networks: A New Class of Neural Networks for Solving Forward and Inverse Problems in Physics Involving PDEs
- hdrp gpu instance MPB不生效问题
- Qt事件处理的几种方式
- Visual Studio常用的宏
- Centos 7.5 MySql的安装和配置