ffuf 基础食用指南
2024-10-20 21:00:23
PS:
1. 下文出现的某些字典 有可能是因为摆出效果 我自己瞎搞得字典
2. 分享一些好的工具
3. 其实Wfuzz也很好用的
4. 很早之前就在语雀写过Wfuzz和ffuf的笔记 但是一直没有公开..
5. Master: Muxue
简介
一款高效的FUZZ工具.....
安装
1. go get -u github.com/ffuf/ffuf
2. apt install ffuf
3. https://github.com/ffuf/ffuf/releases // 可自行下载编译后的 也可以使用源代码进行编译
帮助
-h
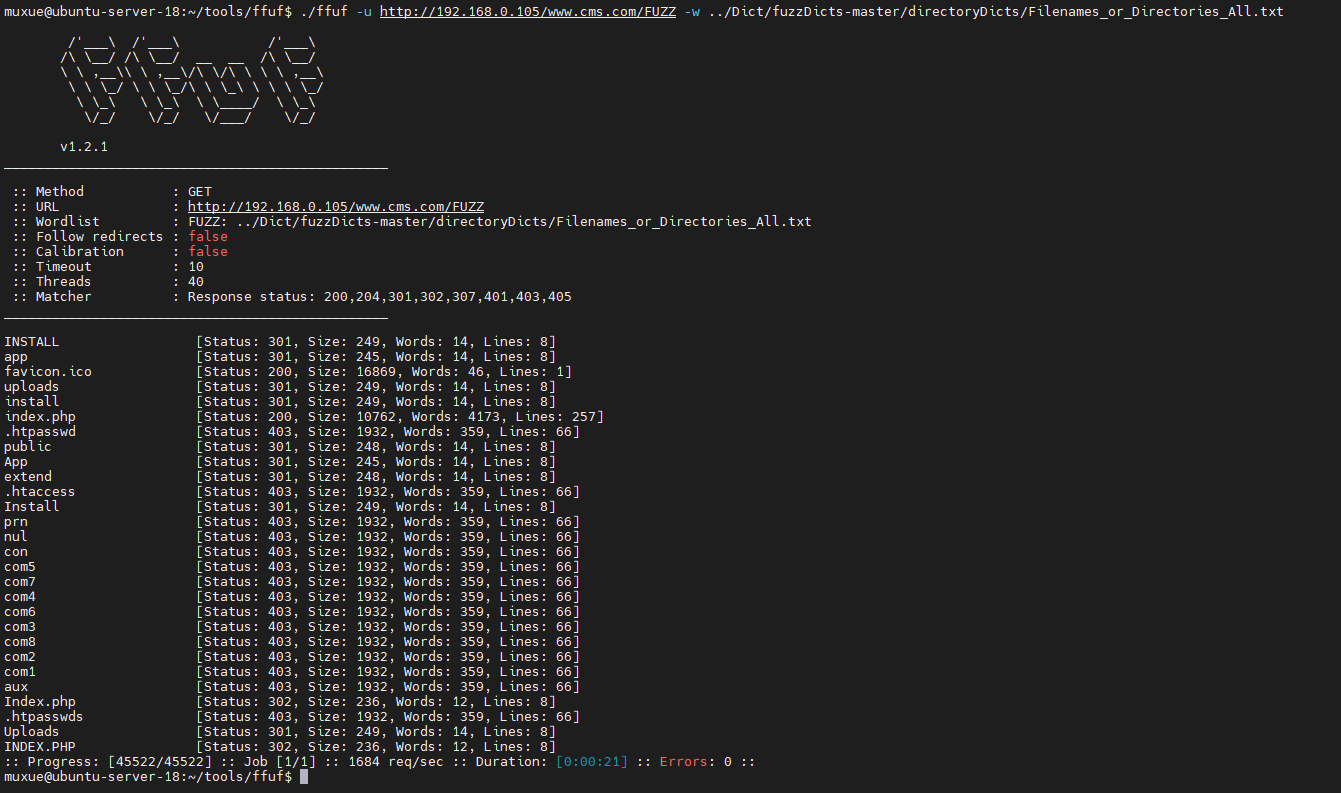
基本攻击
就是-u设置目标 ,-w进行设置字典
./ffuf -u host/FUZZ -w dict.txt
这里我以Fuzz目录来做演示
多字典攻击
就是设置多字典
./ffuf --u host/FUZZ1/FUZZ2 -w dict.txt:FUZZ1 -w dict.txt:FUZZ2
也就是一个字典 后面跟一个冒号 后面再跟一个标识
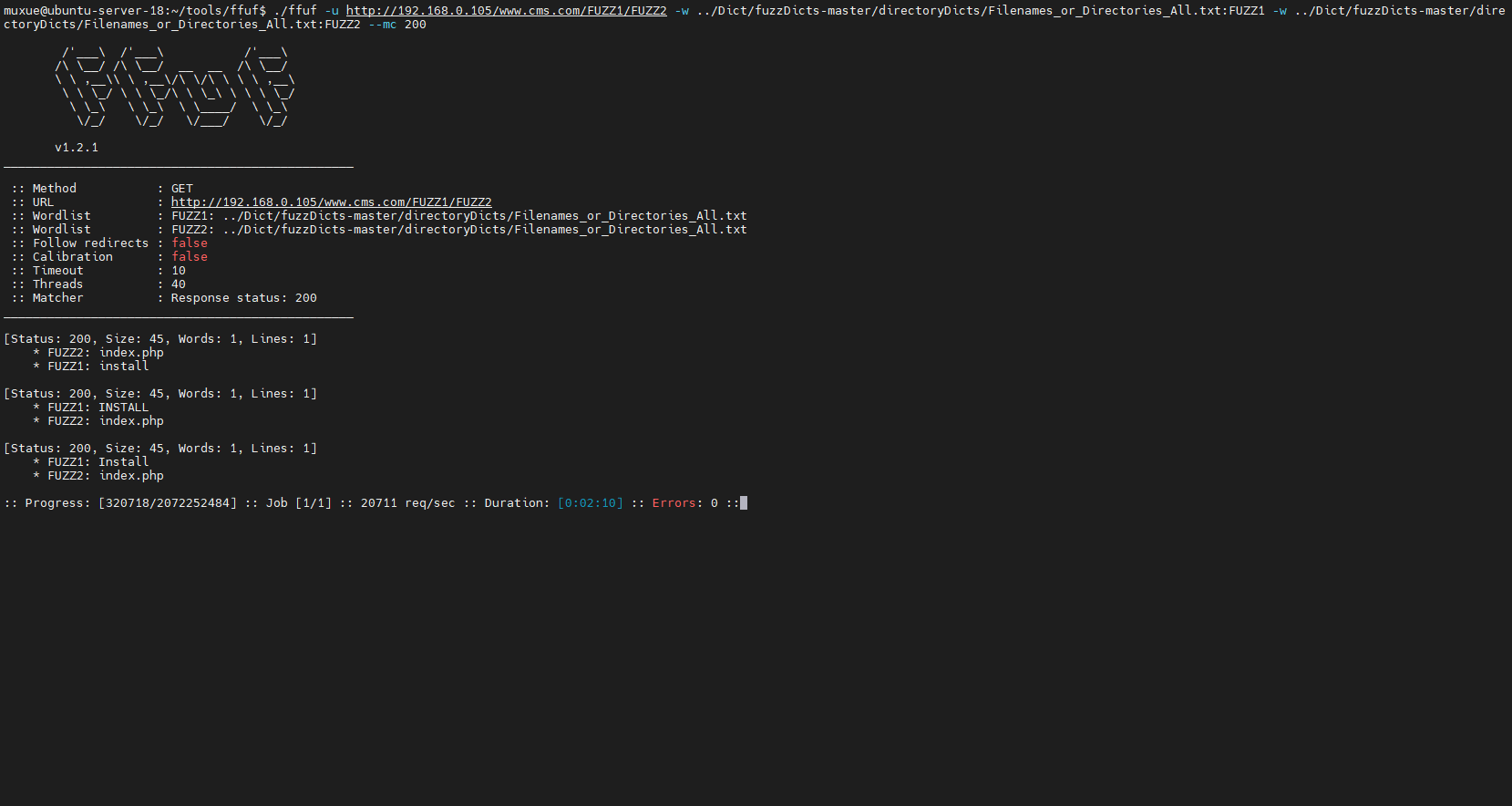
这里-mc的作用一会再说 其实细心的人 应该也知道是啥了
添加COOKIE
-b COOKIE_VALUE
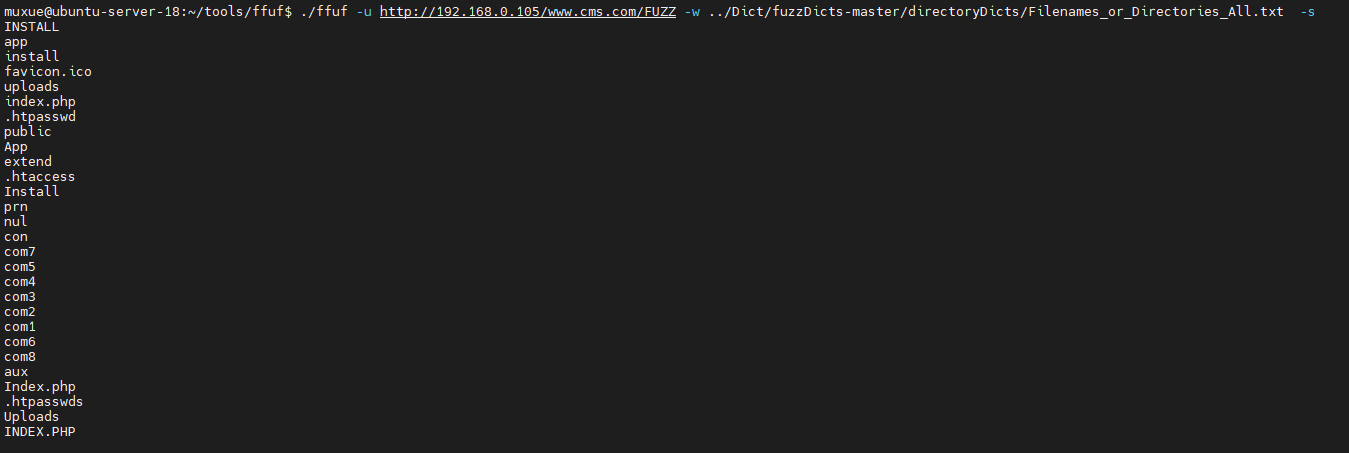
静默模式
-s 其实就是不打印附加信息 只输出结果
指定拓展名
-e 主要就是拓展FUZZ关键字 每个加个x
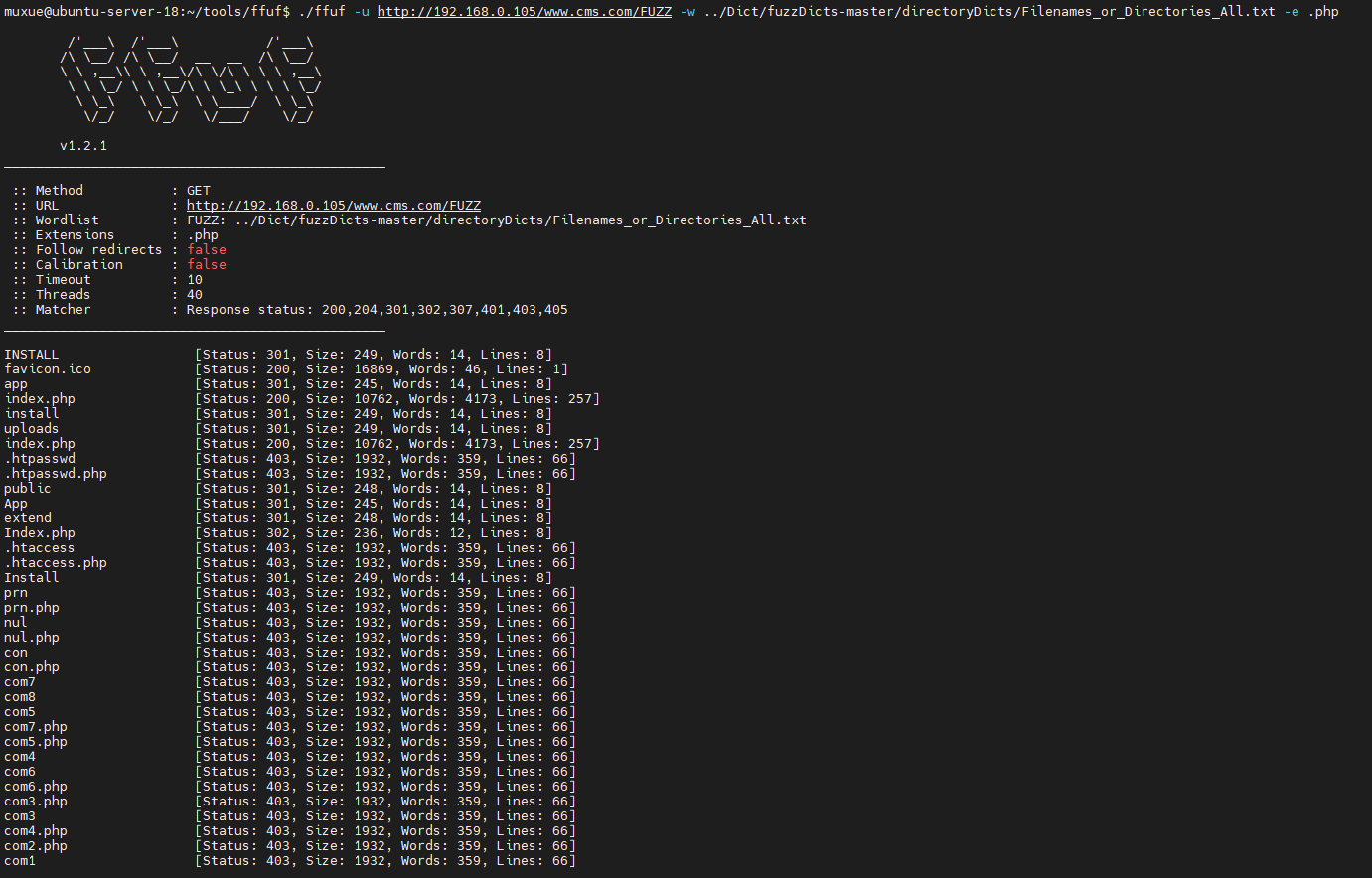
爆破POST请求 (多参数)
主要用到的几个参数
-request原始的http请求文件-request-proto派生http请求 默认为https-mode设置爆破模式 默认为clusterbomb
如若不懂 看下./ffuf -h就可以了
先用BURP抓取原始数据
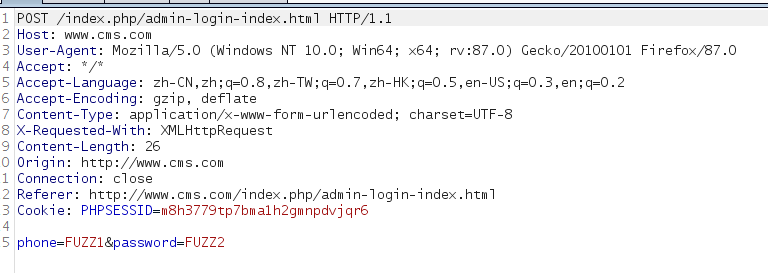
然后进行测试
./ffuf -request test.txt -request-proto http -mode clusterbomb -w user.txt:FUZZ1 -w pass.txt:FUZZ2
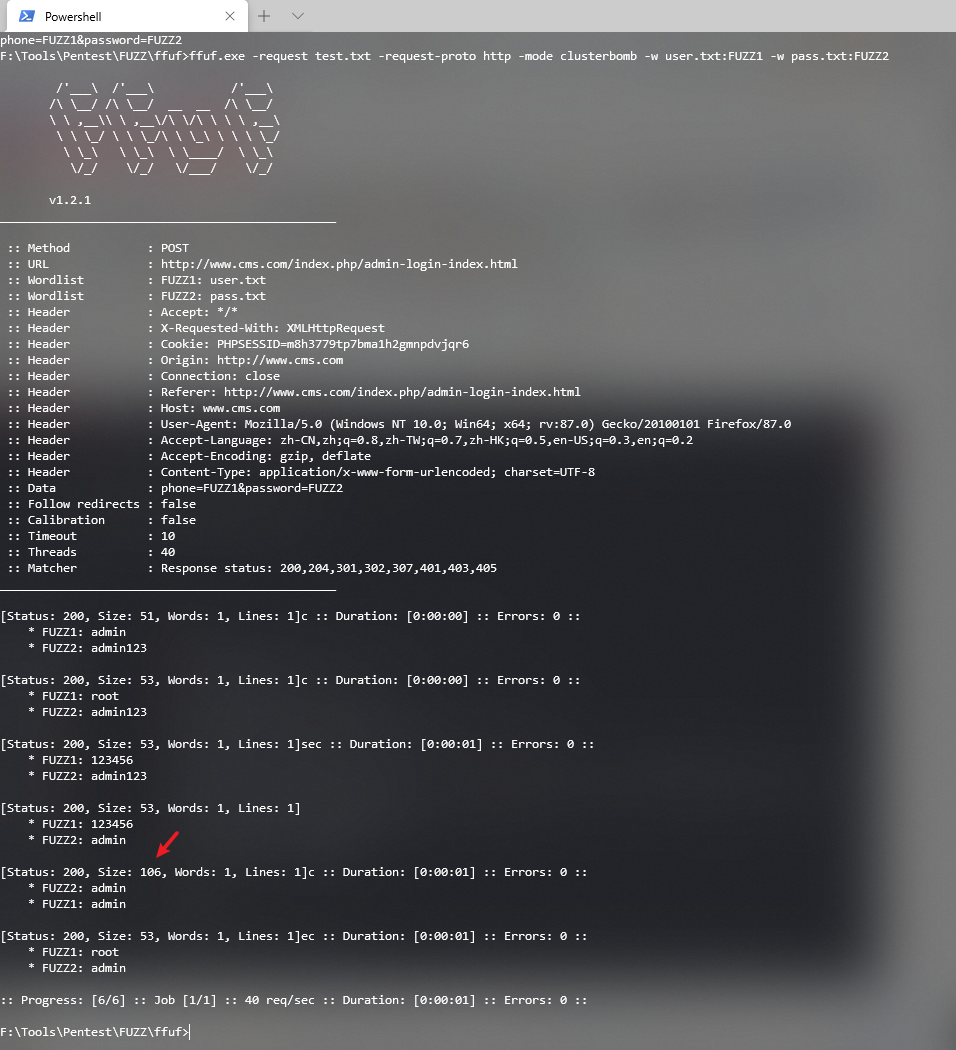
可以看出来size完全不一样,后期我们可以过滤这种没用的size
匹配
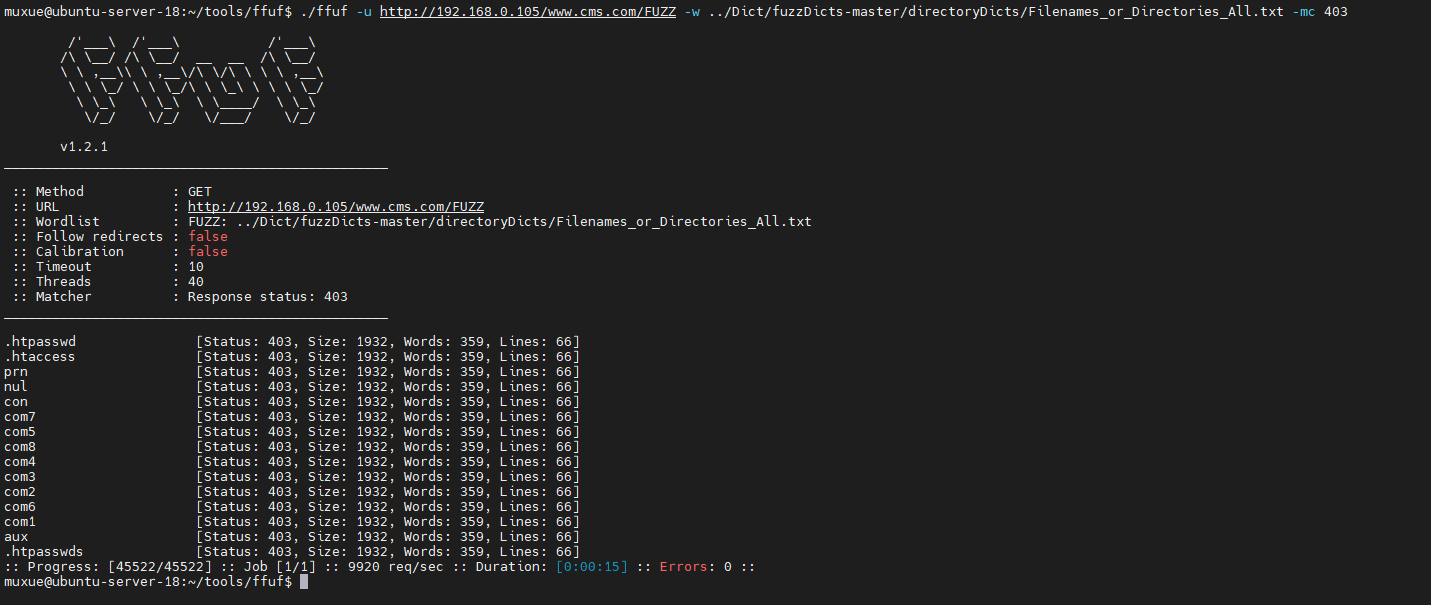
匹配http状态码
-mc status-code
匹配lines
-ml lines
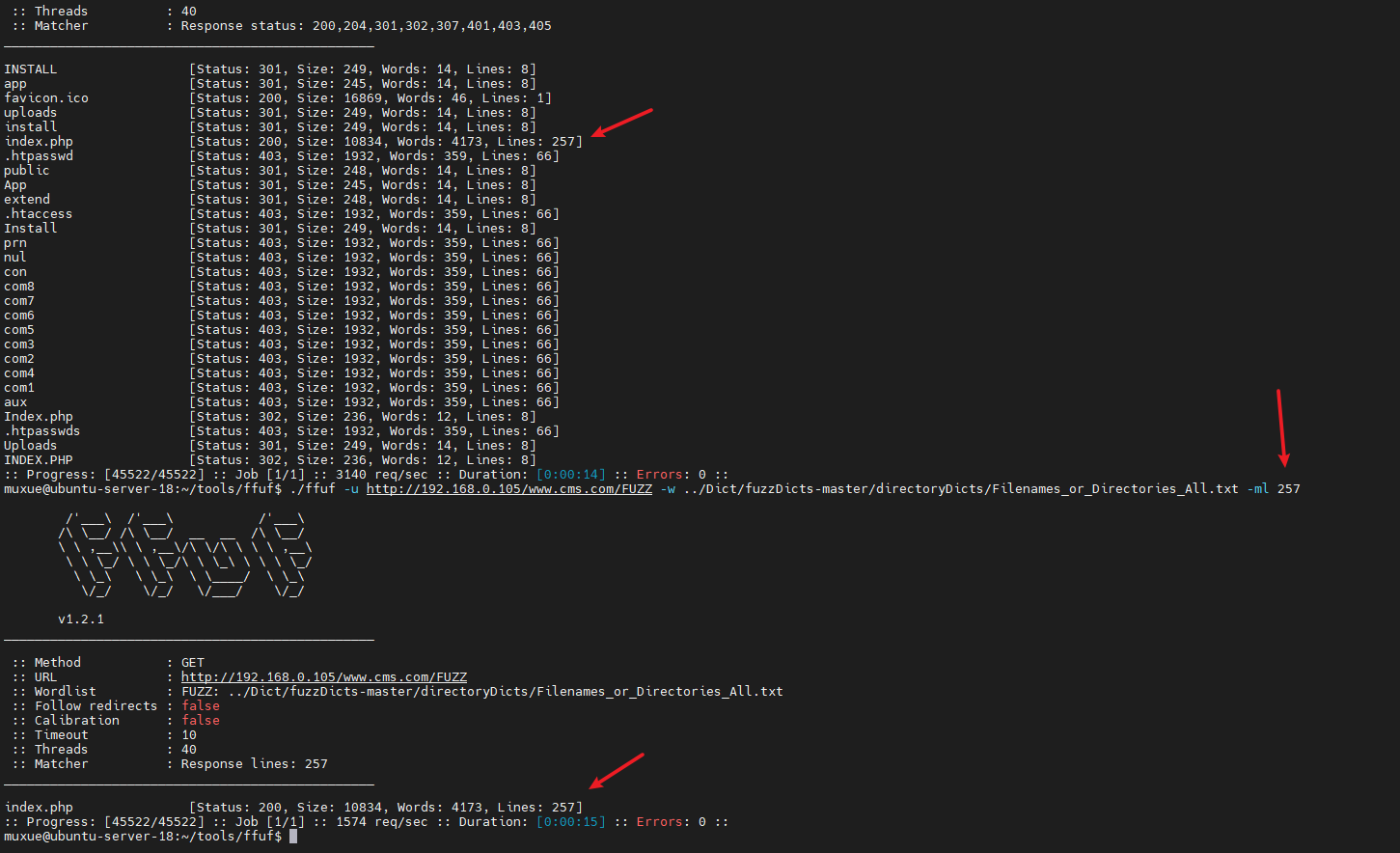
匹配字数
-mw 字数
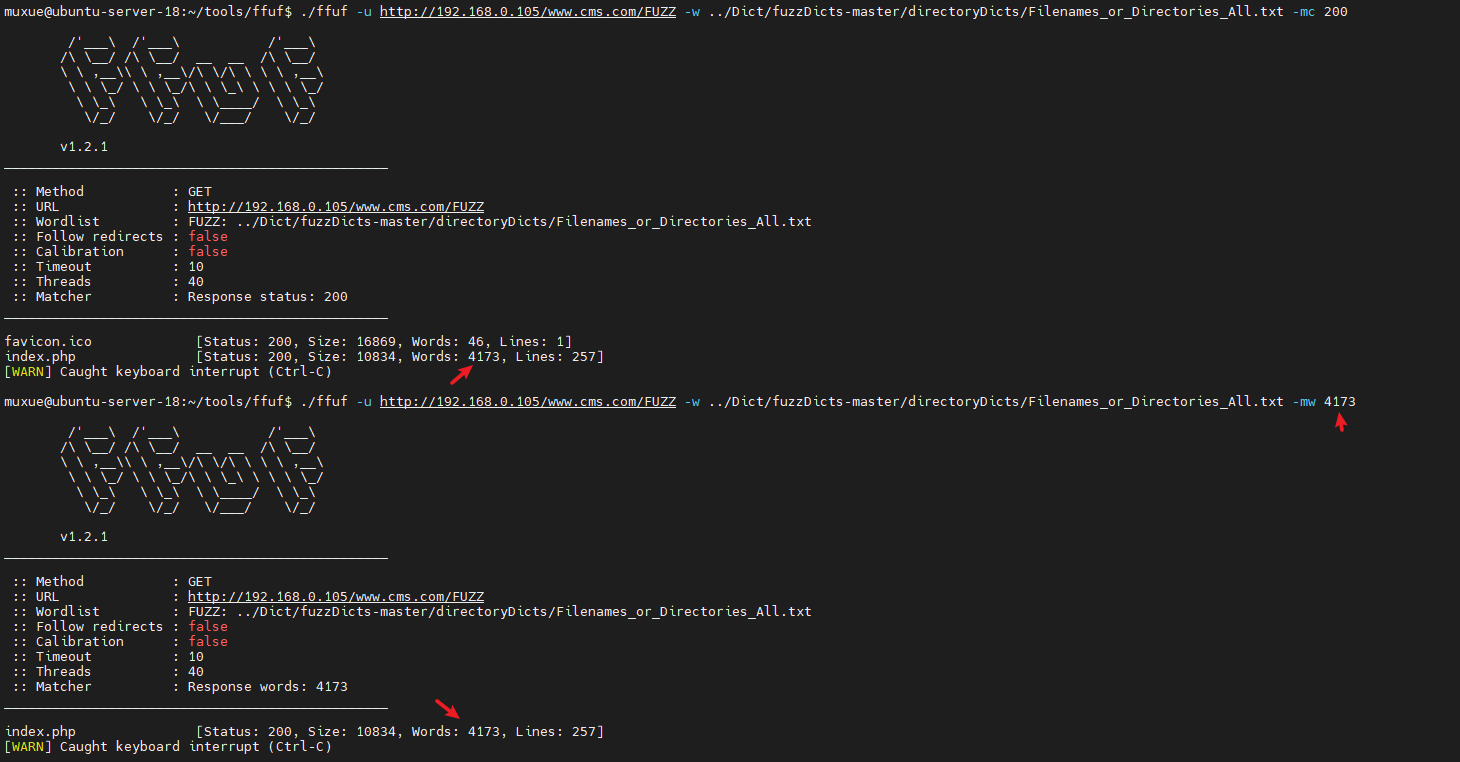
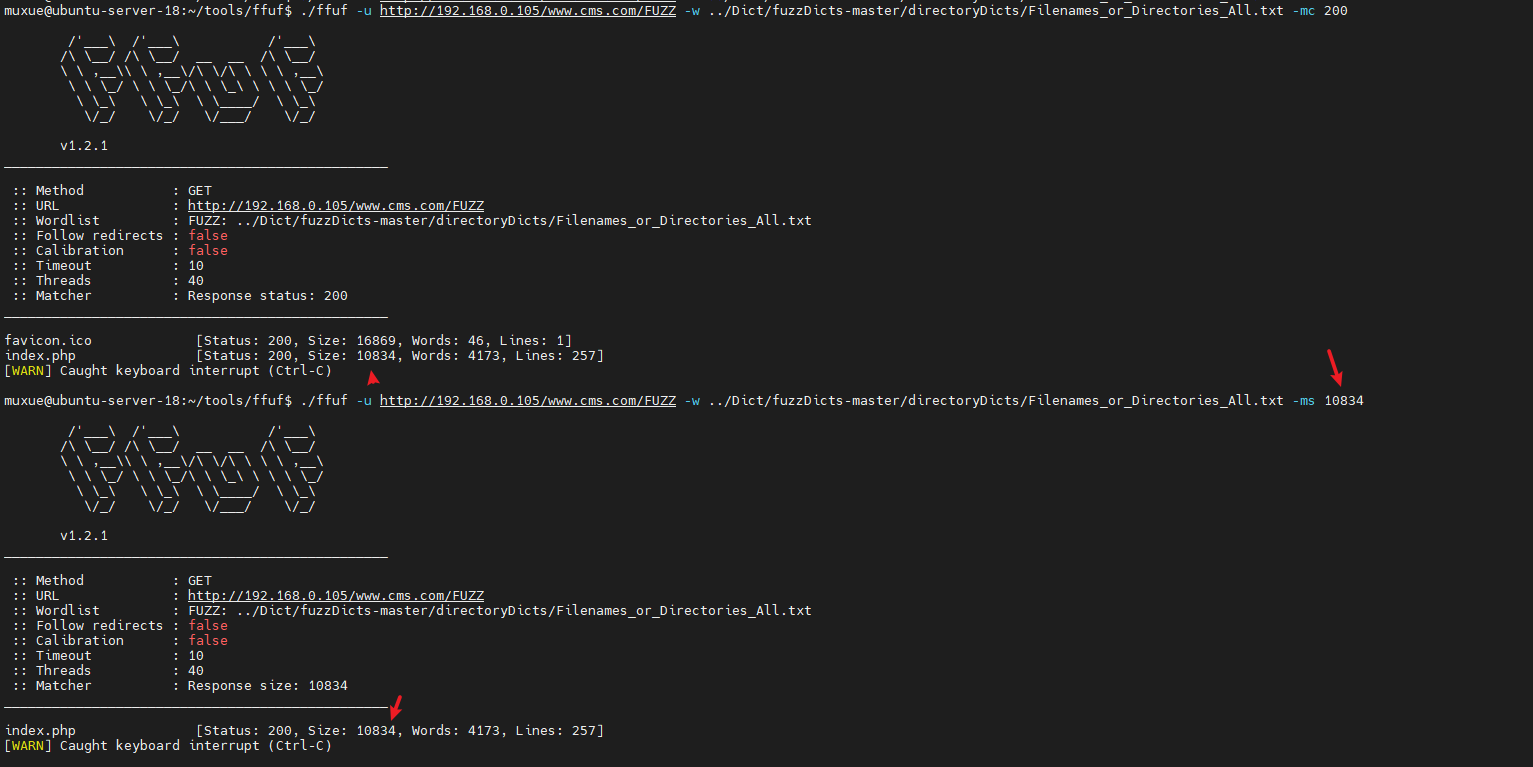
匹配大小
-ms size
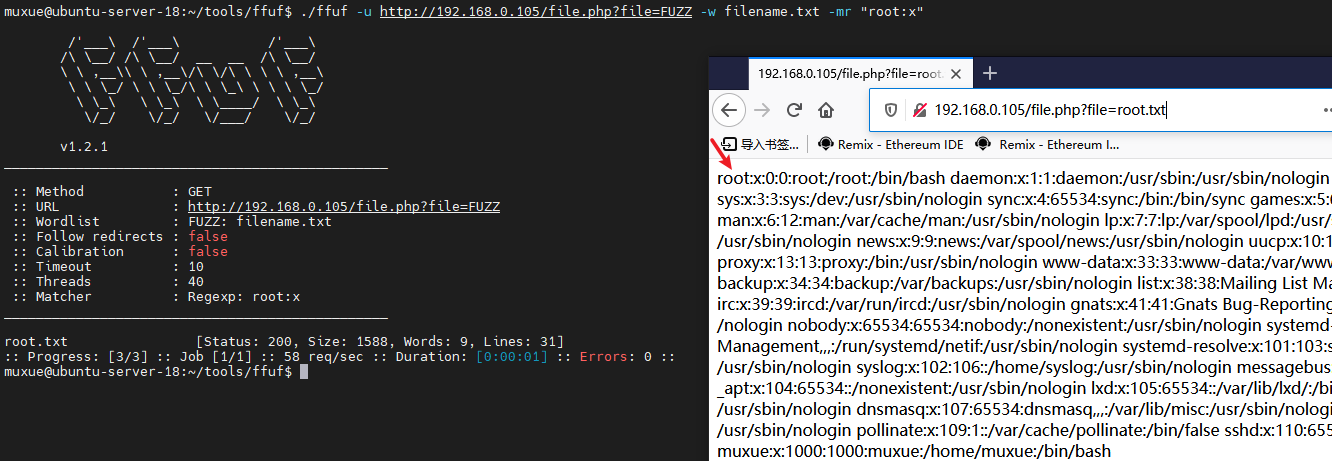
匹配正则
假如我们挖到了一处任意文件读取,可以使用来fuzz
-mr value
筛选
也就是过滤
过滤http状态码
-fc status-code
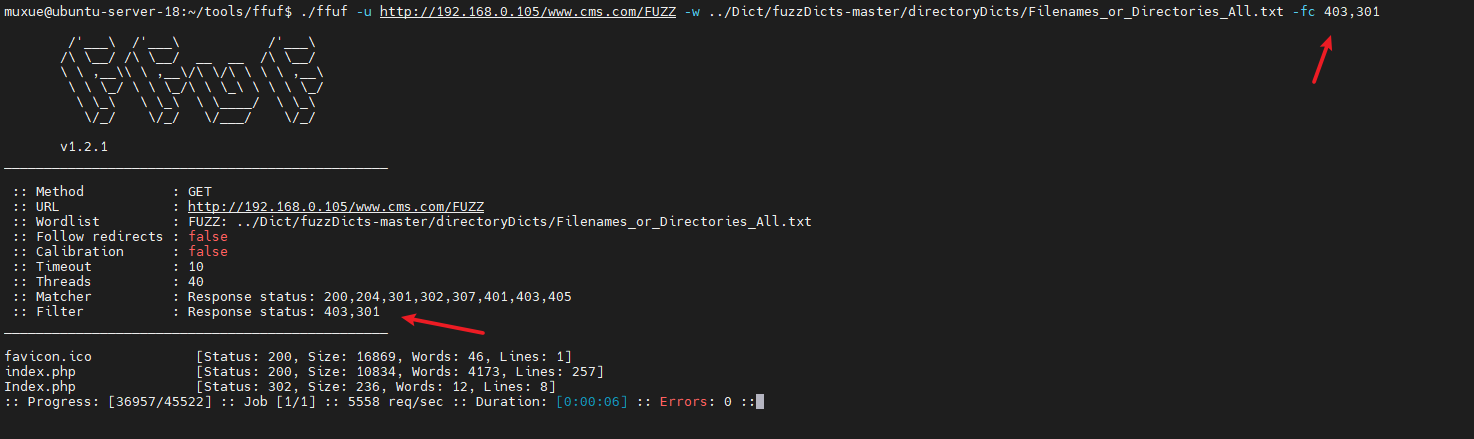
过滤lines
-fl lines
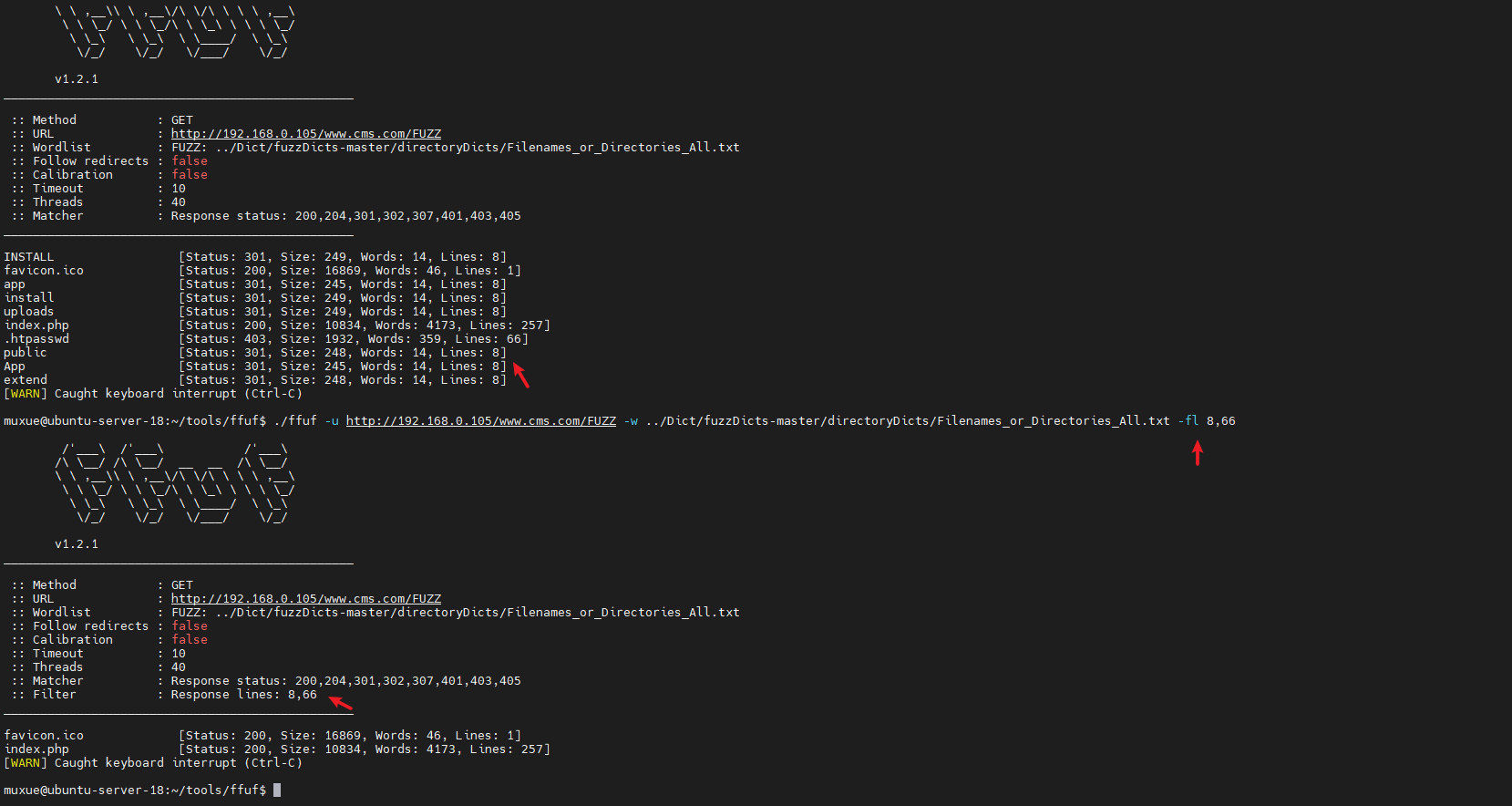
过滤长度
-fs size
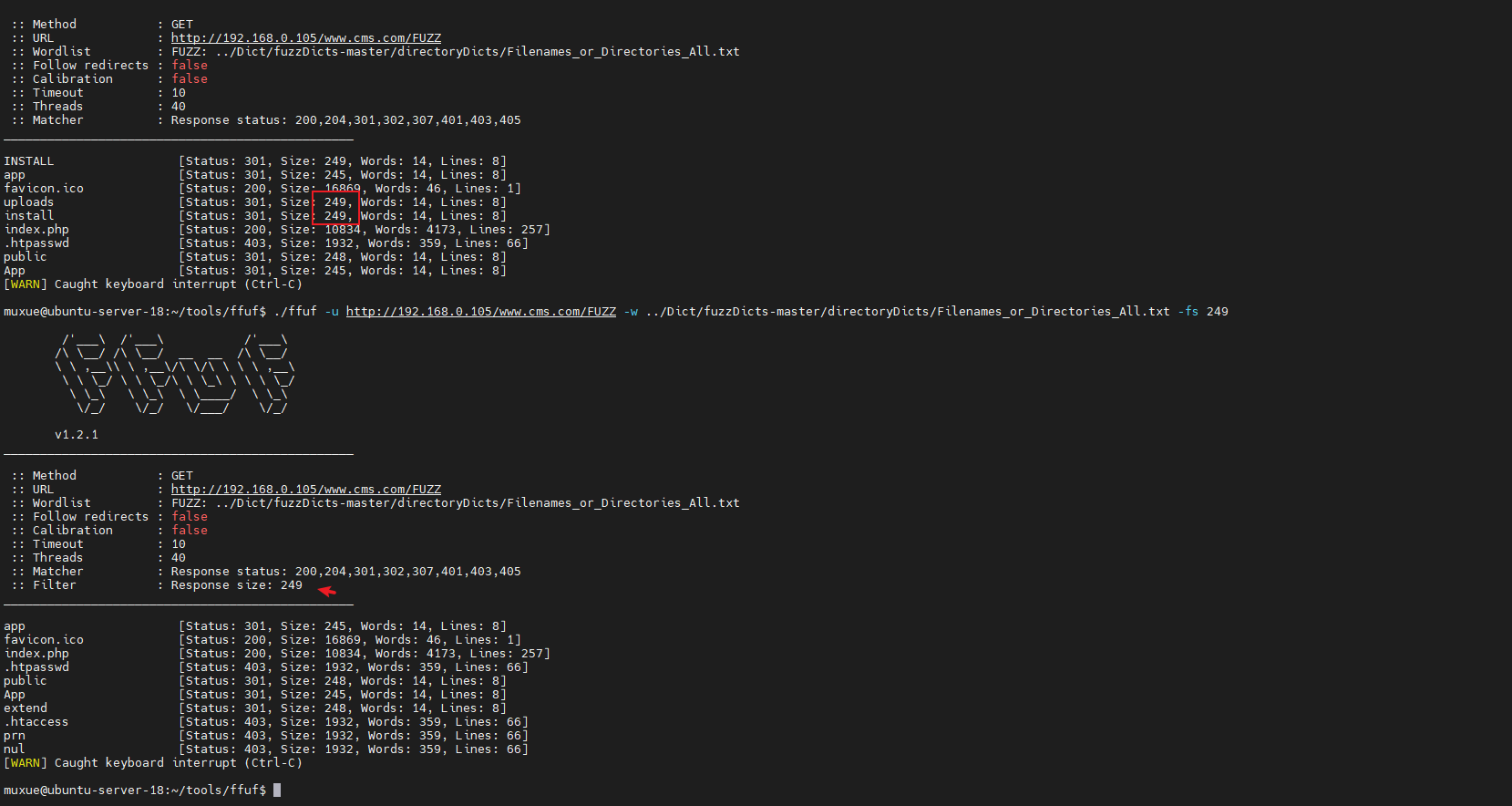
过滤字数
-fw words
不演示了
过滤正则
-fr value
不演示了 就是过滤到带有某某某的 哈哈
常用
颜色
-c 增加颜色
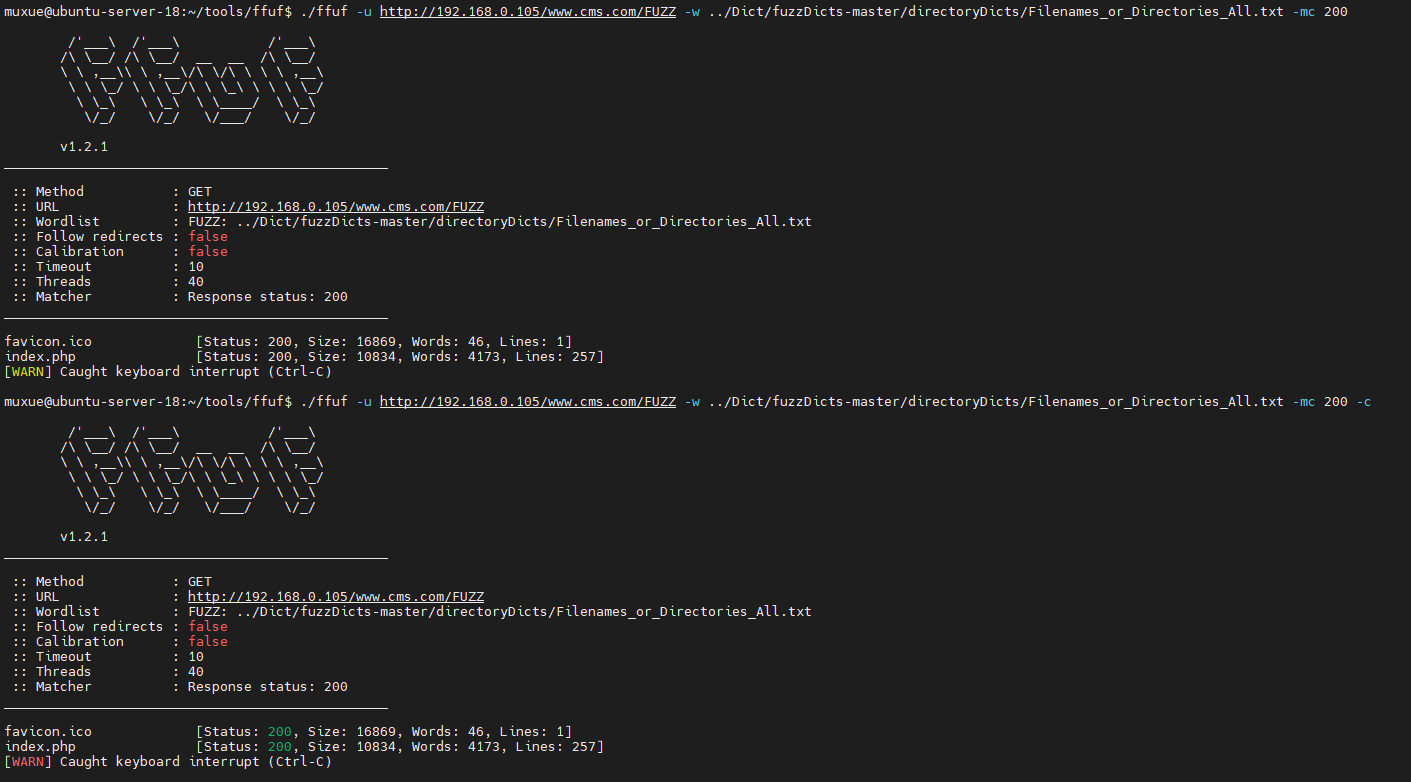
可以明显看见status加了颜色
任务的最大时间
max-time 在有限的时间内完成测试
延迟
-p 延迟多长时间
详细模式
-v
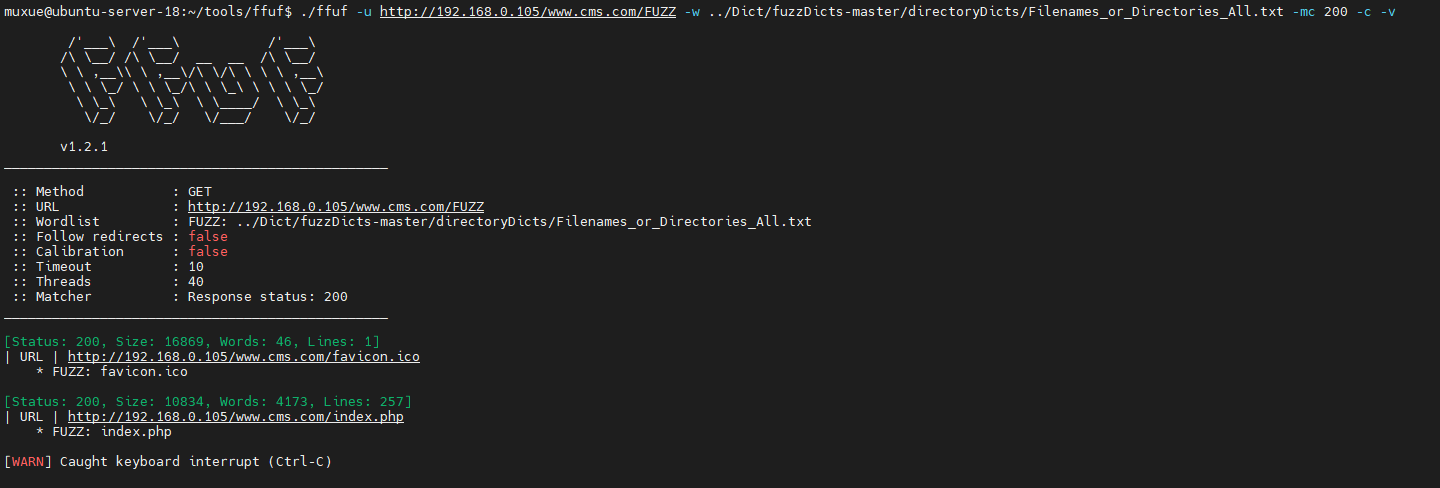
线程
-t
重播代理
-replay-proxy http://127.0.0.1:8080
输出
这个我就简单介绍了
HTML: -o file.html -of html
CSV: -o file.csv -of csv
ALL: -o output/file -of all
只是一个很简单的食用指南,一些玩法大家可以拓展起来
实战例子
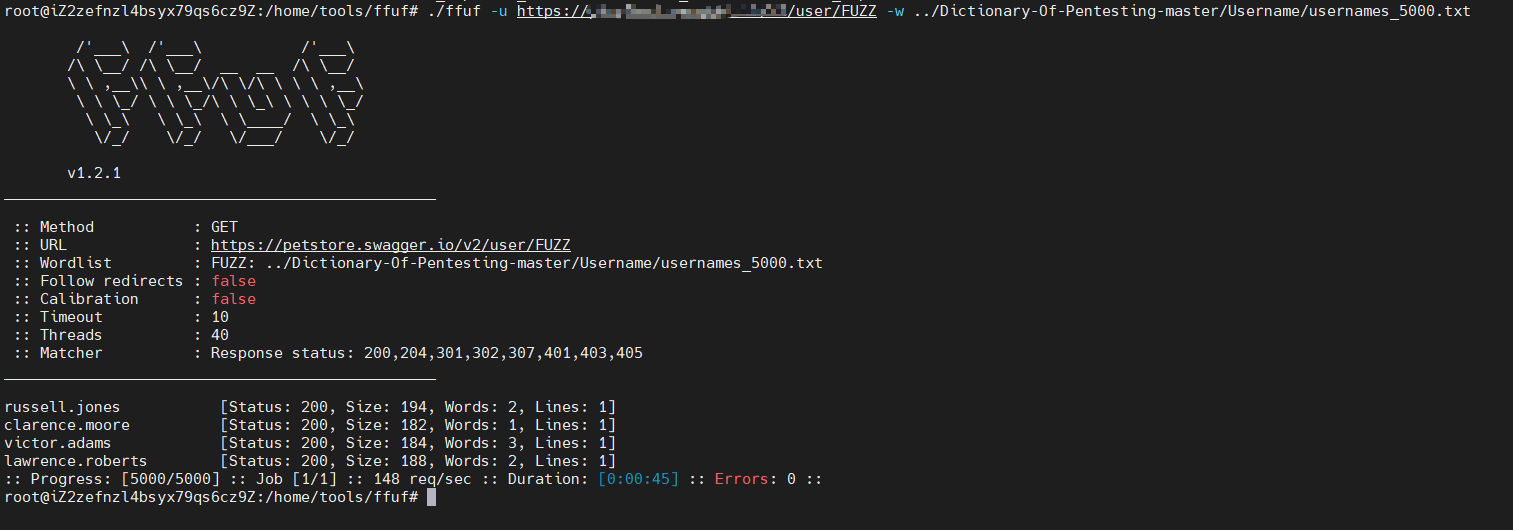
这是一个SRC的子域 查询信息的一个接口 没有认证 可以遍历
最新文章
- c语言文件读写操作总结
- jQuery 2.0.3 源码分析 钩子机制 - 属性操作
- HashSet 浅析示例
- vert.x学习(二),使用Router来定义用户访问路径
- ebtables hook
- ESM335x Linux输出脉冲计数
- shell 题
- Android成长日记-ListView
- HttpURLConnection发送和接受返回值
- centos安装firefox flash插件
- js实现自动登陆的按钮
- 四则运算出题器(c++)
- STL--G - For Fans of Statistics(两个推断条件-二分)
- 字符串比较strcmp
- MyBatis-Generator 逆向工程(生成异常缺少部分的方法)
- javascript学习笔记(四) Number 数字类型
- 移动web端在线观看ppt
- Python:每日一题008
- TP5.x——打印SQL语句
- [PHP] 算法-构建排除当前元素的乘积数组的PHP实现