记录groupby的一次操作
2024-10-09 09:59:09
df = pd.DataFrame({'key1':list('aabba'),
'key2': ['one','two','one','two','one'],
'data1': np.random.randn(5),
'data2': np.random.randn(5)})
df
| data1 | data2 | key1 | key2 | |
|---|---|---|---|---|
| 0 | -0.014192 | 2.236780 | a | one |
| 1 | -0.028981 | 0.507988 | a | two |
| 2 | -1.168170 | -0.818003 | b | one |
| 3 | 0.207849 | 0.755156 | b | two |
| 4 | -0.457174 | -1.407547 | a | one |
g=df.groupby(["key1"])
g.head(4)
| data1 | data2 | key1 | key2 | |
|---|---|---|---|---|
| 0 | -0.014192 | 2.236780 | a | one |
| 1 | -0.028981 | 0.507988 | a | two |
| 2 | -1.168170 | -0.818003 | b | one |
| 3 | 0.207849 | 0.755156 | b | two |
g['data1'].head(2)
0 -0.014192
1 -0.028981
2 -1.168170
3 0.207849
Name: data1, dtype: float64
feature_bag = g['data1'].apply(lambda x:set(x)).reset_index()
feature_bag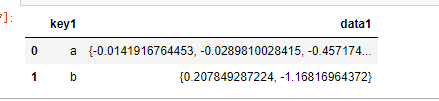
前面的情况比较好了解,groupby返回的是一个groupby对象。它实际上还没有进行任何计算,只是含有一些有分组键的中间数据而已。
因此输出g的时候,没有变化,抽取其中一列也和直接对df操作并没有什么区别。
但是做操作:feature_bag = g['data1'].apply(lambda x:set(x)).reset_index()。
做集合的时候,是以groupby()的key1的键值作为集合的生成判断标准的。
最新文章
- ssh 登录慢?
- css控制段落
- c语言1
- increadbuild重装
- bootshrap会改变IE浏览器滚动条样式
- 基于opencv 的图片模糊判断代码
- CentOS下使用cmake编译安装mysql
- InstallShield Clone dialog
- AD,Group
- WPF MVVM 用户控件完成分页
- 万科北京区域V-learn发布 系V-LINK产品系中首批产品
- Linux UDEV和为MySQL InnoDB共享表空间配置裸设备
- CentOS6.5 下在Nginx中添加SSL证书以支持HTTPS协议访问
- mysql数据库事务详细剖析
- EasyUI datagrid 的多条件查询
- 【vue】vue +element 实现批量删除
- Kafka基本架构及原理
- 小游戏:HelloColor
- mysql导入sql脚本
- python字典去重脚本