3.2-3.3 Hive中常见的数据压缩
2024-10-21 03:53:41
一、数据压缩
1、
数据压缩
数据量小
*本地磁盘,IO
*减少网络IO Hadoop作业通常是IO绑定的;
压缩减少了跨网络传输的数据的大小;
通过简单地启用压缩,可以提高总体作业性能;
要压缩的数据必须支持可分割性;
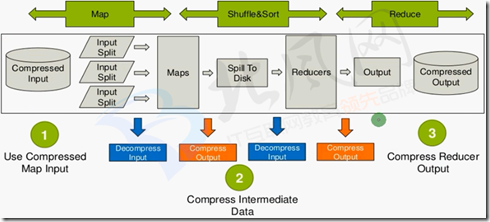
2、什么时候压缩?
1、Use Compressed Map Input
· Mapreduce jobs read input from HDFS
· Compress if input data is large. This will reduce disk read cost.
· Compress with splittable algorithms like Bzip2
· Or use compression with splittable file structures such as Sequence Files, RC Files etc. 2、Compress Intermediate Data
·Map output is written to disk(spill)and transferred accross the network
·Always use compression toreduce both disk write,and network transfer load
·Beneficial in performace point of view even if input and output is uncompressed
·Use faster codecs such as Snappy,LZO 3、Compress Reducer Output
.Mapreduce output used for both archiving or chaining mapreduce jobs
·Use compression to reduce disk space for archiving
·Compression is also beneficial for chaining jobsespecially with limited disk throughput resource.
·Use compression methods with higher compress ratio to save more disk space
3、Supported Codecs in Hadoop
Zlib→org.apache.hadoop.io.compress.DefaultCodec
Gzip →org.apache.hadoop.io.compress.Gzipcodec
Bzip2→org.apache.hadoop.io.compress.BZip2Codec
Lzo→com.hadoop.compression.1zo.LzoCodec
Lz4→org.apache.hadoop.io.compress.Lz4Codec
Snappy→org.apache.hadoop.io.compress.Snappycodec
4、Compression in MapReduce
#####
Compressed Input Usage:
File format is auto recognized with extension.
Codec must be defined in core-site.xml. #####
Compress
Intermediate Data
(Map Output):
mapreduce.map.output.compress=True;
mapreduce.map.output.compress.codec=CodecName; #####
Compress Job Output (Reducer Output):
mapreduce.output.fileoutputformat.compress=True;
mapreduce.output.fileoutputformat.compress.codec=CodecName;
5、Compression in Hive
#####
Compressed
Input Usage:
Can be defined in table definition
STORED AS INPUTFORMAT
\"com.hadoop.mapred.DeprecatedLzoText Input Format\" #####
Compress Intermediate Data (Map Output):
SET hive. exec. compress. intermediate=True;
SET mapred. map. output. compression. codec=CodecName;
SET mapred. map. output. compression. type=BLOCK/RECORD;
Use faster codecs such as Snappy, Lzo, LZ4
Useful for chained mapreduce jobs with lots of intermediate data such as joins. #####
Compress Job Output (Reducer Output):
SET hive.exec.compress.output=True;
SET mapred.output.compression.codec=CodecName;
SET mapred.output.compression.type=BLOCK/RECORD;
二、snappy
1、简介
在hadoop集群中snappy是一种比较好的压缩工具,相对gzip压缩速度和解压速度有很大的优势,
而且相对节省cpu资源,但压缩率不及gzip。它们各有各的用途。 Snappy是用C++开发的压缩和解压缩开发包,旨在提供高速压缩速度和合理的压缩率。Snappy比zlib更快,但文件相对要大20%到100%。
在64位模式的Core i7处理器上,可达每秒250~500兆的压缩速度。 Snappy的前身是Zippy。虽然只是一个数据压缩库,它却被Google用于许多内部项目程,其中就包括BigTable,MapReduce和RPC。
Google宣称它在这个库本身及其算法做了数据处理速度上的优化,作为代价,并没有考虑输出大小以及和其他类似工具的兼容性问题。
Snappy特地为64位x86处理器做了优化,在单个Intel Core i7处理器内核上能够达到至少每秒250MB的压缩速率和每秒500MB的解压速率。 如果允许损失一些压缩率的话,那么可以达到更高的压缩速度,虽然生成的压缩文件可能会比其他库的要大上20%至100%,但是,
相比其他的压缩库,Snappy却能够在特定的压缩率下拥有惊人的压缩速度,“压缩普通文本文件的速度是其他库的1.5-1.7倍,
HTML能达到2-4倍,但是对于JPEG、PNG以及其他的已压缩的数据,压缩速度不会有明显改善”。
2、使得Snappy类库对Hadoop可用
此处使用的是编译好的库文件;
#这里是编译好的库文件,在压缩包里,先解压缩
[root@hadoop-senior softwares]# mkdir 2.5.0-native-snappy [root@hadoop-senior softwares]# tar zxf 2.5.0-native-snappy.tar.gz -C 2.5.0-native-snappy [root@hadoop-senior softwares]# cd 2.5.0-native-snappy [root@hadoop-senior 2.5.0-native-snappy]# ls
libhadoop.a libhadoop.so libhadooputils.a libhdfs.so libsnappy.a libsnappy.so libsnappy.so.1.2.0
libhadooppipes.a libhadoop.so.1.0.0 libhdfs.a libhdfs.so.0.0.0 libsnappy.la libsnappy.so.1 #替换hadoop的安装
[root@hadoop-senior lib]# pwd
/opt/modules/hadoop-2.5.0/lib [root@hadoop-senior lib]# mv native/ 250-native [root@hadoop-senior lib]# mkdir native [root@hadoop-senior lib]# ls
250-native native native-bak [root@hadoop-senior lib]# cp /opt/softwares/2.5.0-native-snappy/* ./native/ [root@hadoop-senior lib]# ls native
libhadoop.a libhadoop.so libhadooputils.a libhdfs.so libsnappy.a libsnappy.so libsnappy.so.1.2.0
libhadooppipes.a libhadoop.so.1.0.0 libhdfs.a libhdfs.so.0.0.0 libsnappy.la libsnappy.so.1 #检查
[root@hadoop-senior hadoop-2.5.0]# bin/hadoop checknative
19/04/25 09:59:51 INFO bzip2.Bzip2Factory: Successfully loaded & initialized native-bzip2 library system-native
19/04/25 09:59:51 INFO zlib.ZlibFactory: Successfully loaded & initialized native-zlib library
Native library checking:
hadoop: true /opt/modules/hadoop-2.5.0/lib/native/libhadoop.so
zlib: true /lib64/libz.so.1
snappy: true /opt/modules/hadoop-2.5.0/lib/native/libsnappy.so.1 #snappy已经为true
lz4: true revision:99
bzip2: true /lib64/libbz2.so.1
3、mapreduce压缩测试
#创建测试文件
[root@hadoop-senior hadoop-2.5.0]# bin/hdfs dfs -mkdir -p /user/root/mapreduce/wordcount/input [root@hadoop-senior hadoop-2.5.0]# touch /opt/datas/wc.input [root@hadoop-senior hadoop-2.5.0]# vim !$
hadoop hdfs
hadoop hive
hadoop mapreduce
hadoop hue [root@hadoop-senior hadoop-2.5.0]# bin/hdfs dfs -put /opt/datas/wc.input /user/root/mapreduce/wordcount/input
put: `/user/root/mapreduce/wordcount/input/wc.input': File exists [root@hadoop-senior hadoop-2.5.0]# bin/hdfs dfs -ls -R /user/root/mapreduce/wordcount/input
-rw-r--r-- 1 root supergroup 12 2019-04-08 15:03 /user/root/mapreduce/wordcount/input/wc.input #先不压缩运行MapReduce
[root@hadoop-senior hadoop-2.5.0]# bin/yarn jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.5.0.jar wordcount /user/root/mapreduce/wordcount/input /user/root/mapreduce/wordcount/output #压缩运行MapReduce
[root@hadoop-senior hadoop-2.5.0]# bin/yarn jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.5.0.jar wordcount -Dmapreduce.map.output.compress=true -Dmapreduce.map.output.compress.codec=org.apache.hadoop.io.compress.SnappyCodec /user/root/mapreduce/wordcount/input /user/root/mapreduce/wordcount/output2 #-Dmapreduce.map.output.compress=true :map输出的值要使用压缩;-D是参数
#-Dmapreduce.map.output.compress.codec=org.apache.hadoop.io.compress.SnappyCodec :使用snappy压缩;-D是参数
#由于数据量太小,基本上看不出差别
三、hive配置压缩
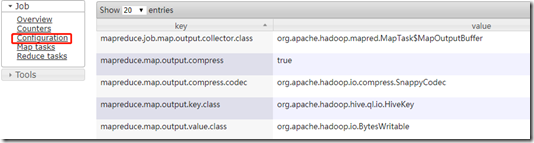
hive (default)> set mapreduce.map.output.compress=true;
hive (default)> set mapreduce.map.output.compress.codec=org.apache.hadoop.io.compress.SnappyCodec;
测试:
在hive中运行一个select会执行MapReduce:
hive (default)> select count(*) from emp;
在web页面的具体job中可以看到此作业使用的配置:
最新文章
- 如何使用git命令添加文件和提交文件
- ES6(一)ECMAscript6介绍
- 【iCore双核心组合是开发板例程】【12个 verilog 中级实验例程发布】
- MySQL中ON DUPLICATE KEY UPDATE使用
- java web 路径 --转载
- git_share
- [CSS] Animating SVG
- J2SE知识点摘记(四)
- 脑波设备mindwave二次开发框架
- 在sqlserver2005/2008中备份数据库,收缩日志文件
- JAVA8新特性(一)
- 十问 JVM
- Java异常处理:给程序罩一层保险
- Python_面向对象_类1
- android-------Java 常问的基础面试题
- 详解CSS3属性前缀(转)
- [转]让程序不触发 Vista/Win7下应用程序兼容性助手弹出 .
- HTTP协议GET和POST的区别
- AD各种布线方法总结
- python处理数据(一)