【撸码caffe 三】 caffe.cpp
2024-10-07 11:58:04
caffe.cpp文件完成对网络模型以及模型配置参数的读入和提取,提供了网络模型训练的入口函数train和对模型的测试入口函数test。文件中使用了很多gflags和glog指令,gflags是google的一个开源的处理命令行参数的库,glog是一个有效的日志记录工具。
补充一点CUDA中查询GPU设备属性的知识:
CUDA C中的cudaGetDeviceProperties函数可以很方便的获取到设备的信息,caffe.cpp中就使用到了这个函数查询设备信息,函数原型是:
- cudaError_t CUDARTAPI cudaGetDeviceProperties(struct cudaDeviceProp *prop, int device);
第二个参数device是从0开始的设备的编号。
第一个参数prop指向的是一个cudaDeviceProp类型的结构。cudaDeviceProp结构中包含了设备的相关属性,下图是 其中的几个属性信息:
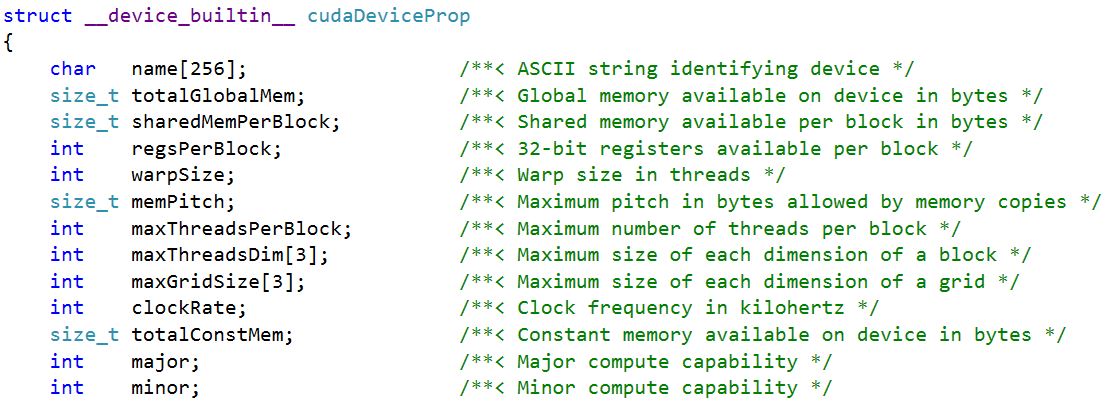
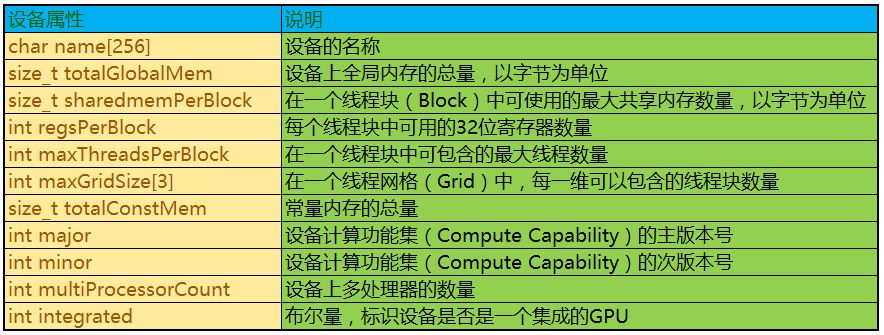
部分属性信息的相关说明如下:
caffe.cpp文件注释:
#ifdef WITH_PYTHON_LAYER
#include "boost/python.hpp"
namespace bp = boost::python;
#endif
#include <gflags/gflags.h>
#include <glog/logging.h>
#include <cstring>
#include <map>
#include <string>
#include <vector>
#include "boost/algorithm/string.hpp"
#include "caffe/caffe.hpp"
#include "caffe/util/signal_handler.h"
using caffe::Blob;
using caffe::Caffe;
using caffe::Net;
using caffe::Layer;
using caffe::Solver;
using caffe::shared_ptr;
using caffe::string;
using caffe::Timer;
using caffe::vector;
using std::ostringstream;
/**********************************************************************
DEFINE_string/int32 是gflags(google的一个开源的处理命令行参数的库)中的宏定义
作用是获取命令行中传入的配置的参数值,它的调用格式是(name,val,txt),其中name
是命令行中的配置项,val是配置项的值,txt是描述信息,如果命令行中没有配置变量的值,
则使用DEFINE中的默认值
**********************************************************************/
DEFINE_string(gpu, "",
"Optional; run in GPU mode on given device IDs separated by ','."
"Use '-gpu all' to run on all available GPUs. The effective training "
"batch size is multiplied by the number of devices.");
DEFINE_string(solver, "",
"The solver definition protocol buffer text file.");
DEFINE_string(model, "",
"The model definition protocol buffer text file.");
DEFINE_string(phase, "",
"Optional; network phase (TRAIN or TEST). Only used for 'time'.");
DEFINE_int32(level, 0,
"Optional; network level.");
DEFINE_string(stage, "",
"Optional; network stages (not to be confused with phase), "
"separated by ','.");
DEFINE_string(snapshot, "",
"Optional; the snapshot solver state to resume training.");
DEFINE_string(weights, "",
"Optional; the pretrained weights to initialize finetuning, "
"separated by ','. Cannot be set simultaneously with snapshot.");
DEFINE_int32(iterations, 50,
"The number of iterations to run.");
DEFINE_string(sigint_effect, "stop",
"Optional; action to take when a SIGINT signal is received: "
"snapshot, stop or none.");
DEFINE_string(sighup_effect, "snapshot",
"Optional; action to take when a SIGHUP signal is received: "
"snapshot, stop or none.");
// A simple registry for caffe commands.
/*声明一个BrewFunction函数指针类型,可以用它来定义一个函数指针
在main函数中通过这个函数指针调用相应的train或test函数
*/
typedef int(*BrewFunction)();
typedef std::map<caffe::string, BrewFunction> BrewMap;
BrewMap g_brew_map;
//在C++宏定义中, \的作用是把内容分行显示; #的作用是把其后的内容转换成字符串
#define RegisterBrewFunction(func) \
namespace {
\
class __Registerer_##func{ \
public: /* NOLINT */ \
__Registerer_##func() {
\
g_brew_map[#func] = &func; \
} \
}; \
__Registerer_##func g_registerer_##func; \
}
/**********************************************************************
在caffe中,BrewFunction作为GetBrewFunction()函数的返回类型,可以是train(),
test(),device_query(),time()这4个函数指针的其中一个,通过传入的name,指向对应
的函数,在train(),test()函数中,可以调用solver类的函数,从而进入到net,进入到网络
中的每一层,运行整个caffe程序
***********************************************************************/
static BrewFunction GetBrewFunction(const caffe::string& name) {
if (g_brew_map.count(name)) { // 判断传入的name是不是train,test,device_query或time中的一种
return g_brew_map[name];
}
else { //对于其他传入值,打印出错误信息---不含有对应的操作
LOG(ERROR) << "Available caffe actions:";
for (BrewMap::iterator it = g_brew_map.begin();
it != g_brew_map.end(); ++it) {
LOG(ERROR) << "\t" << it->first;
}
LOG(FATAL) << "Unknown action: " << name;
return NULL; // not reachable, just to suppress old compiler warnings.
}
}
// Parse GPU ids or use all available devices
//获取可用的gpu设备
static void get_gpus(vector<int>* gpus) {
if (FLAGS_gpu == "all") {
int count = 0;
#ifndef CPU_ONLY
CUDA_CHECK(cudaGetDeviceCount(&count));
#else
NO_GPU;
#endif
for (int i = 0; i < count; ++i) {
gpus->push_back(i);
}
}
else if (FLAGS_gpu.size()) {
vector<string> strings;
boost::split(strings, FLAGS_gpu, boost::is_any_of(","));
for (int i = 0; i < strings.size(); ++i) {
gpus->push_back(boost::lexical_cast<int>(strings[i]));
}
}
else {
CHECK_EQ(gpus->size(), 0);
}
}
// Parse phase from flags
//返回flags阶段,是TRAIN还是TEST,用于进一步分析
caffe::Phase get_phase_from_flags(caffe::Phase default_value) {
if (FLAGS_phase == "")
return default_value;
if (FLAGS_phase == "TRAIN")
return caffe::TRAIN;
if (FLAGS_phase == "TEST")
return caffe::TEST;
LOG(FATAL) << "phase must be \"TRAIN\" or \"TEST\"";
return caffe::TRAIN; // Avoid warning
}
// Parse stages from flags
vector<string> get_stages_from_flags() {
vector<string> stages;
boost::split(stages, FLAGS_stage, boost::is_any_of(","));
return stages;
}
// caffe commands to call by
// caffe <command> <args>
//
// To add a command, define a function "int command()" and register it with
// RegisterBrewFunction(action);
// Device Query: show diagnostic information for a GPU device.
//查询GPU设备信息
int device_query() {
LOG(INFO) << "Querying GPUs " << FLAGS_gpu;
vector<int> gpus;
get_gpus(&gpus);
for (int i = 0; i < gpus.size(); ++i) {
caffe::Caffe::SetDevice(gpus[i]);
caffe::Caffe::DeviceQuery();
}
return 0;
}
RegisterBrewFunction(device_query);
// Load the weights from the specified caffemodel(s) into the train and
// test nets.
//赋值Layers
void CopyLayers(caffe::Solver<float>* solver, const std::string& model_list) {
std::vector<std::string> model_names;
boost::split(model_names, model_list, boost::is_any_of(","));
for (int i = 0; i < model_names.size(); ++i) {
LOG(INFO) << "Finetuning from " << model_names[i];
solver->net()->CopyTrainedLayersFrom(model_names[i]);
for (int j = 0; j < solver->test_nets().size(); ++j) {
solver->test_nets()[j]->CopyTrainedLayersFrom(model_names[i]);
}
}
}
// Translate the signal effect the user specified on the command-line to the
// corresponding enumeration.
//将交互端传来的string类型的标志转换成枚举类型的变量
caffe::SolverAction::Enum GetRequestedAction(
const std::string& flag_value) {
if (flag_value == "stop") {
return caffe::SolverAction::STOP;
}
if (flag_value == "snapshot") {
return caffe::SolverAction::SNAPSHOT;
}
if (flag_value == "none") {
return caffe::SolverAction::NONE;
}
LOG(FATAL) << "Invalid signal effect \"" << flag_value << "\" was specified";
return caffe::SolverAction::NONE;
}
// Train / Finetune a model.
//trian函数功能是对一个网络模型进行训练,对模型参数进行调优
int train() {
//CHECK_GT是一个宏定义,用来检查传入的参数中“--solver=”后边是否为空,若为空,
//则报错并输出错误信息,但此处并没有对文件路径合法性检查
CHECK_GT(FLAGS_solver.size(), 0) << "Need a solver definition to train.";
//检查命令行中输入的 --snapshot和--weights信息,这两者可以不设置或只设置其一
CHECK(!FLAGS_snapshot.size() || !FLAGS_weights.size())
<< "Give a snapshot to resume training or weights to finetune "
"but not both.";
vector<string> stages = get_stages_from_flags();
/********************************************************************
实例化SolverParameter类,该类报错了solver参数和网络参数的优化规则,SolverParameter是
通过Google ProtocolBuffer自动生成的一个类, 在SharedCtor函数里对网络的各个参数进行了初始化设置
********************************************************************/
caffe::SolverParameter solver_param;
//从传入的slover文件读入网络的各个参数并传给solver_param对象
caffe::ReadSolverParamsFromTextFileOrDie(FLAGS_solver, &solver_param);
//设置训练状态
solver_param.mutable_train_state()->set_level(FLAGS_level);
for (int i = 0; i < stages.size(); i++) {
solver_param.mutable_train_state()->add_stage(stages[i]);
}
// If the gpus flag is not provided, allow the mode and device to be set
// in the solver prototxt.
//根据命令参数 -gpu或者solver.prototxt中提供的GPU配置信息设置GPU
if (FLAGS_gpu.size() == 0
&& solver_param.solver_mode() == caffe::SolverParameter_SolverMode_GPU) {
if (solver_param.has_device_id()) {
FLAGS_gpu = "" +
boost::lexical_cast<string>(solver_param.device_id());
}
else { // Set default GPU if unspecified
FLAGS_gpu = "" + boost::lexical_cast<string>(0);
}
}
vector<int> gpus; //GPU编号
get_gpus(&gpus); //获取可用的GPU
if (gpus.size() == 0) { //如果没有可用的GPU,则设置运行模式为GPU
LOG(INFO) << "Use CPU.";
Caffe::set_mode(Caffe::CPU);
}
else {
//若存在多个GPU,则使用多个GPU一起工作
ostringstream s;
for (int i = 0; i < gpus.size(); ++i) {
s << (i ? ", " : "") << gpus[i];
}
LOG(INFO) << "Using GPUs " << s.str();
#ifndef CPU_ONLY
cudaDeviceProp device_prop;
for (int i = 0; i < gpus.size(); ++i) {
//cudaGetDeviceProperties函数用于获取设备的信息
cudaGetDeviceProperties(&device_prop, gpus[i]);
//输出设备的型号(名称)
LOG(INFO) << "GPU " << gpus[i] << ": " << device_prop.name;
}
#endif
//GPU设置
solver_param.set_device_id(gpus[0]);
Caffe::SetDevice(gpus[0]);
Caffe::set_mode(Caffe::GPU);
Caffe::set_solver_count(gpus.size());
}
/******************************************************************
括号内的两个函数,从最右边的开始执行,将 “stop”“snapshot”“none”
转换成标准信号,即解析。
函数执行结果是将SIGINT_action对应STOP, SIGHUP_action对应SNAPSHOT
******************************************************************/
caffe::SignalHandler signal_handler(
GetRequestedAction(FLAGS_sigint_effect),
GetRequestedAction(FLAGS_sighup_effect));
//通过智能指针创建solver指针,指向caffe::Solver对象
shared_ptr<caffe::Solver<float> >
solver(caffe::SolverRegistry<float>::CreateSolver(solver_param));
solver->SetActionFunction(signal_handler.GetActionFunction());
/*******************************************************************************
判断用户是否定义了snapshot或者weights这两个参数中的一个,如果定义了则需要通过
Solver提供的接口从snapshot或者weights文件中去读取已经训练好的网络的参数,继续训练
********************************************************************************/
if (FLAGS_snapshot.size()) {
//打印信息,从上一个中断的训练结果文件继续训练
LOG(INFO) << "Resuming from " << FLAGS_snapshot;
//读入sanpshot文件内容
solver->Restore(FLAGS_snapshot.c_str());
}
else if (FLAGS_weights.size()) {
CopyLayers(solver.get(), FLAGS_weights);
}
//如果有不止一个GPU,用线程并行优化网络
if (gpus.size() > 1) {
caffe::P2PSync<float> sync(solver, NULL, solver->param());
sync.Run(gpus);
}
else {
LOG(INFO) << "Starting Optimization";
solver->Solve(); //执行网络模型优化,跳到solver文件执行
}
LOG(INFO) << "Optimization Done.";
return 0;
}
RegisterBrewFunction(train);
//test时间对网络模型的测试和评估
// Test: score a model.
int test() {
//判断命令行参数里是否传入网络模型
CHECK_GT(FLAGS_model.size(), 0) << "Need a model definition to score.";
//判断命令行参数里是否传入了训练好的模型参数文件,后缀为caffemodel
CHECK_GT(FLAGS_weights.size(), 0) << "Need model weights to score.";
vector<string> stages = get_stages_from_flags();
// Set device id and mode
vector<int> gpus;
get_gpus(&gpus); //查询GPU设备信息,无可用则设置为运行模式为CPU
if (gpus.size() != 0) {
LOG(INFO) << "Use GPU with device ID " << gpus[0];
#ifndef CPU_ONLY
cudaDeviceProp device_prop;
cudaGetDeviceProperties(&device_prop, gpus[0]);
LOG(INFO) << "GPU device name: " << device_prop.name;
#endif
Caffe::SetDevice(gpus[0]);
Caffe::set_mode(Caffe::GPU);
}
else {
LOG(INFO) << "Use CPU.";
Caffe::set_mode(Caffe::CPU);
}
// Instantiate the caffe net.
//创建一个网络模型对象
Net<float> caffe_net(FLAGS_model, caffe::TEST, FLAGS_level, &stages);
caffe_net.CopyTrainedLayersFrom(FLAGS_weights); //加载训练好的模型文件
LOG(INFO) << "Running for " << FLAGS_iterations << " iterations.";
vector<int> test_score_output_id;
vector<float> test_score;
float loss = 0;
for (int i = 0; i < FLAGS_iterations; ++i) { //FLAGS_iterations是配置的测试迭代次数
float iter_loss;
const vector<Blob<float>*>& result =
caffe_net.Forward(&iter_loss); //把测试数据流在网络中做前向传播
loss += iter_loss; //累加每次的损失
int idx = 0;
for (int j = 0; j < result.size(); ++j) {
const float* result_vec = result[j]->cpu_data();
for (int k = 0; k < result[j]->count(); ++k, ++idx) {
const float score = result_vec[k];
if (i == 0) {
test_score.push_back(score);
test_score_output_id.push_back(j);
}
else {
test_score[idx] += score;
}
const std::string& output_name = caffe_net.blob_names()[
caffe_net.output_blob_indices()[j]];
//输出迭代的accuracy与loss信息
LOG(INFO) << "Batch " << i << ", " << output_name << " = " << score;
}
}
}
loss /= FLAGS_iterations; // 计算平均损失并打印
LOG(INFO) << "Loss: " << loss;
for (int i = 0; i < test_score.size(); ++i) {
const std::string& output_name = caffe_net.blob_names()[
caffe_net.output_blob_indices()[test_score_output_id[i]]];
const float loss_weight = caffe_net.blob_loss_weights()[
caffe_net.output_blob_indices()[test_score_output_id[i]]];
std::ostringstream loss_msg_stream;
const float mean_score = test_score[i] / FLAGS_iterations;
if (loss_weight) {
loss_msg_stream << " (* " << loss_weight
<< " = " << loss_weight * mean_score << " loss)";
}
LOG(INFO) << output_name << " = " << mean_score << loss_msg_stream.str();
}
return 0;
}
RegisterBrewFunction(test);
//test函数用于测试网络模型的执行时间
// Time: benchmark the execution time of a model.
int time() {
CHECK_GT(FLAGS_model.size(), 0) << "Need a model definition to time.";
caffe::Phase phase = get_phase_from_flags(caffe::TRAIN);
vector<string> stages = get_stages_from_flags();
// Set device id and mode
vector<int> gpus;
get_gpus(&gpus);
if (gpus.size() != 0) {
LOG(INFO) << "Use GPU with device ID " << gpus[0];
Caffe::SetDevice(gpus[0]);
Caffe::set_mode(Caffe::GPU);
}
else {
LOG(INFO) << "Use CPU.";
Caffe::set_mode(Caffe::CPU);
}
//创建网络模型对象
// Instantiate the caffe net.
Net<float> caffe_net(FLAGS_model, phase, FLAGS_level, &stages);
// Do a clean forward and backward pass, so that memory allocation are done
// and future iterations will be more stable.
LOG(INFO) << "Performing Forward";
// Note that for the speed benchmark, we will assume that the network does
// not take any input blobs.
float initial_loss;
caffe_net.Forward(&initial_loss); //执行一遍前向传播
LOG(INFO) << "Initial loss: " << initial_loss;
LOG(INFO) << "Performing Backward";
caffe_net.Backward(); //执行反向传播
const vector<shared_ptr<Layer<float> > >& layers = caffe_net.layers();
const vector<vector<Blob<float>*> >& bottom_vecs = caffe_net.bottom_vecs();
const vector<vector<Blob<float>*> >& top_vecs = caffe_net.top_vecs();
const vector<vector<bool> >& bottom_need_backward =
caffe_net.bottom_need_backward();
LOG(INFO) << "*** Benchmark begins ***";
LOG(INFO) << "Testing for " << FLAGS_iterations << " iterations.";
Timer total_timer;
total_timer.Start();
Timer forward_timer;
Timer backward_timer;
Timer timer;
std::vector<double> forward_time_per_layer(layers.size(), 0.0);
std::vector<double> backward_time_per_layer(layers.size(), 0.0);
double forward_time = 0.0;
double backward_time = 0.0;
for (int j = 0; j < FLAGS_iterations; ++j) {
Timer iter_timer;
iter_timer.Start();
forward_timer.Start();
for (int i = 0; i < layers.size(); ++i) {
timer.Start();
layers[i]->Forward(bottom_vecs[i], top_vecs[i]);
forward_time_per_layer[i] += timer.MicroSeconds(); //累加前向传播中每层网络耗时
}
forward_time += forward_timer.MicroSeconds();
backward_timer.Start();
for (int i = layers.size() - 1; i >= 0; --i) {
timer.Start();
layers[i]->Backward(top_vecs[i], bottom_need_backward[i],
bottom_vecs[i]);
backward_time_per_layer[i] += timer.MicroSeconds(); //累加反向传播中每次网络耗时
}
backward_time += backward_timer.MicroSeconds();
LOG(INFO) << "Iteration: " << j + 1 << " forward-backward time: "
<< iter_timer.MilliSeconds() << " ms.";
}
LOG(INFO) << "Average time per layer: ";
for (int i = 0; i < layers.size(); ++i) { //统计每层网络的平均耗时
const caffe::string& layername = layers[i]->layer_param().name();
LOG(INFO) << std::setfill(' ') << std::setw(10) << layername <<
"\tforward: " << forward_time_per_layer[i] / 1000 /
FLAGS_iterations << " ms.";
LOG(INFO) << std::setfill(' ') << std::setw(10) << layername <<
"\tbackward: " << backward_time_per_layer[i] / 1000 /
FLAGS_iterations << " ms.";
}
total_timer.Stop();
//打印总的前向传播和反向传播平均耗时以及训练流程平均耗时
LOG(INFO) << "Average Forward pass: " << forward_time / 1000 /
FLAGS_iterations << " ms.";
LOG(INFO) << "Average Backward pass: " << backward_time / 1000 /
FLAGS_iterations << " ms.";
LOG(INFO) << "Average Forward-Backward: " << total_timer.MilliSeconds() /
FLAGS_iterations << " ms.";
LOG(INFO) << "Total Time: " << total_timer.MilliSeconds() << " ms.";
LOG(INFO) << "*** Benchmark ends ***";
return 0;
}
RegisterBrewFunction(time);
int main(int argc, char** argv) {
// Print output to stderr (while still logging).
FLAGS_alsologtostderr = 1; //输出打印信息
/************************************************************************
AS_STRING(CAFFE_VERSION)是一个宏定义,把形参字符串化,相当于”CAFFE_VERSION“
SetVersinoString函数用于设置版本号,目前应该是一个保留接口,并没有实际用处,这里
传入的是“CAFFE_VERSION”,也不是具体的版本号
*************************************************************************/
// Set version
gflags::SetVersionString(AS_STRING(CAFFE_VERSION));
/***************************************************************************
程序使用信息,说明程序的简单使用方式,如果输入的参数不符号要求,会在之后调用
函数ShowUsageWithFlagsRestric输出这些信息,gflags是google的一个开源的处理命令行
参数的库
***************************************************************************/
// Usage message.
gflags::SetUsageMessage("command line brew\n"
"usage: caffe <command> <args>\n\n"
"commands:\n"
" train train or finetune a model\n"
" test score a model\n"
" device_query show GPU diagnostic information\n"
" time benchmark model execution time");
/****************************************************************************
初始化flags和logging, argv[0]是本程序exe的完整路径,函数内部会把argc的值减去1,
由3变成了2(2是实际输入的变量个数)
****************************************************************************/
// Run tool or show usage.
caffe::GlobalInit(&argc, &argv);
if (argc == 2) {
#ifdef WITH_PYTHON_LAYER
try {
#endif
//根据argv[1](这里是train)的配置,返回train或其他3个函数的指针并执行对应函数
//一共可以有4个不同的参数,其他3个分别是 train,device_query和time
return GetBrewFunction(caffe::string(argv[1]))();
#ifdef WITH_PYTHON_LAYER
}
catch (bp::error_already_set) {
PyErr_Print();
return 1;
}
#endif
}
else {
gflags::ShowUsageWithFlagsRestrict(argv[0], "tools/caffe");
}
}
最新文章
- Velocity(8)——引入指令和#Stop指令
- 实践:VIM深入研究(20135301 && 20135337)
- 使用awk排除第一行和第二行的数据
- /usr/include/gnu/stubs.h:7:27: error: gnu/stubs-32.h:No such file or directory的解决办法
- Avl树的基本操作(c语言实现)
- Android布局文件夹引起的问题
- 【Away3D代码解读】(三):渲染核心流程(渲染)
- java项目使用的DBhelper类
- 深入浅出JMS(一)——JMS简要
- Ubuntu 中登录相关的日志
- ABP跨域调用API时出现的问题
- PS 滤镜算法原理——碎片效果
- python之Django学习笔记(三)---URL调度/URL路由
- [BJOI2019]勘破神机
- vim简单使用教程【转】
- Spring之Bean的生命周期详解
- 高并发编程基础Synchronized与Volatile
- 【物联网】 9个顶级开发IoT项目的开源物联网平台(转)
- QLabel-标签控件的应用
- 5、利用两个栈实现队列,完成push和pop操作