Scrapy中的核心工作流程以及POST请求
2024-08-31 05:53:43
五大核心组件工作流程
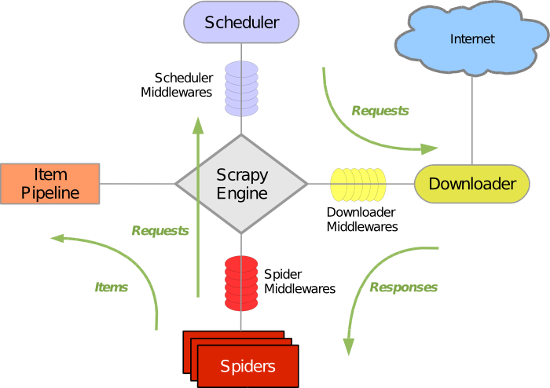
- 引擎(Scrapy)
用来处理整个系统的数据流处理, 触发事务(框架核心) - 调度器(Scheduler)
用来接受引擎发过来的请求, 压入队列中, 并在引擎再次请求的时候返回. 可以想像成一个URL(抓取网页的网址或者说是链接)的优先队列, 由它来决定下一个要抓取的网址是什么, 同时去除重复的网址 - 下载器(Downloader)
用于下载网页内容, 并将网页内容返回给蜘蛛(Scrapy下载器是建立在twisted这个高效的异步模型上的) - 爬虫(Spiders)
爬虫是主要干活的, 用于从特定的网页中提取自己需要的信息, 即所谓的实体(Item)。用户也可以从中提取出链接,让Scrapy继续抓取下一个页面 - 项目管道(Pipeline)
负责处理爬虫从网页中抽取的实体,主要的功能是持久化实体、验证实体的有效性、清除不需要的信息。当页面被爬虫解析后,将被发送到项目管道,并经过几个特定的次序处理数据。
post请求发送
- 重写爬虫应用文件中继承Spider类的 类的里面的start_requests(self)这个方法
def start_requests(self):
#请求的url
post_url = 'http://fanyi.baidu.com/sug'
# post请求参数
formdata = {
'kw': 'wolf',
}
# 发送post请求
yield scrapy.FormRequest(url=post_url, formdata=formdata, callback=self.parse)
递归爬取
- 递归爬取解析多页页面数据
- 需求:将糗事百科所有页码的作者和段子内容数据进行爬取切持久化存储
- 需求分析:每一个页面对应一个url,则scrapy工程需要对每一个页码对应的url依次发起请求,然后通过对应的解析方法进行作者和段子内容的解析。
- 实现方案:
1.将每一个页码对应的url存放到爬虫文件的起始url列表(start_urls)中。(不推荐)
2.使用Request方法手动发起请求。(推荐)
- 代码:
# -*- coding: utf-8 -*-
import scrapy
from qiushibaike.items import QiushibaikeItem
# scrapy.http import Request
class QiushiSpider(scrapy.Spider):
name = 'qiushi'
allowed_domains = ['www.qiushibaike.com']
start_urls = ['https://www.qiushibaike.com/text/'] #爬取多页
pageNum = 1 #起始页码
url = 'https://www.qiushibaike.com/text/page/%s/' #每页的url def parse(self, response):
div_list=response.xpath('//*[@id="content-left"]/div')
for div in div_list:
#//*[@id="qiushi_tag_120996995"]/div[1]/a[2]/h2
author=div.xpath('.//div[@class="author clearfix"]//h2/text()').extract_first()
author=author.strip('\n')
content=div.xpath('.//div[@class="content"]/span/text()').extract_first()
content=content.strip('\n')
item=QiushibaikeItem()
item['author']=author
item['content']=content yield item #提交item到管道进行持久化 #爬取所有页码数据
if self.pageNum <= 13: #一共爬取13页(共13页)
self.pageNum += 1
url = format(self.url % self.pageNum) #递归爬取数据:callback参数的值为回调函数(将url请求后,得到的相应数据继续进行parse解析),递归调用parse函数
yield scrapy.Request(url=url,callback=self.parse)
最新文章
- 学习 opencv---(5) 创建Trackbar(活动条) &图像对比度,亮度值调整
- 手动搭建SpringMVC报错
- SQLSERVER执行计划详解
- Function对象属性和方法
- SQL TRY CATCH
- 什么是工程师文化?各位工程师是为什么活的?作为一个IT或互联网公司为什么要工程师文化?
- 【转】FLV视频封装格式详解
- 【原创整理,基于JavaScript的创建对象方式的集锦】
- Spring装配bean
- 黄聪:微信h5支付demo微信H5支付demo非微信浏览器支付demo微信wap支付
- Collection中的迭代器
- windows上测试磁盘io性能
- [转载]Python使用@property装饰器--getter和setter方法变成属性
- web 基础
- linux下redis的安装和集群搭建
- MyBatis使用小案例
- Hadoop周边生态软件和简要工作原理(一)
- Unity3d收藏链接/ 小马哥视频
- boost库做什么用呢?
- 由等概率生成的0和1构建rand()函数
热门文章
- Matlab数组创建
- FormCollection获取请求数据
- brew 安装的.net 运行时提示"Did you mean to run dotnet SDK commands?"
- Lost connection to MySQL server at 'reading authorization packet', system error: 0_Mysql
- 洛谷P1101 单词方阵【DFS】
- 51nod1117 聪明的木匠【贪心+优先队列】
- js中writeln()方法
- kotlin来了!!
- SQL SERVER高级知识积累
- 关于Linux静态库和动态库的分析