Android开发高手课NOTE
最近学习了极客时间的《Android开发高手课》很有收获,记录总结一下。
欢迎学习老师的专栏:Android开发高手课
内存优化
卡顿的原因
频繁 GC 造成卡顿、物理内存不足时系统会触发 low memory killer 机制,系统负载过高是造成卡顿的俩个原因。
除了频繁 GC 造成卡顿之外,物理内存不足时系统会触发 low memory killer 机制,系统负载过高是造成卡顿的另外一个原因。“用时分配,及时释放”
Android 3.0~Android 7.0 将 Bitmap 对象和像素数据统一放到 Java 堆中,这样就算我们不调用 recycle,Bitmap 内存也会随着对象一起被回收。不过 Bitmap 是内存消耗的大户,把它的内存放到 Java 堆中似乎不是那么美妙。即使是最新的华为 Mate 20,最大的 Java 堆限制也才到 512MB,可能我的物理内存还有 5GB,但是应用还是会因为 Java 堆内存不足导致 OOM。Bitmap 放到 Java 堆的另外一个问题会引起大量的 GC,对系统内存也没有完全利用起来。
将 Bitmap 内存放到 Native 中,也可以做到和对象一起快速释放,同时 GC 的时候也能考虑这些内存防止被滥用。NativeAllocationRegistry 可以一次满足你这三个要求,Android 8.0 正是使用这个辅助回收 Native 内存的机制,来实现像素数据放到 Native 内存中。Android 8.0 还新增了硬件位图 Hardware Bitmap,它可以减少图片内存并提升绘制效率。
// 步骤一:申请一张空的 Native Bitmap
Bitmap nativeBitmap = nativeCreateBitmap(dstWidth, dstHeight, nativeConfig, 22);
// 步骤二:申请一张普通的 Java Bitmap
Bitmap srcBitmap = BitmapFactory.decodeResource(res, id);
// 步骤三:使用 Java Bitmap 将内容绘制到 Native Bitmap 中
mNativeCanvas.setBitmap(nativeBitmap);
mNativeCanvas.drawBitmap(srcBitmap, mSrcRect, mDstRect, mPaint);
// 步骤四:释放 Java Bitmap 内存
srcBitmap.recycle();
srcBitmap = null;
sampling模式和instrumentation模式的区别
两者的区别:
- 在sampling模式中,profiler以固定的间隔对运行中的程序进行采样,根据采样结果统计出程序中各个部分的开销。
- 在instrumentation模式中,profiler对运行中的程序所执行的每一个指令都进行记录,最后根据这份记录生成程序中各个部分的开销。
在实际使用中:
- sampling模式速度快,记录产生的数据量小,但是统计结果并不十分精确,适合于对程序全局性能进行初步的分析,找出程序瓶颈大致的“区间”。
- instrumentation模式能精确记录程序各个部分的开销,但是速度慢,记录产生的数据量大,适合于对程序局部进行精细分析,精确定位瓶颈位置。
捕获堆转储
使用:点击 Dump Java heap
堆转储显示在您捕获堆转储时您的应用中哪些对象正在使用内存。 特别是在长时间的用户会话后,堆转储会显示您认为不应再位于内存中却仍在内存中的对象,从而帮助识别内存泄漏。 在捕获堆转储后,您可以查看以下信息:
- 您的应用已分配哪些类型的对象,以及每个类型分配多少。、
- 每个对象正在使用多少内存。
- 在代码中的何处仍在引用每个对象。
- 对象所分配到的调用堆栈(目前,如果您在记录分配时捕获堆转储,则只有在 Android 7.1 及更低版本中,堆转储才能使用调用堆栈)
在您的堆转储中,请注意由下列任意情况引起的内存泄漏:
- 长时间引用 Activity、Context、View、Drawable 和其他对象,可能会保持对 Activity 或 Context 容器的引用。
- 可以保持 Activity 实例的非静态内部类,如 Runnable。
- 对象保持时间超出所需时间的缓存。

分析内存的技巧
使用 Memory Profiler 时,您应对应用代码施加压力并尝试强制内存泄漏。 在应用中引发内存泄漏的一种方式是,先让其运行一段时间,然后再检查堆。 泄漏在堆中可能逐渐汇聚到分配顶部。 不过,泄漏越小,您越需要运行更长时间的应用才能看到泄漏。
您还可以通过以下方式之一触发内存泄漏:
- 将设备从纵向旋转为横向,然后在不同的 Activity 状态下反复操作多次。 旋转设备经常会导致应用泄漏 Activity、Context 或 View 对象,因为系统会重新创建 Activity,而如果您的应用在其他地方保持对这些对象之一的引用,系统将无法对其进行垃圾回收。
- 处于不同的 Activity 状态时,在您的应用与另一个应用之间切换(导航到主屏幕,然后返回到您的应用)。
ANR
- 我的经验是,先看看主线程的堆栈,是否是因为锁等待导致。接着看看 ANR 日志中 iowait、CPU、GC、system server 等信息,进一步确定是 I/O 问题,或是 CPU 竞争问题,还是由于大量 GC 导致卡死.从 Logcat 中我们可以看到当时系统的一些行为跟手机的状态,例如出现 ANR 时,会有“am_anr”;App 被杀时,会有“am_kill”。
- 查找共性,机型、系统、ROM、厂商、ABI,这些采集到的系统信息都可以作为维度聚合,在文中我提到 Hprof 文件裁剪和重复图片监控,这是很多应用目前都没有做的,而这两个功能也是微信的 APM 框架 Matrix 中内存监控的一部分。Matrix 是我一年多前在微信负责的最后一个项目,也付出了不少心血,最近听说终于准备开源了。那今天我们就先来练练手,尝试使用 HAHA 库快速判断内存中是否存在重复的图片,并且将这些重复图片的 PNG、堆栈等信息输出
SharedPreferences的问题
- 跨进程不安全。SharedPreferences 在跨进程频繁读写有可能导致数据全部丢失。根据线上统计,SP 大约会有万分之一的损坏率。
- 加载缓慢。SharedPreferences 文件的加载使用了异步线程,而且加载线程并没有设置线程优先级,如果这个时候主线程读取数据就需要等待文件加载线程的结束。
这就导致出现主线程等待低优先级线程锁的问题,比如一个 100KB 的 SP 文件读取等待时间大约需要 50~100ms,我建议提前用异步线程预加载启动过程用到的 SP 文件。 - 全量写入。无论是调用 commit() 还是 apply(),即使我们只改动其中的一个条目,都会把整个内容全部写到文件。而且即使我们多次写入同一个文件,SP 也没有将多次修改合并为一次,这也是性能差的重要原因之一。
- 卡顿。由于提供了异步落盘的 apply 机制,在崩溃或者其他一些异常情况可能会导致数据丢失。所以当应用收到系统广播,或者被调用 onPause 等一些时机,系统会强制把所有的 SharedPreferences 对象数据落地到磁盘。如果没有落地完成,这时候主线程会被一直阻塞。
使用mmkv

mmap将一个文件或者其它对象映射进内存。(linux上的东西)
常规文件操作需要从磁盘到页缓存再到用户主存的两次数据拷贝。(从磁盘拷贝到页缓存中,由于页缓存处在内核空间,不能被用户进程直接寻址,所以还需要将页缓存中数据页再次拷贝到内存对应的用户空间中)
而mmap操控文件,只需要从磁盘到用户主存的一次数据拷贝过程。说白了,mmap的关键点是实现了用户空间和内核空间的数据直接交互而省去了空间不同数据不通的繁琐过程。因此mmap效率更高。
Serializable
- 整个序列化过程使用了大量的反射和临时变量,而且在序列化对象的时候,不仅会序列化当前对象本身,还需要递归序列化对象引用的其他对象。
- 整个过程计算非常复杂,而且因为存在大量反射和 GC 的影响,序列化的性能会比较差。另外一方面因为序列化文件需要包含的信息非常多,导致它的大小比 Class 文件本身还要大很多,这样又会导致 I/O 读写上的性能问题
- Parcel 序列化和 Java 的 Serializable 序列化差别还是比较大的,Parcelable 只会在内存中进行序列化操作,并不会将数据存储到磁盘里。通过取巧的方法可以实现 Parcelable 的永久存储,但是它也存在两个问题。
Serial的优点
- 相比起传统的反射序列化方案更加高效(没有使用反射)
- 性能相比传统方案提升了3倍 (序列化的速度提升了5倍,反序列化提升了2.5倍)
- 序列化生成的数据量(byte[])大约是之前的1/5
- 开发者对于序列化过程的控制较强,可定义哪些object、field需要被序列化
- 有很强的debug能力,可以调试序列化的过程(详见:调试)
数据的序列化
Serial 性能看起来还不错,但是对象的序列化要记录的信息还是比较多,在操作比较频繁的时候,对应用的影响还是不少的,这个时候我们可以选择使用数据的序列化。
json:原生、gosn、fastjson(数据量大了的时候最快)
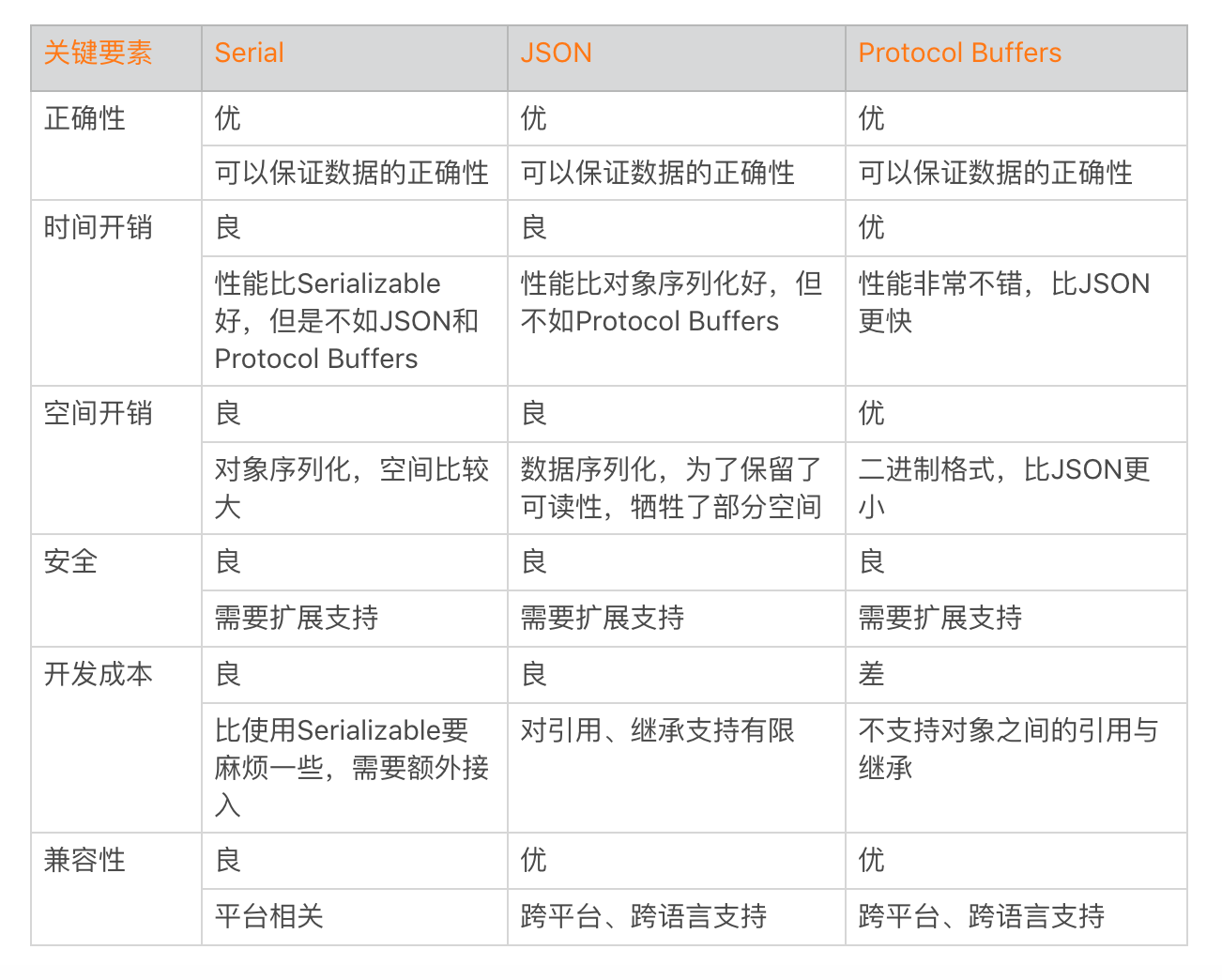
文件遍历在 API level 26 之后建议使用FileVisitor,替代 ListFiles,整体的性能会好很多。
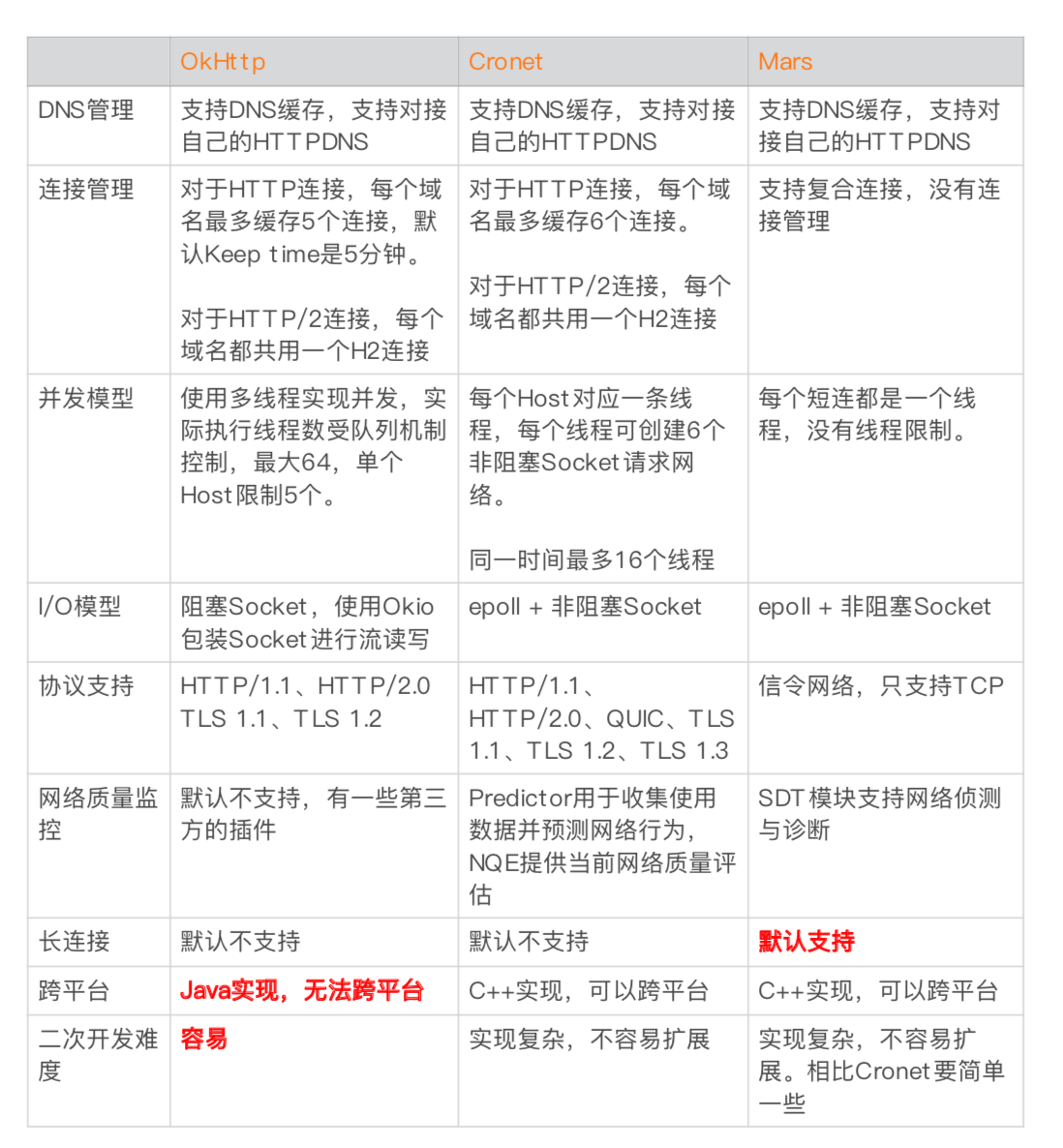
Mars的好处就是跨平台、长链接,看情况
网络数据压缩

电量
Android 是基于 Linux 内核,而 Linux 大部分使用在服务器中,它对功耗并没有做非常严格苛刻的优化。特别是国内会有各种各样的“保活黑科技”,大量的应用在后台活动简直就是“电量黑洞”。
耗电量这块, 因为要维持推送的实时到达, 只能追求黑科技, 要不然人家就会问,为啥苹果可以收到推送,android就不行~ 但是保活就会加大耗电
耗电优化的第一个方向是优化应用的后台耗电。因为用户最容易感知这个,我明明没有怎么打开,为什么耗这么多?在后台不要做这些:长时间获取 WakeLock(及时释放)、WiFi 和蓝牙的扫描、GPS、video、audio
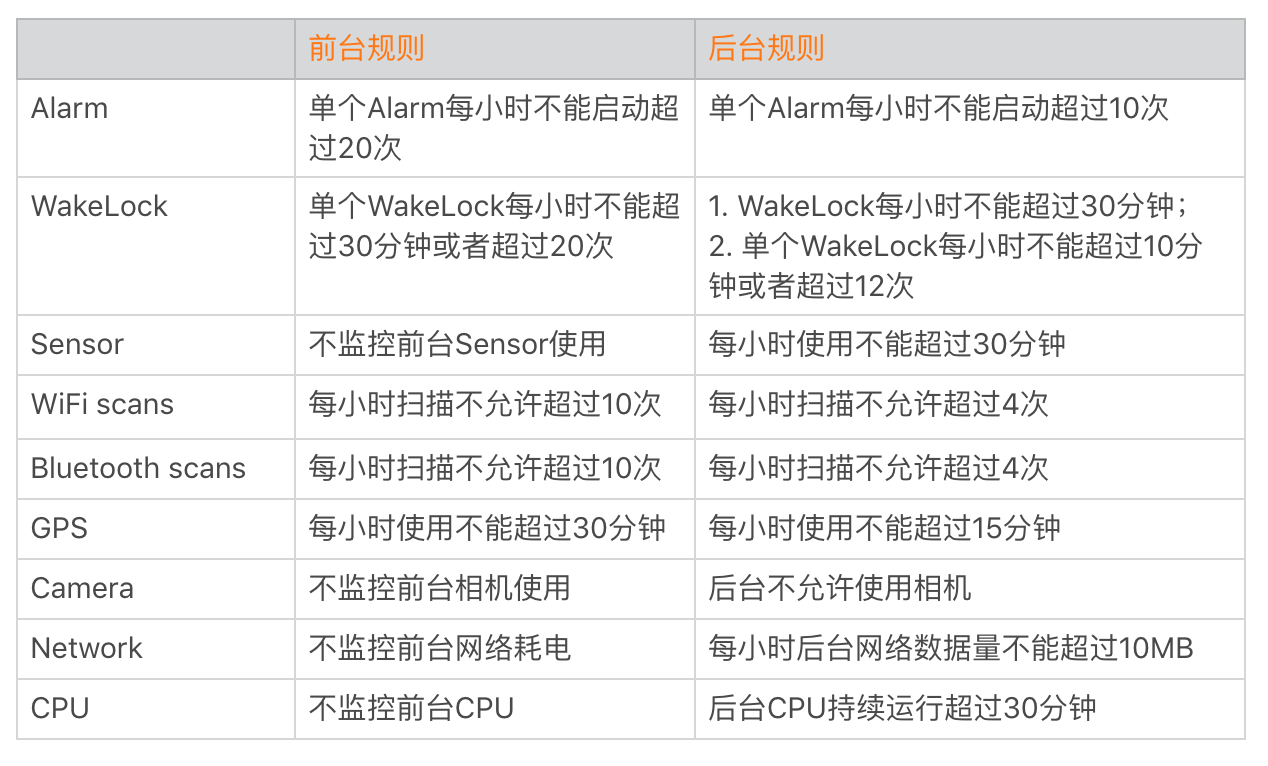
WakeLock 用来阻止 CPU、屏幕甚至是键盘的休眠。类似 Alarm、JobService 也会申请 WakeLock 来完成后台 CPU 操作.
Alarm 用来做一些定时的重复任务
通过 Hook,我们可以在申请资源的时候将堆栈信息保存起来。当我们触发某个规则上报问题的时候,可以将收集到的堆栈信息、电池是否充电、CPU 信息、应用前后台时间等辅助信息也一起带上。
UI优化

autosize是头条方案,通过反射修改系统的density值
对于硬件绘制,我们通过调用 OpenGL ES 接口利用 GPU 完成绘制。opengl是一个跨平台的图形 API,它为 2D/3D 图形处理硬件指定了标准软件接口。而 OpenGL ES 是 OpenGL 的子集,专为嵌入式设备设计。
使用 XML 进行 UI 编写可以说是十分方便,可以在 Android Studio 中实时预览到界面。如果我们要对一个界面进行极致优化,就可以使用代码进行编写界面。
xml缺点
读取xml很耗时
递归解析xml较耗时
反射生成对象的耗时是new的3倍以上
x2c:在编译的时候,通过注解的方式,将xml转换成Java代码

利用卡顿优化中的traceview或者systrace定位是最高效的
measure/layout 优化
- 减少布局的嵌套(viewstub、merge、include)
- 尽量不使用 RelativeLayout 或者基于 weighted LinearLayout,它们 layout 的开销非常巨大。这里我推荐使用 ConstraintLayout (约束布局,只有一个层级)替代 RelativeLayout 或者 weighted LinearLayout。
- 减少多余的background
- PrecomputedText(研究下),异步的textview。
Litho (研究下)如我前面提到的 PrecomputedText 一样,把 measure 和 layout 都放到了后台线程,只留下了必须要在主线程完成的 draw,这大大降低了 UI 线程的负载。
如果你没有计划完全迁移到 Litho,我建议可以优先使用 Litho 中的 RecyclerCollectionComponent 和 Sections 来优化自己的 RecyelerView 的性能。
减少apk体积
- Android Studio 3.0 推出了新 Dex 编译器 D8 与新混淆工具 R8,目前 D8 已经正式 Release,大约可以减少 3% 的 Dex 体积。但是计划用于取代 ProGuard 的依然处于实验室阶段,期待它在未来能有更好的表现。
- MultiDex.install(this);分多个dex包
- 使用andresguard,路径变成了r/d/a,还有Android 编译过程中,下面这些格式的文件会指定不压缩;在 AndResGuard 中,我们支持针对 resources.arsc、PNG、JPG 以及 GIF 等文件的强制压缩。
- 移出无用的资源
android {
...
buildTypes {
release {
shrinkResources true
minifyEnabled true
}
}
}
加快编译速度
- 你可以把编译简单理解为,将高级语言转化为机器或者虚拟机所能识别的低级语言的过程。对于 Android 来说,这个过程就是把 Java 或者 Kotlin 转变为 Android 虚拟机运行的Dalvik 字节码
- 关闭 JITandroid:vmSafeMode=“true”,关闭虚拟机的 JIT 优化
- r8/d8
- 使用tinker,可以回退
线上问题排查
- 日志打点怕打太多也怕太少,担心出现问题没有足够丰富的信息去定位分析问题。应该打多少日志,如何去打日志并没有一个非常严格的准则,这需要整个团队在长期实践中慢慢去摸索。在最开始的时候,可能大家都不重视也不愿意去增加关键代码的日志,但是当我们通过日志平台解决了一些疑难问题以后,团队内部的成功案例越来越多的时候,这种习惯也就慢慢建立起来了。
- 使用Mars的xlog,Java实现写日志,GC频繁,而C实现并不会出现这种情况,因为它不会占用Java的堆内存。
- 俩种方式上报日志:push上报,主动上报(在用户出现奔溃,反馈问题时主动上报日志(可以重启了上报))
- 正因为反复“痛过”,才会有了微信的用户日志和点击流平台,才会有美团的 Logan 和 Homles(看看) 统一日志系统。所谓团队的“提质增效”,就是寻找团队中这些痛点,思考如何去改进。无论是流程的自动化,还是开发新的工具、新的平台,都是朝着这个目标前进。
h5优化
分为前端优化和本地优化
前端优化

本地:
- webview预创建。提前创建和初始化 WebView,以及实现 WebView 的复用,这块大约可以节省 100~200 毫秒。
- 缓存。提前把网页需要的资源请求下来。
React Native 和 Weex 性能差。 JS 是解释性的动态语言,它的执行效率相比 AOT 编译后的 Java,性能依然会在几倍以上的差距。
音视频
对于我们来说,最常见的视频格式就是MP4格式,这是一个通用的容器格式。所谓容器格式,就意味内部要有对应的数据流用来承载内容。而且既然是一个视频,那必然有音轨和视轨,而音轨、视轨本身也有对应的格式。常见的音轨、视轨格式包括:
视轨:其中,目前大部分 Android 手机都支持 H.264 格式的直接硬件编码和解码;对于 H.265 来说,Android 5.0 以上的机器就支持直接硬件解码了,但是对于硬件编码,目前只有一部分高端芯片可以支持,例如高通的 8xx 系列、华为的 98x 系列。对于视轨编码来说,分辨率越大性能消耗也就越大,编码所需的时间就越长。
音轨:AAC
同一个压缩格式下,码率越高质量也就越好。
我们分别从摄像头 / 录音设备采集数据,将数据送入编码器,分别编码出视轨 / 音轨之后,再送入合成器(MediaRemuxer 或者类似 mp4v2、FFmpeg 之类的处理库),最终输出 MP4 文件。
对于目前的视频类 App 来说,还有各种各样的滤镜和美颜效果,实际上都可以基于 OpenGL 来实现。
播放的视频可能是作为视频编辑的一部分,在剪辑时需要实时预览视频特效。我们可以简单配置播放视频的 View 为一个 GLSurfaceView,有了 OpenGL 的环境,我们就可以在这上实现各种特效、滤镜的效果了。而对于视频编辑常见的快进、倒放之类的播放配置,MediaPlayer 也有直接的接口可以设置。
MediaPlayer无法精准的seek
关于学习
- 年轻人千万不要碰的东西之一,便是能获得短期快感的软件。它们会在不知不觉中偷走你的时间,消磨你的意志力,摧毁你向上的勇气。
- 需要看产出,而是不是工作时长
- 每天我们应该需要有一段时间真正的静下心来工作,而且每过一段时间也要重新审视一下自己的工作,有哪些地方做的不够好?有没有什么事情是自己或者团队的人正在反复而低效在做的,是否可以优化。
- 人的精力是有限的,每天可能也就有2个多小时能高效的产出,一定要把握好这个时间,留给最重要的事情。每天早上通勤的路上或者到公司的前10分钟可以好好规划一下当天要做的事情。
- 所谓的“T”无非就是横向和纵向两个维度。纵向解决的是深度问题,横向解决的是广度问题。
- 如果你在大厂,就应该从客户端到后端,尽可能全面深入研究你参与的模块,多想想如何把你所做的模块优化到极致,并且在巨大的用户量面前依然能够稳定运行。如果你在初创团队,在业余时间也要坚持学习,持续探索自己的技术深度。这样在将来,无论是初创团队内部的晋升,还是跳到大厂,这样努力的经验都可以成为未来无数次面试、加薪的一大亮点。
- 我建议你应该至少先在一个技术领域付出大量的精力,深入钻研透彻,然后再去思考广度的问题。这是因为经验丰富的程序员学新的东西都非常快,因为现在已经不那么容易出现太多全新的技术,所谓的新技术其实都是旧技术的重新组合和微创新。
- 现在好像有个观点说“Android 开发没人要”,大家都想转去做大前端开发,是不是真的是这样呢?事实上,无论我们使用哪一种跨平台方案,它们最终都要运行在 Android 平台上。崩溃、内存、卡顿、耗电这些问题依然存在,而且可能会更加复杂。而且从 H5 极致体验优化的例子来看,很多优化是需要深入研究平台特性和系统底层机制,我们在“高质量开发”中学到的底层和系统相关的知识依然很重要。
- 这一系列涉及的内容就非常复杂,但每一项单拆出来去看,一层层的去学习和补充,就会感觉容易很多。这一点其实在业务开发上也有体现,我们刚接手一个复杂的业务,代码庞大,注释和文档都很少,但在一段时间后你还是会对整个业务有或多或少的认识,在接到新的业务的时候也没有觉得难到无从下手,顶多是觉得复杂。底层的系统、框架也是如此,这是一个由点到面的过程。
- 在平时零散的时间里我们看到一篇技术文章,并不是阅读收藏后就结束了,这样你可能会在很短的时间里就忘掉了文章的内容。他将阅读一篇文章分成以下几个步骤:提取这篇文章要解决的问题;然后概括一下涉及的技术点;提取重点内容,比如问题发生的缘由、有哪几种解决方法。总体来说,这个方法是为了在短时间内提取出重点内容,然后记录下来后面再进行复习。所以我们都需要多记录、多复习,可以培养使用一些工具来帮助自己养成习惯
- 确认严重程度。解决崩溃也要看性价比,我们优先解决 Top 崩溃或者对业务有重大影响,例如启动、支付过程的崩溃。我曾经有一次辛苦了几天解决了一个大的崩溃,但下个版本产品就把整个功能都删除了,这令我很崩溃
- 唯有学习,不可辜负
最新文章
- spring boot(三):Spring Boot中Redis的使用
- ViewBag 找不到编译动态表达式所需的一种或多种类型,是否缺少引用?
- LeetCode之Largest Rectangle in Histogram浅析
- C#多线程学习笔记
- 最近在 OS-10.9下配置opencv, cgal, latex, qt, pillow
- mysql 基础语法
- openstack排错
- org.openqa.selenium.remote.SessionNotFoundException: The FirefoxDriver cannot be used after quit() was called.
- REST API之前端跨域访问
- log4net.dll配置以及在项目中应用 zt
- MVC ViewData和ViewBag
- 基于visual Studio2013解决C语言竞赛题之0302字符数出
- Fluent Nhibernate code frist简单配置
- iOS开发——UITableView(未完,待续...)
- NetCore持续踩坑
- Learning-Python【34】:进程之生产者消费者模型
- 代码统计工具-cloc
- 基于Vue、Bootstrap的Tab形式的进度展示
- Tomcat类加载器破坏双亲委派
- [团队项目]SCRUM项目6.0 7.0