python利用beautifulsoup多页面爬虫
2024-09-08 15:29:19
利用了beautifulsoup进行爬虫,解析网址分页面爬虫并存入文本文档:
结果:
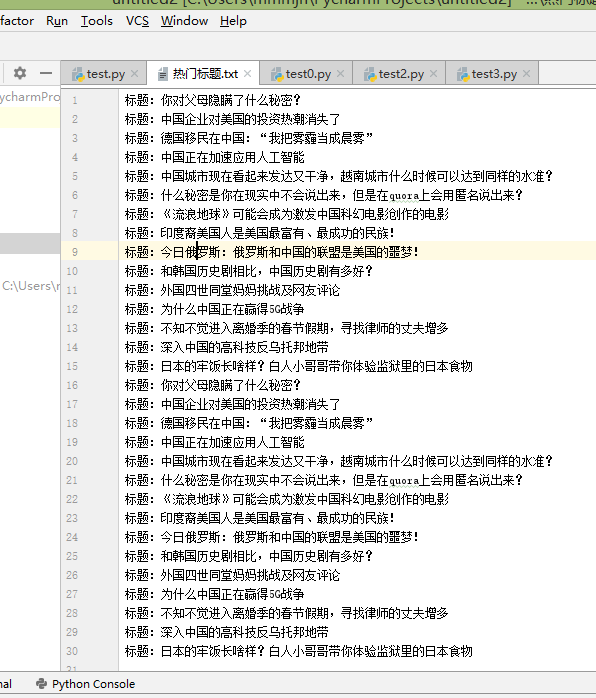
源码:
from bs4 import BeautifulSoup
from urllib.request import urlopen
with open("热门标题.txt","a",encoding="utf-8") as f:
for i in range(2):
url = "http://www.ltaaa.com/wtfy-{}".format(i)+".html"
html = urlopen(url).read()
soup = BeautifulSoup(html,"html.parser")
titles = soup.select("div[class = 'dtop' ] a") # CSS 选择器
for title in titles:
print(title.get_text(),title.get('href'))# 标签体、标签属性
f.write("标题:{}\n".format(title.get_text()))
最新文章
- XML组成结构以及C#通过DTD验证规范性
- excel2013添加坐标轴名称label
- OCJP-试题集合 | 对象的比较
- 分布式文件系统FastDFS原理介绍
- ArcGIS Portal 10.4 本地坐标系的web 3d地形展示制作说明
- Bginfo软件在域的部署和应用
- 拿起cl.exe,放下IDE
- HTML5添加背景音乐
- [CSS3备忘] transform animation 等
- JS 一条原型链扯到底
- python 获取utc时间转化为本地时间
- template模板的使用方法
- JAVA项目从运维部署到项目开发(二.ZooKeeper)
- css.aa
- 如何监控redis的cpu使用率
- excel 导入mysql
- AtCoder Beginner Contest 085(ABCD)
- POJ 2240 Arbitrage / ZOJ 1092 Arbitrage / HDU 1217 Arbitrage / SPOJ Arbitrage(图论,环)
- 样条之EHMT插值函数
- MySQL的初次见面礼基础实战篇