Hive On Spark hiveserver2方式使用
2024-09-22 12:01:38
启动hiveserver2:
hiveserver2 --hiveconf hive.execution.engine=spark spark.master=yarn
使用beeline连接hiveserver2:
beeline -u jdbc:hive2://hadoop000:10000 -n spark
注意:每个beeline对应一个SparkContext,而在Spark thriftserver中,多个beeline共享一个SparkContext
可以通过YARN监控页面观察到:分别执行了两个beeline
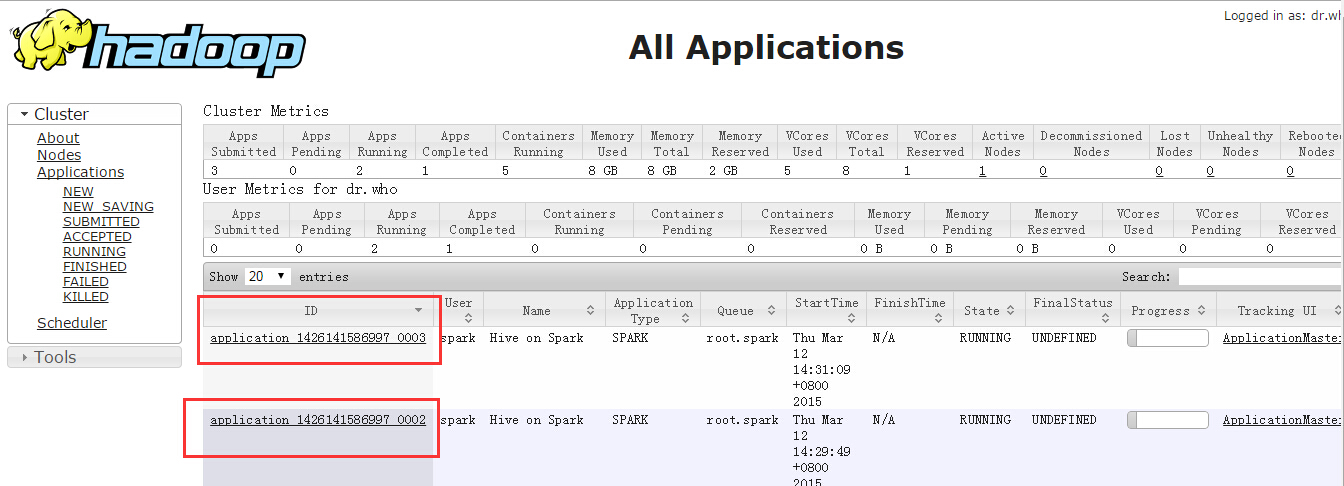
在刚启动hive时,执行第一个sql语句会比较慢。
最新文章
- Nginx在线服务状态下平滑升级或新增模块的详细操作
- Thrift 个人实战--RPC服务的发布订阅实现(基于Zookeeper服务)
- ButterKnife
- PHP中9大缓存技术总结(转载 http://www.php100.com/html/php/lei/2015/0919/8969.html)
- zw版【转发·台湾nvp系列Delphi例程】HALCON InpaintingCt2
- html之label标签
- 56. Merge Intervals
- spring beans源码解读之--BeanFactory的注册
- poj 1276 Cash Machine_多重背包
- 自己动手实现网络服务器(Web Server)——基于C#
- 《内蒙古自治区第十三届大学生程序设计竞赛试题_H 公孙玉龙》
- Proper usage of Java -D command-line parameters
- TCP 套叠字
- Azure Redis 缓存使用注意事项与排查问题文档整理
- 部署weblogic遇到的问题总结
- Linux系统编程手册-源码的使用
- SpringBoot整合Mybatis之xml
- css方法div固定在网页底部
- 剑指offer——面试题22:链表中倒数第k个节点
- 遇见Flask-Script