《利用python进行数据分析》读书笔记--第八章 绘图和可视化
http://www.cnblogs.com/batteryhp/p/5025772.html
python有许多可视化工具,本书主要讲解matplotlib。matplotlib是用于创建出版质量图表的桌面绘图包(主要是2D方面)。matplotlib的目的是为了构建一个MATLAB式的绘图接口。本书中的大部分图都是用它生成的。除了图形界面显示,还可以把图片保存为pdf、svg、jpg、png、gif等形式。
1、matplotlib API入门
Ipython可以用close()关闭界面。
Figure和Subplot
matplotlib的图像都位于Figure对象中。用plt.figure创建一个新的Figure。

import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
'''
#plt.plot(np.arange(10))
fig = plt.figure()
#plt.show()
#figsize 有一些重要的选项,特别是figsize,规定的是图片保存到磁盘时具有一定大小的纵横比。
#plt.gcf()即可得到当前Figure的引用
ax1 = fig.add_subplot(2,2,1)
ax2 = fig.add_subplot(2,2,2)
ax3 = fig.add_subplot(2,2,3)
plt.plot(np.random.randn(50).cumsum(),'k--') #fig.add_subplot 返回的对象是AxesSubplot对象,下面调用就可以了
_ = ax1.hist(np.random.randn(100),bins = 20,color = 'k',alpha = 0.3)
ax2.scatter(np.arange(30),np.arange(30) + 3 * np.random.randn(30))
plt.show()
'''
#由于Figure 和 subplot是一件非常常见的任务,于是出现了更为方便的方法(plt.subplots ),它可以创建一个新的Figure,
#并返回一个含有已创建的subplot对象的Numpy数组
fig,axes = plt.subplots(2,3) #print fig
print axes[0][0]
#axes[0][0].hist(np.random.randn(100),bins = 20,color = 'k',alpha = 0.3)
plt.show()
#这是非常实用的,因为可以轻松地对axes数组进行索引,就好像一个是一个二维数组一样,例如
#axes[0,1].还可以通过sharex和sharey指定subplot具有相同的x轴和y轴。在比较相同范围的数据时,这是
#非常实用的,否则matplotlib会自动缩放各图表的界限。
看一下subplots的作用:
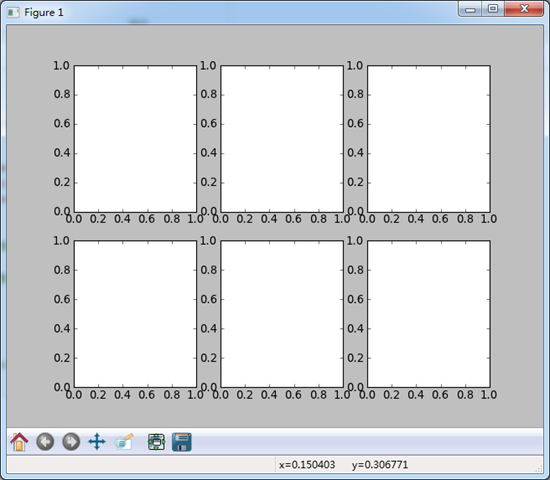
pyplot.subplots的选项还有:

上面的**fig_k可以有很多的参数,文档中有更多的内容。
调整subplot周围的间距
默认情况下,matplotlib会在subplot外围留下一定的边距,并在subplot之间留下一定的间距。间距和图像的高度和宽度有关,会自动调整。利用Figure的subplots——adjust方法可以修改间距,因此,它是一个顶级函数。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt subplots_adjust(left = None,bottom = None,right = None,top = None,wspace = None,hspace = None)
#wspace和space用于控制宽度和高度的百分比,可以用做subplot之间的间距,下面是个例子:
'''
fig,ax = plt.subplots(2,2,sharex = True,sharey = True)
for i in range(2):
for j in range(2):
ax[i,j].hist(np.random.randn(500),bins = 50,color = 'k',alpha = 0.5)
plt.subplots_adjust(wspace = 0.5,hspace = 0.5)
plt.show()
#matplotlib不会检查标签的重叠(确实是这样)。
# -*- encoding: UTF-8 -*-
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt fig,ax = plt.subplots(2,2) #cecece是白色……
ax[0,0].plot(np.arange(10),linestyle = '--',color = '#CECECE') #线上面还可以添加一些标记(marker),以强调实际的数据点。由于matplotlib创建的是连续的线形图,因此有时可能不太容易看到真实点的位置,标记可以放到格式字符串中,但是标记类型和线性必须在颜色的后面
ax[0,1].plot(np.random.randn(30).cumsum(),'ko--')
ax[1,0].plot(np.random.randn(30).cumsum(),color = 'k',linestyle = '--',marker = 'o')
#在线型图中,非实际数据点默认是按照线性插值的,可以通过drawstyle选项修改这一点。
data = np.random.randn(30).cumsum()
ax[1,1].plot(data,'ko--')
ax[1,1].plot(data,'k--',drawstyle = 'steps-post')
plt.show()
注意上面的drawstyle选项可以规定点与点之间的连接方式,或者说是插值方式,结果为:
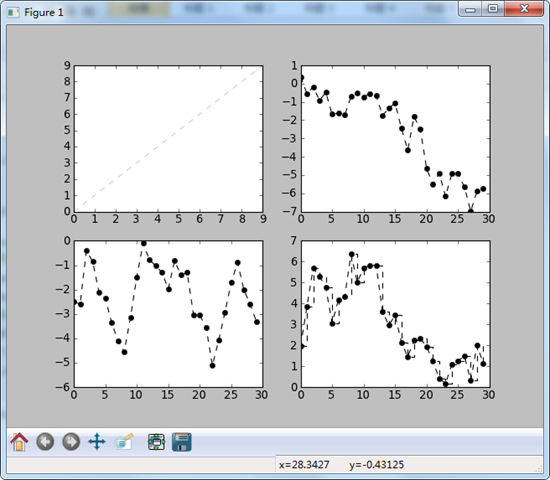
设置标题、轴标签、刻度以及刻度标签
# -*- encoding: UTF-8 -*-
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import numpy.random as npr fig = plt.figure()
ax = fig.add_subplot(1,1,1)
ax.plot(npr.randn(1000).cumsum()) #要想修改x的刻度,最简单的方法就是使用set_xticks和set_xticklabels.前者告诉matplotlib将
#刻度放在数据范围中的哪些位置,默认情况下,这些位置就是刻度标签。但是可以使用set_xticklabels将#任何其他的值用作标签
ticks = ax.set_xticks([0,250,500,700,900,1000])
#下面的totation是规定旋转角度
labels = ax.set_xticklabels(['a','b','c','d','e','f'],rotation = 30,fontsize = 'small')
#可以为x轴设置名称
ax.set_xlabel('Stages') plt.show()
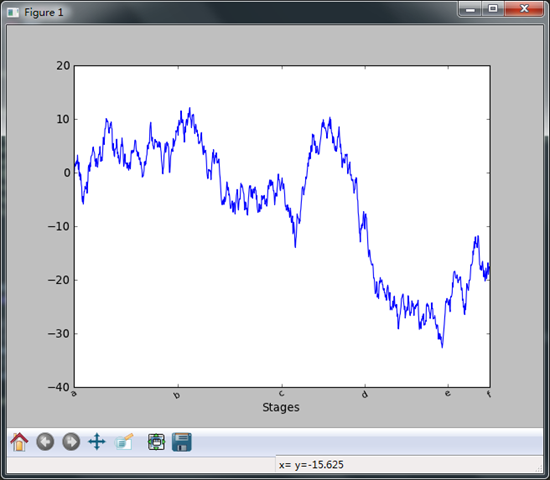
图例
# -*- encoding: UTF-8 -*-
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import numpy.random as npr
from datetime import datetime #添加图例
fig = plt.figure()
ax = fig.add_subplot(1,1,1)
ax.plot(npr.randn(1000).cumsum(),'k',label = 'one')
ax.plot(npr.randn(1000).cumsum(),'k--',label = 'two')
ax.plot(npr.randn(1000).cumsum(),'k.',label = 'three')
ax.legend(loc = 'best')
plt.show()
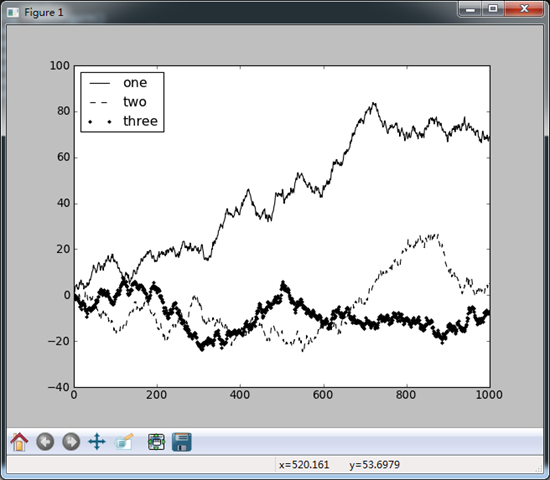
注解与绘图
# -*- encoding: UTF-8 -*-
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import numpy.random as npr
from datetime import datetime fig = plt.figure()
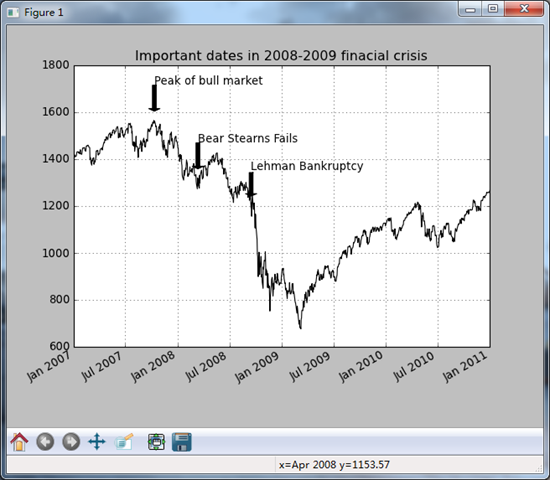
ax = fig.add_subplot(1,1,1) data = pd.read_csv('E:\\spx.csv',index_col = 0,parse_dates = True)
spx = data['SPX']
spx.plot(ax = ax,style = 'k-') crisis_data = [
(datetime(2007,10,11),'Peak of bull market'),
(datetime(2008,3,12),'Bear Stearns Fails'),
(datetime(2008,9,15),'Lehman Bankruptcy')
] for date,label in crisis_data:
ax.annotate(label,xy = (date,spx.asof(date) + 50),
xytext = (date,spx.asof(date) + 200),
arrowprops = dict(facecolor = 'black'),
horizontalalignment = 'left',verticalalignment = 'top')
ax.set_xlim(['1/1/2007','1/1/2011'])
ax.set_ylim([600,1800]) ax.set_title('Important dates in 2008-2009 finacial crisis')
plt.show()
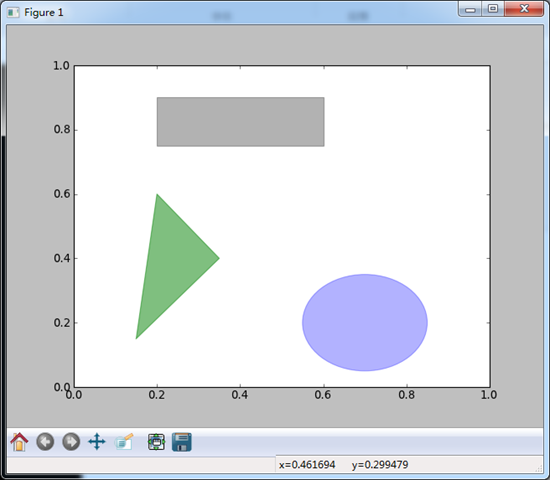
#更多关于注解的示例,请看文档 #图形的绘制要麻烦些,有一些常见的图形的对象,这些对象成为块(patch)
#如Rectangle 和 Circle,完整的块位于matplotlib.patches
#要绘制图形,需要创建一个块对象shp,然后通过ax.add_patch(shp)将其添加到subplot中 fig = plt.figure()
ax = fig.add_subplot(1,1,1) rect = plt.Rectangle((0.2,0.75),0.4,0.15,color = 'k',alpha = 0.3)
circ = plt.Circle((0.7,0.2),0.15,color = 'b',alpha = 0.3)
pgon = plt.Polygon([[0.15,0.15],[0.35,0.4],[0.2,0.6]],color = 'g',alpha = 0.5) ax.add_patch(rect)
ax.add_patch(circ)
ax.add_patch(pgon) plt.show()
将图表保存到文件
# -*- encoding: UTF-8 -*-
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import numpy.random as npr
from datetime import datetime
from io import StringIO #将图标保存到文件
#savefig函数可以保存图形文件,不同的扩展名保存为不同的格式
fig = plt.figure()
ax = fig.add_subplot(1,1,1) rect = plt.Rectangle((0.2,0.75),0.4,0.15,color = 'k',alpha = 0.3)
circ = plt.Circle((0.7,0.2),0.15,color = 'b',alpha = 0.3)
pgon = plt.Polygon([[0.15,0.15],[0.35,0.4],[0.2,0.6]],color = 'g',alpha = 0.5) ax.add_patch(rect)
ax.add_patch(circ)
ax.add_patch(pgon) #注意下面的dpi(每英寸点数)和bbox_inches(可以剪除当前图标周围的空白部分)(确实有效)
#plt.savefig('pic.jpg',dpi = 100,bbox_inches = 'tight') #不一定save到文件中,也可以写入任何文件型对象,比如StringIO: buffer = StringIO()
plt.savefig(buffer)
plot_data = buffer.getvalue() #这对Web上提供动态生成的图片是很实用的 #plt.show()
savefig的一些选项:

matplotlib配置
matplotlib的一些属性是可以设置的,比如图像大小、subplot边距、配色方案、字体大小、网格类型等。有两种方式进行操作。第一种是Python变成方式,即利用rc方法。比如:
plt.rc('figure',figsize = (10,10))
rc的第一个参数是希望自定义的对象,比如‘figure’、‘axes’、‘xtick’、‘ytick’、‘grid’、‘legend’等。其后可以跟上一系列的关键字参数。最简单的就是写成一个字典:
font_options = {'family':'monospace',
'weight':'bold',
'size':'small'}
plt.rc('font',**font_options)
matplotlibrc是配置文件,定义好以后每次加载就会用设置的参数。
2、pandas中的绘图函数
matplotlib是一种比较低级的工具,需要将各种组件组合好:数据展示(线型图、柱状图等)、图例、标题、刻度标签以及注解。这是因为制作一张图表一般需要用到多个对象。在pandas中,会省事不少。pandas能够利用DataFrame的对象特点创建标准图表的高级绘图方法。作者说pandas在线文档时最好的学习工具,书上的代码可能过时了。
线型图
#-*- encoding:utf-8 -*-
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
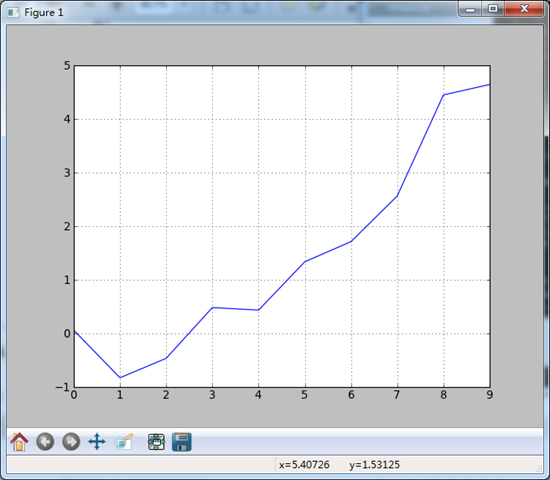
from pandas import Series,DataFrame s = Series(np.random.randn(10).cumsum(),index = np.arange(0,100,10))
#该Series对象的索引会被传给matplotlib,并绘制X轴。
#可以用use_index = False 禁用该功能
s.plot(use_index = False) #X轴的刻度和界限可以通过xticks和xlim选项进行调节,Y轴通过xticks和ylim调节 plt.show() #pandas的大部分方法都有一个可选的ax参数,可以是一个subplot对象。这可以
#使在网格中更为灵活地处理subplot的位置。
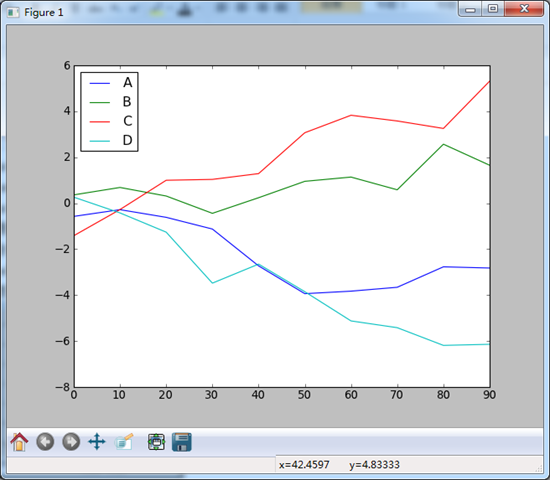
#DataFrame的plot方法会在一个subplot中为各列绘制线型图,并自动添加图例
df = DataFrame(np.random.randn(10,4).cumsum(0),
columns = ['A','B','C','D'],
index = np.arange(0,100,10))
df.plot()
plt.show()
下面把参数贴一下:


DataFrame还有一些对列进行处理的参数:

自下面开始就有一些专门的图形,绘制的时候可以与R语言进行对比:http://www.cnblogs.com/batteryhp/p/4733474.html。
柱状图
#-*- encoding:utf-8 -*-
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from pandas import Series,DataFrame #生成的线形图中代码加上kind = ‘bar’(垂直柱图) 或者 (水平)kind = ‘barh’(水平柱图)
#Series和DataFrame的索引被用作X(bar)或者Y(barh)的刻度 fig,axes = plt.subplots(2,1)
data = Series(np.random.randn(16),index = list('abcdefghijklmnop')) data.plot(kind = 'barh',ax = axes[0],color = 'k',alpha = 0.7)
data.plot(kind = 'bar',ax = axes[1],color = 'k',alpha = 0.7) #DataFrame会按照行对数据进行分组
df = DataFrame(np.random.randn(6,4),index = ['one','two','three','four','five','six'],
columns = pd.Index(['A','B','C','D'],name = 'Genus'))
#注意这里的name会被用作图例的标题,因为,这本来就是列的名字
print df
df.plot(kind = 'bar')
plt.show()
#这里的stacked是标明画累计柱图
df.plot(kind = 'bar',stacked = True,alpha = 0.5)
plt.show() #Series的value_counts可以用来显示Series中各值的频数(实验证明)
s = Series([1,2,2,3,4,4,4,5,5,5])
s.value_counts().plot(kind = 'bar')
plt.show()
下面看一个例子:
#-*- encoding:utf-8 -*-
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
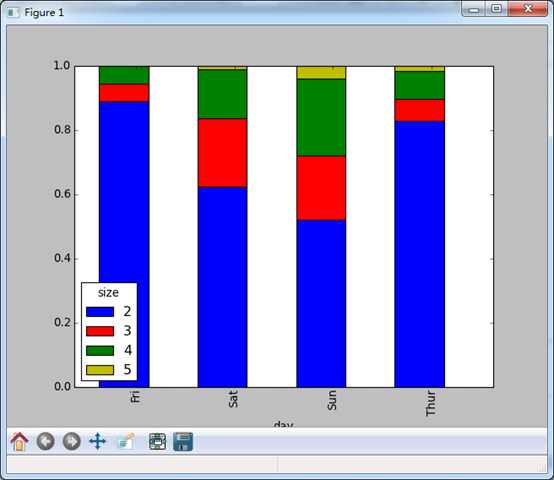
from pandas import Series,DataFrame #下面是一个例子:做一张堆积柱状图来显示每天各种聚会规模的数据点百分比
tips = pd.read_csv('E:\\tips.csv')
party_counts = pd.crosstab(tips.day,tips.size)
print party_counts
party_counts = party_counts.ix[:,2:5]
#然后进行归一化是各行和为1
party_pcts = party_counts.div(party_counts.sum(1).astype(float),axis = 0)
print party_pcts
party_pcts.plot(kind = 'bar',stacked = True)
plt.show()
直方图和密度图
#-*- encoding:utf-8 -*-
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from pandas import Series,DataFrame
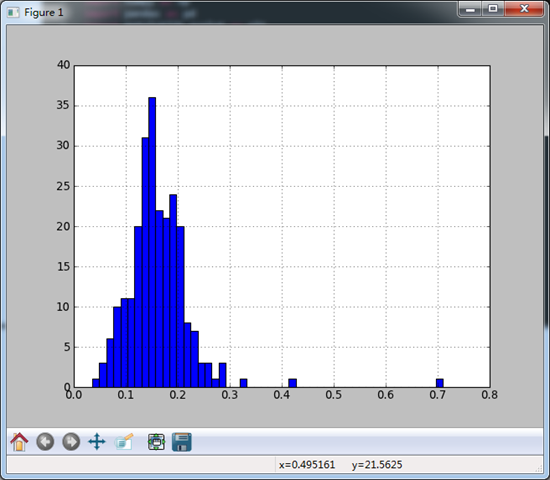
#绘制小费百分比直方图
tips = pd.read_csv('E:\\tips.csv')
tips['tip_pct'] = tips['tip'] / tips['total_bill']
#bins规定一共分多少个组
tips['tip_pct'].hist(bins = 50)
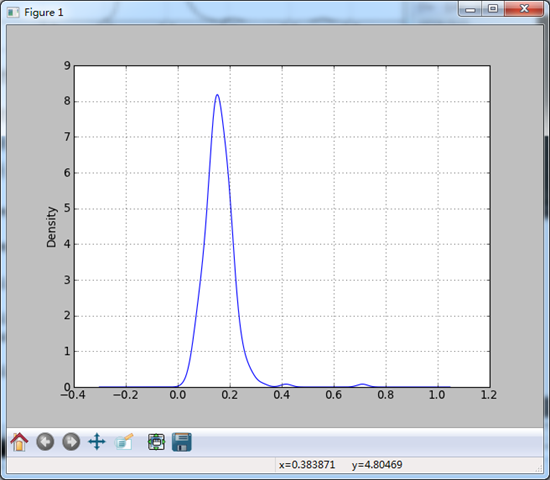
plt.show() #与此相关的是密度图:他是通过计算“可能会产生观测数据的连续概率分布的估计”
#而产生的。一般的过程将该分布金思维一组核(诸如正态之类的较为简单的分布)。
#此时的密度图称为KDE图。kind = ‘kde’即可。
tips['tip_pct'].plot(kind = 'kde')
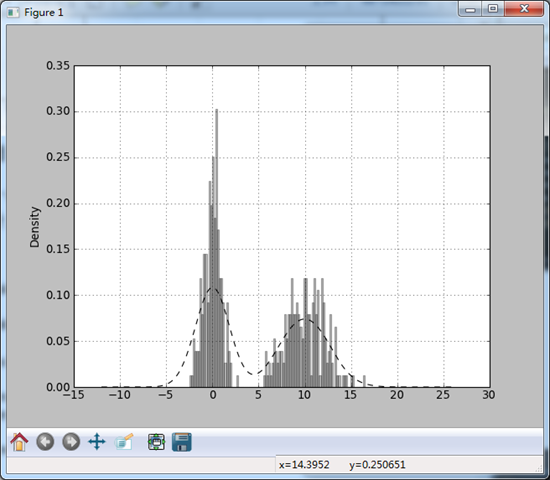
plt.show() #显然,直方图和密度图经常会在一起出现
comp1 = np.random.normal(0,1,size = 200)
comp2 = np.random.normal(10,2,size = 200)
values = Series(np.concatenate([comp1,comp2]))
print values
values.hist(bins = 100,alpha = 0.3,color = 'k',normed = True)
values.plot(kind = 'kde',style = 'k--')
plt.show()
散布图
散布图(scantter plot)是观察两个一维数据序列之间的关系的有效手段。matplotlib中的scantter方法是绘制散布图的主要方法。
#-*- encoding:utf-8 -*-
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from pandas import Series,DataFrame #下面加载macrodata中的数据集,选择其中几列并计算对数差
macro = pd.read_csv('E:\\macrodata.csv')
data = macro[['cpi','m1','tbilrate','unemp']]
#这里的diff函数是用来计算相邻两数只差,对每一列,后一个数减前一个数
trans_data = np.log(data).diff().dropna()
#print np.log(data).head()
#print np.log(data).diff().head()
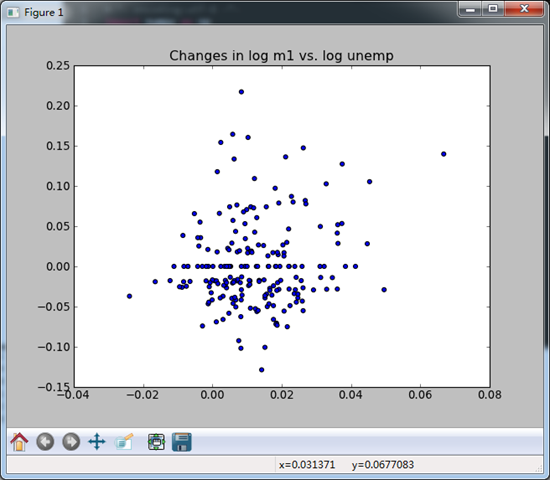
print trans_data.head() plt.scatter(trans_data['m1'],trans_data['unemp'])
plt.title('Changes in log %s vs. log %s'%('m1','unemp'))
plt.show()
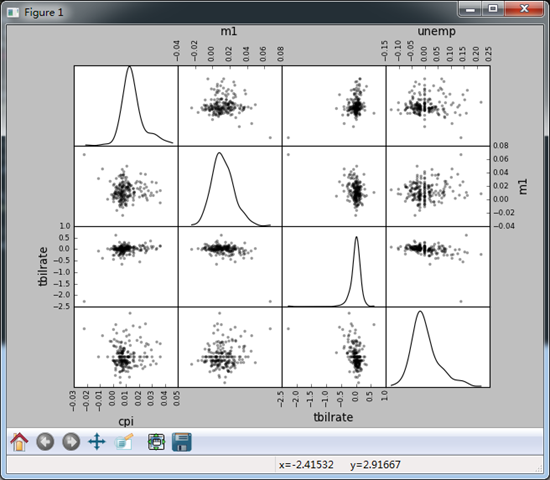
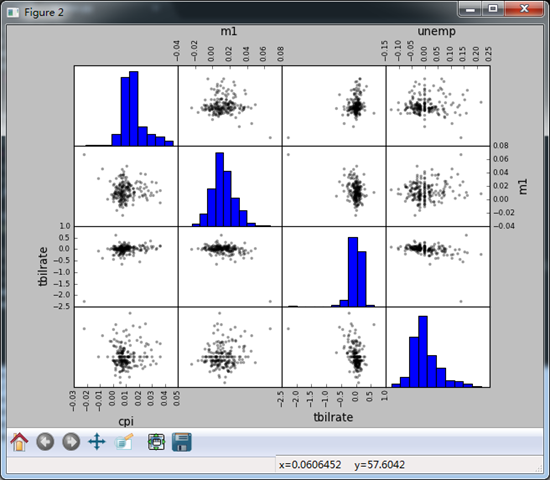
#画散布图矩阵式很有意义的pandas提供了scantter_matrix函数来创建散步矩阵
#关于 diagonal 参数,是为了不让对角线上的图形(自己和自己的散布图)显示为一条直线而设置的关于这种数据的某些图形显示
#比如 diagonal = 'kde'就是画密度图且核为kde,若diagonal='hist',则为直方图
pd.scatter_matrix(trans_data,diagonal = 'kde',color = 'k',alpha = 0.3)
pd.scatter_matrix(trans_data,diagonal = 'hist',color = 'k',alpha = 0.3)
plt.show()
绘制地图:图形化显示海地地震危机数据
这是一个例子。
#-*- encoding:utf-8 -*-
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from pandas import Series,DataFrame
from mpl_toolkits.basemap import Basemap #下面的例子应该是比较综合的
data = pd.read_csv('E:\\Haiti.csv')
#print data
#下面处理一下数据,下面的为日期,纬度、经度
#print data[['INCIDENT DATE','LATITUDE','LONGITUDE']][:10]
#print data['CATEGORY'][:6] #这些代表消息的类型
#数据中很有可能有异常值、缺失值,下面看一下
#print data.describe()
#清除错误信息并移除缺失分类信息是“一件简单的事情”
data = data[(data.LATITUDE > 18) & (data.LATITUDE < 20) & (data.LONGITUDE > -75) &
(data.LONGITUDE < -70) & data.CATEGORY.notnull()] #我们想根据分类对数据做一些分析或者图形化工作,但是各个分类字段中可能含有多个分类。此外,各个分类信息
#不仅有一个编码,还有一个英语(法语)名称。因此需要对数据进行规整化处理。下面编写两(三)个
#函数,一个用于获取所有分类的列表,一个用于将各个分类信息拆分为编码和英语明名称 #sptrip 是删除空白字符,'\n'等;注意作者这种隐式循环写法
def to_cat_list(catstr):
stripped = (x.strip() for x in catstr.split(','))
return [x for x in stripped if x]
def get_all_categoties(cat_series):
cat_sets = (set(to_cat_list(x)) for x in cat_series)
return sorted(set.union(*cat_sets))
def get_english(cat):
code,names = cat.split('.')
if '|' in names:
names = names.split('|')[1]
return code,names.strip() #下面进行一下ceshi
#print get_english('2.Urgences logistiques | Vital Lines')
#接下来做了一个将编码跟名称映射起来的字典,这是因为我们等会要用编码进行分析。
#下面将所有组合弄出来
all_cats = get_all_categoties(data.CATEGORY)
#print data.CATEGORY[:10]
#print all_cats
#生成器表达式
#生成字典
english_mapping = dict(get_english(x) for x in all_cats)
#print english_mapping['2a']
#print english_mapping['6c']
#根据分类选取记录的方式有很多,其中之一就是添加指标(或者哑变量)列,每个分类一列。
#为此,首先抽取出唯一的分类编码,并构造一个全零DataFrame(列为分类编码,索引跟data的索引一样)
def get_code(seq):
return [x.split('.')[0] for x in seq if x]
#下面是将所有的key取出来
all_codes = get_code(all_cats)
#print all_codes
code_index = pd.Index(np.unique(all_codes))
#print code_index
dummy_frame = DataFrame(np.zeros((len(data),len(code_index))),index = data.index,columns = code_index)
#print len(data)
#print dummy_frame.ix[:,:6]
#下面将各行中适当的项设置为1,然后再与data进行连接: for row,cat in zip(data.index,data.CATEGORY):
codes = get_code(to_cat_list(cat))
dummy_frame.ix[row,codes] = 1
#添加前缀,并且合并一下
data = data.join(dummy_frame.add_prefix('category_'))
#print data
#接下来开始画图吧,我们希望把数据绘制在海地的地图上。basemap数据集是matplotloib的一个插件
#使得能够用Python在地图上绘制2D数据。basemap提供了许多不同的地球投影以及一种将地球上的经纬度
#坐标投影转换为二维matplotlib图的方式。
#“经过一遍又一遍的尝试”,作者编写了下面的函数,绘制出一张简单的黑白地图。 def basic_haiti_map(ax = None,lllat = 17.25,urlat = 20.25,lllon = -75,urlon = -71):
#创建极球面投影的Basemap实例。
m = Basemap(ax = ax,projection = 'stere',
lon_0 = (urlon + lllon) / 2,
lat_0 = (urlat + lllat) / 2,
llcrnrlat = lllat,urcrnrlat = urlat,
llcrnrlon = lllon,urcrnrlon = urlon,
resolution = 'f' )
由于window下安装geos不成功,这部分等ubuntu装好了再接着写。
4、Python图形化工具生态系统
介绍几个其他的绘图工具。
Chaco
特点:静态图 + 交互图形,非常适合用复杂的图形化方法表示数据的内部关系。对交互支持的好的多,交互式GUI是个不错选择。
mayavi
这是一个基于开源C++图形库VTK的3D图形工具包。可以集成到Ipython交互使用。
其他库
其他库或者应用还有:PyQwt、Veusz、gnuplotpy、biggles等,大部库都在向基于Web的技术发展,并逐渐远离桌面图形技术。
图形化工具的未来
基于Web技术(如Javascript)的图形化是必然的发展趋势,现在已经有不少了,higncharts等。
最新文章
- js兼容性
- java 转换流
- Composer实现PHP中类的自动加载
- 第二届中国移动互联网测试大会PPT
- JSON风格指南-真经
- C#反射的应用
- java.io中流的操作:字节流、字符流
- Android 时间格式的正则表达式
- UVa 10892 (GCD) LCM Cardinality
- php resizeimage 部分jpg文件 生成缩略图失败
- C#中使用SHA1和MD5加密字符串
- NIO FileChannel
- React Native学习(四)—— 写一个公用组件(头部)
- js BOM DOM
- ajax实现无刷新分页效果
- 泛型的 typeof
- 使用excel整理脚本
- 学习笔记整理之StringBuffer与StringBulider的线程安全与线程不安全
- Thinkphp3.1 php 链接SqlServer
- 249. Group Shifted Strings把迁移后相同的字符串集合起来