《Spark快速大数据分析》—— 第五章 数据读取和保存
2024-09-09 16:27:25
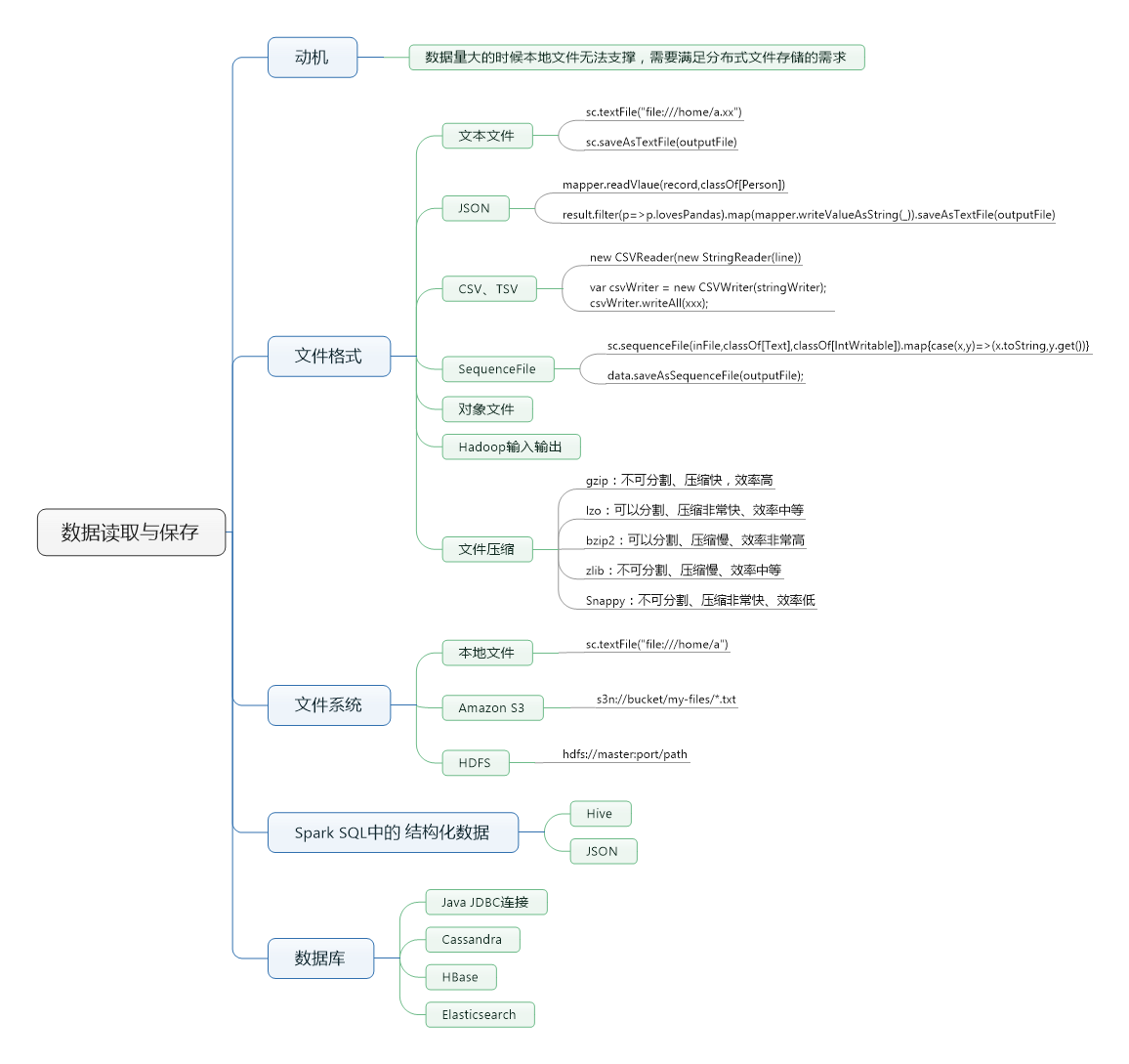
由于Spark是在Hadoop家族之上发展出来的,因此底层为了兼容hadoop,支持了多种的数据格式。如S3、HDFS、Cassandra、HBase,有了这些数据的组织形式,数据的来源和存储都可以多样化~
最新文章
- Android WIFI 分析(一)
- 跟着ttlsa一起学zabbix监控呗
- 数据库Error:The ScriptCollection in ScriptName not find
- ios-高德、百度后台定位并上传服务器
- day01-02--数据库概念介绍
- dup2()函数的使用,
- android在程序中打开另一个程序
- Google搜索技巧-从入门到精通(从此学习进步、工作顺心)
- 转载Jquery中的三种$()
- 388A Fox and Box Accumulation
- MYSQL用户权限管理学习笔记
- linux scp传文件
- 学习 JavaScript (七) 内存问题
- Java 由浅入深GUI编程实战练习(二)
- kubernetes云平台管理实战: 高级资源deployment-滚动升级(八)
- Python3实现自动点赞抖音小姐姐
- IDEA 配置datasource,提升编码效率,让你在 Mapper.xml 中编写sql可以飞起来~
- html播放音乐
- SharePoint Visio Graphics Service-PowerShell
- HihoCoder - 1781: Another Bubble Sort (冒泡排序&逆序对)