基于zipkin分布式链路追踪系统预研第一篇
2024-10-15 07:56:10
本文为博主原创文章,未经博主允许不得转载。
分布式服务追踪系统起源于Google的论文“Dapper, a Large-Scale Distributed Systems Tracing Infrastructure”(译文可参考此处),Twitter的zipkin是基于此论文上线较早的分布式链路追踪系统了,而且由于开源快速被各社区所研究,也诞生了很多的版本。
在这里也是对zipkin进行研究,先贴出Twitter zipkin结构图。

结构比较简单,大概流程为:
- Trace数据的收集至Scribe(Facebook开源的日志传输通路)或Kafka(Apache分布式消息系统)。
- Scribe/Kafaka中的数据由控制器存入数据库中。
- 最后由UI和Query查询展示。
这里将提到一个日志分析系统ELK,它是一个集合日志收集、日志分析查询于一体。系统主要拆分为:收集(logstash)、存储(elasticsearch)、展示(kibana)三部分,目前被我们用于做分布式服务日志系统。
在此想到尽然ELK已经帮我们收集了分布式服务的日志并统一存储,为何链路追踪系统不能直接用这些日志做查询展示呢?
所以从此角度出发,我对该方案结构进行构图,希望可行。先贴出我画的结构图(丑了些,将就看吧):
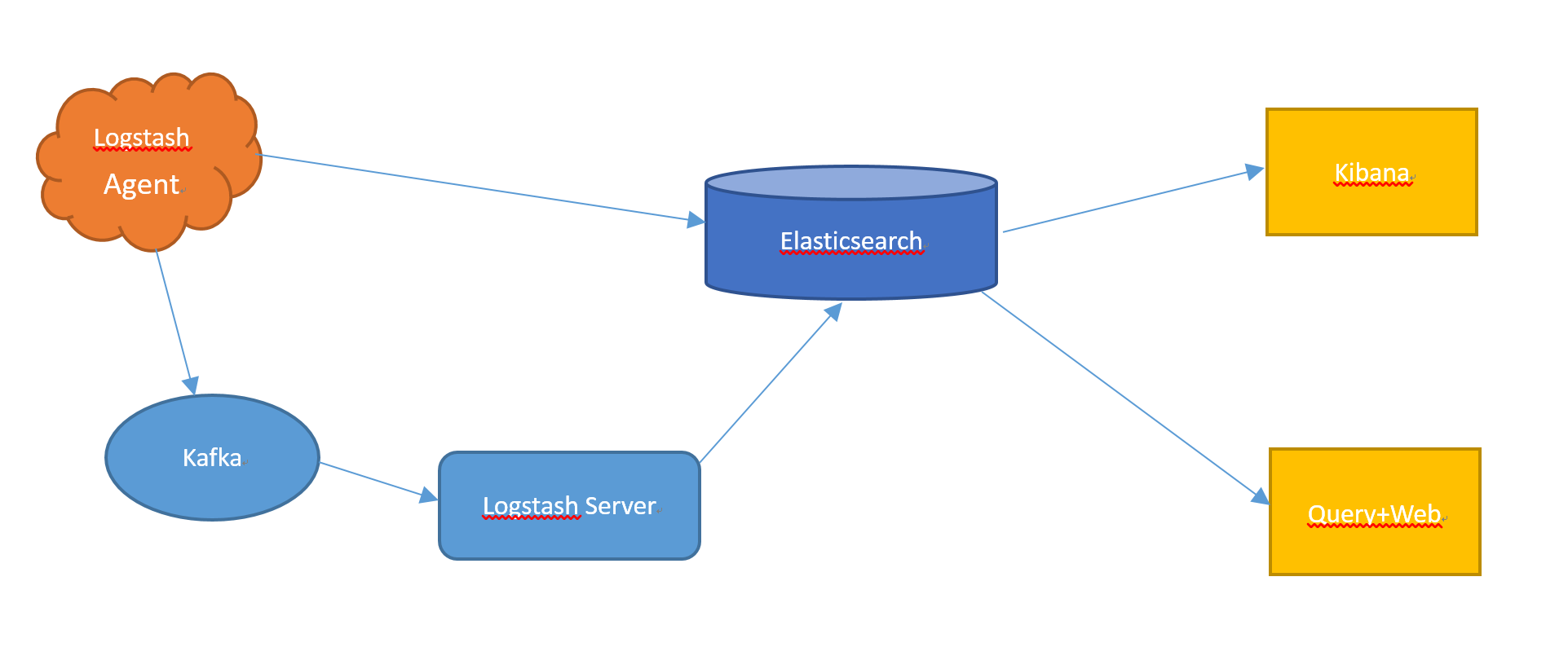
对此结构开始部署环境,环境部署在下次讲到。
当前部门研发分布式服务架构,讨论到分布式链路追踪系统。所以在这对分布式链路追踪系统进行一个学习,并写成笔记作为一个学习的动力。 笔记中所有都为个人见解,可能存在错误,望大家指出。
最新文章
- prefix pct文件配置Xcode
- CSS的三种引入方式
- 解决Ehcache缓存警告问题
- JavaWeb学习笔记——DOM4J
- C++中各种容器特点总结
- php过滤ascii控制字符
- 移动前端头部标签(HTML5 head meta)
- sql 索引 填充因子(转)
- 应用部署到JBOSS上遇到的问题
- centos jdk切换
- 设计模式(二): BUILDER生成器模式 -- 创建型模式
- MySQL(14):Select-limit(限制获得的记录数量)
- javaweb笔记2之HTTP协议
- 基于nginx+lua简单的灰度发布系统
- js中frame的操作问题
- ASP.NET常用的控件怎么添加
- [lua] 游戏客户端逻辑使用lua协程
- 自定义Base16加密
- Pat1108: Finding Average
- Asp.Net MVC Unobtrusive Ajax