OpenCV2计算机编程手册(一)操作像素
1. 引言
从根本上来说,一张图像是一个由数值组成的矩阵。这也是opencv中使用 cv::Mat 这个数据结构来表示图像的原因。矩阵的每一个元素代表一个像素。对于灰度图像(单通道)而言,像素由8位无符号数来表示,其中代表黑色,代表白色。对于彩色图像(BGR三通道)而言,每个像素需要三个这样的8位无符号数来表示,这种情况下,矩阵的元素是一个三元数。
opencv允许我们创建不同像素类型的矩阵或图像,例如整型(CV_8U)或者浮点型(CV_32F),它们在一些图像处理过程中,用来保存诸如中间值这样的内容非常有用。大多数矩阵运算可以被应用于任意类型的矩阵,但是有些运算对数据类型或者矩阵的通道数有所要求。
典型的opencv C++代码需要包含以下头文件
#include <opencv2/core/core.hpp>
#include <opencv2/highgui/highgui.hpp>
#include <opencv2/imgproc/imgproc.hpp>
2.1 载入、显示和保存图像
#include <iostream>
#include "opencv2/highgui.hpp" using namespace std; int main()
{
//声明一个表示图像的变量
cv::Mat image;
image = cv::imread("waves.jpg");
if (!image.data)
{
std::cerr << "could not load image" << std::endl;
}
cv::namedWindow("Original Image"); //定义窗口
cv::imshow("Original Image", image); //显示图像 cv::Mat result;
cv::flip(image, result, ); //1表示水平翻转,0表示垂直翻转,负数表示既有水平又有垂直翻转
cv::namedWindow("Output Image");
cv::imshow("Output Image", result); cv::waitKey(); //等待用户按键输入
cv::imwrite("output.jpg", result); //保存图片 return ;
}
拓展阅读
opencv2之后引入了崭新的C++接口。之前使用的C函数和数据结构依然可以使用,其中图像是通过IplImage进行操作的,该结构继承自IPLk库,即因特尔图像处理库(Intel Image Processing Library)。如果你使用老式的C风格接口,那么你需要操作IplImage结构。幸运的是,存在一个方便的从IplImage到Mat对象。
IplImage* iplImage = cvLoadImage("waves.jpg",); //彩色用1,灰度用0
cv::Mat image2 = cv::cvarrToMat(iplImage); //从IplImage到Mat对象
cvReleaseImage(&iplImage); //释放指向的内存
我们应该尽量避免使用这个被废弃的数据结构。
2.2 改变像素值
实现方法
//第一个参数是输入图像,该函数会修改此图像
//第二个参数是我们欲将其替换成白色像素点个数
void salt(cv::Mat &image, int n)
{
for (int k = ; k < n; k++)
{
int j = rand() % image.cols;
int i = rand() % image.rows;
if (image.channels() == )//灰度图
{
image.at<uchar>(i, j) = ;
}
else if (image.channels() == )//彩色图
{
image.at<cv::Vec3b>(i, j)[] = ;
image.at<cv::Vec3b>(i, j)[] = ;
image.at<cv::Vec3b>(i, j)[] = ;
}
}
} int main()
{
//读取图像
cv::Mat image = cv::imread("boldt.jpg");
//调用函数增加噪声
salt(image, );
//显示图像
cv::namedWindow("Image");
cv::imshow("Image", image);
cv::waitKey(); return ;
}
类cv::Mat有若干成员函数可以获取图像的属性。公有成员变量 cols 和 rows 给出了图像的宽和高。成员函数 at<type>(int y, int x) 可以用来存取图像元素。但是必须制定图像的数据类型(uchar是灰度图):
image.at<uchar>(i, j) = ;
注意:程序员一定要确保指定的数据类型要确保指定的数据类型要和矩阵中的数据类型相符合。at 方法本身并不会进行任何的数据类型转换。
对于彩色图像,每个像素由三个部分构成,B、G、R三个通道。因此,一个包含彩色图像的 cv::Mat 会返回一个由三个8位数构成的向量。OpenCV将此类向量定义为 cv::Vec3b,即由三个 unsigned char 组成的向量。这也解释了为什么存取彩色图像像素的代码可以写成以下形式:
image.at<cv::Vec3b>(i, j)[channel] = value;
其中,索引值 channel 表示颜色通道值 B(0), G(1), R(2).
类似地,OpenCV还有二元素向量类型和四元素向量类型(cv::Vec2b 和 cv::Vec4b)。OpenCV同样拥有针对其他数据类型的向量类型,如s代表short,i代表int,f代表float,d代表double。所有的这些类型都是使用模板类 cv::Vect<T, N>定义的,其中 T 代表类型, N 代表向量中元素个数。
拓展阅读
有时候使用 cv::Mat 的成员函数会很麻烦,因为返回值的类型必须通过在调用时通过模板参数指定。因此,OpenCV提供了了 cv::Mat_, 它是 cv::Mat 的一个模板子类。在事先知道矩阵类型的情况下,使用 cv::Mat_ 可以带来一些便利。这个类额外定义了一些方法,但是没有任何成员变量,所以此类的指针或者引用可以直接进行相互类型转换。该类重载了操作符(),允许我们可以通过它直接存取矩阵元素。因此,假设有一个 uchar 型的矩阵,我们可以这样写。
cv::Mat_<uchar> im2 = image;//im2指向image
im2(, ) =
由于cv::Mat_ 的元素类型在创建实例的时候已经声明,操作符()在编译期就知道需要返回的数据类型。使用操作符() 得到返回值和使用 cv::Mat 的 at 方法得到的返回值是完全一致的,而且写起来更加简洁。
2.3 使用指针遍历图像
在大多数的图像处理中,为了计算,我们需要遍历图像的所有像素。考虑到将来访问的像素个数非常之多,高效地遍历图像时非常重要的。接下来的两个方法展示了两种不同的图像遍历循环实现方法。第一种方法使用的指针算术。
实现方法
void colorReduce(cv::Mat &image, int div = )
{
int nl = image.rows;//行数
int nc = image.cols * image.channels();//每行元素的个数
for (int j = ; j < nl; j++)
{
uchar * data = image.ptr<uchar>(j);
for (int i = ; i < nc; i++)
{
data[i] = data[i] / div*div + div / ;
}
}
} int main()
{
cv::Mat image = cv::imread("marais.jpg");
cv::namedWindow("Original Image");
cv::imshow("Original Image", image); colorReduce(image);
cv::namedWindow("New Image");
cv::imshow("New Image", image);
cv::waitKey(); return ;
}
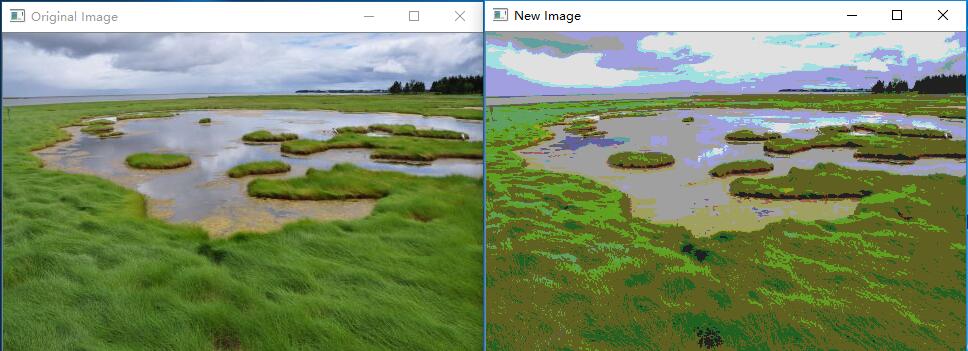
作用原理
在一个彩色图像中,图像数据缓冲区中的前三个字节对应图像左上角像素的三个通道值,接下来的三个字节对应第一行的第二个像素,以此类推(注意:OpenCV默认使用BGR的通道顺序)。一个宽为W、高为H的图像需要一个大小由 W*H*3个 uchar 构成的内存块。但是出于效率的考虑,每行会填补一些额外像素。这是因为如果每行的长度是4或8的倍数,一些多媒体处理芯片可以更高效地处理图像。这些额外的像素不会被显示或者保存,填补的值将被忽略,可以使用 isContinuous() 成员函数检查。成员变量 cols 代表图像的宽度(图像的 列数),rows 代表图像的高度(图像的行数),step 代表以字节为单位的图像的有效宽度。每个像素的大小可以用 elemSize() 方法得到:对于一个三通道的short型矩阵(CV_16SC3),elemSize() 返回6。图像的通道数可以由 channels() 方法获得。total() 方法返回矩阵的像素个数。
cv::Mat 提供了 ptr 方法可以得到图像任意行的首地址。ptr 方法是一个模板函数,下面这句代码它返回第 j 行的首地址:
uchar * data = image.ptr<uchar>(j);
在处理语句中,我们可以等效地使用指针运算从一列移动到下一列。所以,我们也可以这样写:
*data++ = *data / div * div + div / ;
拓展阅读
在我们的颜色缩减例子中,颜色变换是直接作用在输入图像上的,我们称之为 In-place 变换。这种方式不需要额外的图像来保存输出结果,这样可以在必要的时候节约内存。但在一些应用中,用户不希望原始图像被改变。这种情况下,用户不得不在调用函数之前创建一份输入图像的拷贝。注意,最简单的创建一个图像的“深拷贝”的方式是调用 clone 函数。
cv::Mat image = cv::imread("marais.jpg");
cv::Mat imageClone = image.clone();
colorReduce(imageClone);
这个额外的复制操作可以通过一种实现技巧来避免。在这种实现中,我们给用户选择到底是否采用 In-place 的处理方式。函数的实现是这样的:
void colorReduce(const cv::Mat &image, cv::Mat &result, int div = );
注意:输入图像是通过常引用传递的,这意味着这个图像不会被函数修改。当选择 In-place 的处理方式时,用户可以将输出指定为同一个变量:
colorReduce(image, image);
否则,用户必须提供另外一个cv::Mat的实例
cv::Mat result;
colorReduce(image, result);
colorReduce 函数内部操作前要保证输出图像与输入图像的大小和元素数据类型一致。cv::Mat 的 create() 成员函数可以创建一个与输入图像尺寸和类型相同的矩阵:
result.create(image.rows, image.cols, image.type());
而且如果新指定的尺寸和数据类型与原来的一样,create() 函数会直接返回,并不会对实例做任何更改。
注意:create 函数创建的图像的内存都是连续的,create() 函数不会对图像的行进行填补。分配的内存大小为 total() * elemSize()。colorReduce 函数内部循环使用两个指针完成:
for (int j = ; j < nl; j++)
{
const uchar * data_in = image.ptr<uchar>(j);
uchar * data_out = result.ptr<uchar>(j);
for (int i = ; i < nc; i++)
{
data_out[i] = data_in[i] / div*div + div / ;
}
}
2.4 使用迭代器遍历图像
在面向对象的编程中,遍历数据集和通常是通过迭代器iterator来完成的。迭代器是一种特殊的类,它专门用来遍历集合中的各个元素,同时隐藏了在给定的集合上元素迭代的具体实现方式。这种信息隐蔽原则的使用使得遍历集合更加容易。另外,不管数据类型是什么,我们都可以使用相似的方式遍历集合。标准模板库(STL)为每个容器类型都提供了迭代器。OpenCV同样为cv::Mat 提供了与STL迭代器兼容的迭代器。
实现方法
一个 cv::Mat 实例的迭代器可以通过创建一个 cv::MatIterator_ 的实例来得到。类似与=于子类 cv::Mat_,下划线意味着 cv::MatIterator_ 是一个模板类。之所以如此是由于通过迭代器来存取图像的元素,就必须在编译期知道图像元素的数据类型。一个RGB图像迭代器可以用如下方式声明:
cv::MatIterator_<cv::Vec3b> it;
另外一种方式是使用定义在Mat_内部的迭代器类型:
cv::Mat_<cv::Vec3b>::iterator it;
这样就可以通过常规的begin和end这两个迭代器方法来遍历所有像素。值得指出的是,如果使用后一种方式,那么begin和end方法也必须使用对应的模板化的版本。这样,我们的颜色缩减函数就可以重写为:
void clolorReduce(cv::Mat &image, int div)
{
//得到初始位置的迭代器
cv::Mat_<cv::Vec3b>::iterator it = image.begin<cv::Vec3b>();
//得到终止位置的迭代器
cv::Mat_<cv::Vec3b>::iterator itend = image.end<cv::Vec3b>();
//遍历所有像素
for (; it != itend; it++)
{
//处理每个像素------------------------------
(*it)[] = (*it)[] / div * div + div / ;
(*it)[] = (*it)[] / div * div + div / ;
(*it)[] = (*it)[] / div * div + div / ;
}
}
作用原理
使用迭代器遍历任何形式的集合都遵循同样的模式。首先,创建一个迭代器特化版本的实例。在我们的示例代码中,就是 cv::Mat_<cv::Vec3b>::iterator (或者 cv::MatIterator_<cv::Vec3b>)。然后,使用集合初始位置(图像左上角)的迭代器对其进行初始化。初始位置的迭代器通常是通过 begin() 方法得到的。对于一个cv::Mat 的实例,你可以通过 image.begin<cv::Vec3b>() 来得到图像左上角位置的迭代器。你也可以通过对迭代器进行代数运算。例如:如果你想从图像的第二行开始,那么你可以用 image.begin<cv::Vec3b>()+image.cols来初始化迭代器。集合终止位置的迭代器可以通过 end() 方法得到。但是,end() 方法得到的迭代器也可以进行代数运算。例如,如果你希望迭代过程在图像的最后一行之前停止,那么迭代器的终止位置应该 image.end<cv::Vec3b>()-image.cols。一旦迭代器初始化完成之后,你就可以创建一个循环遍历所有的元素直至到达终止位置。一个典型的while循环如下所示:
while (it!= itend) {
// process each pixel ---------------------
...
// end of pixel processing ----------------
++it;
}
操作符 ++ 用来将迭代器从当前位置移动到下一个位置。如果你要使用更大的步长,比如,用 it += 10 将迭代器每次移动10px。
在循环体内部,你可以使用解引用 * 来读取当前元素。读操作使用 element = *it, 写操作使用 *it = element. 注意:如果如果你的操作对象时const cv::Mat, 或者你想强调当前循环不会对 cv::Mat 的实例进行修改,那么你就应该创建常量迭代器:
cv::MatConstIterator_<cv::Vec3b>it;
cv::Mat_<cv::Vec3b>::const_iterator it;
拓展阅读
在本例中,迭代器的开始位置和终止位置是通过模板函数 begin() 和 end() 得到的。如同前文一样,我们也可以通过 cv::Mat_ 的实例来得到它们,这样可以避免在使用 begin() 和 end() 方法的时候还要指定迭代器的类型。之所以可以这样,是因为一个 cv::Mat_ 引用在创建的时候就隐式声明了迭代器的类型。
cv::Mat_<cv::Vec3b> cimage(image);
cv::Mat_<cv::Vec3b>::iterator it= cimage.begin();
cv::Mat_<cv::Vec3b>::iterator itend= cimage.end();
2.5 编写高效的图像遍历循环
实现方法
OpenCV 有一个非常实用的函数 cv::getTickCount(), 可以用来测量一段代码的运行时间。这个函数返回从上次开机算起的时钟周期数。由于我们需要的是某个代码段运行的毫秒数,因此还需要另外一个函数 cv::getTickFrequency()。此函数返回每秒内的时钟周期数。因此,用于统计函数或一段代码的运行时间的方法如下:
const int64 start = cv::getTickCount();
colorReduce(image); // a function call
// elapsed time in seconds
double duration = (cv::getTickCount()-start) / cv::getTickFrequency();
效率最高的版本:
int main()
{
cv::Mat image = cv::imread("marais.jpg");
colorReduce(image, );
cv::imshow("reduce image", image);
cv::waitKey(); return ;
}
void colorReduce(cv::Mat &image, int div)
{
int nl = image.rows;
int nc = image.cols;
//图像是连续存储的吗?
if (image.isContinuous())
{
nc = nc*nl;
nl = ;
}
//用来对像素值进行取整的二进制掩模
int n = static_cast<int>(log(static_cast<double>(div)) / log(2.0));
uchar mask = 0xFF << n;
//对每个像素
for (int j = ; j < nl; j++)
{
//第j行的地址
uchar *data = image.ptr<uchar>(j);
for (int i = ; i < nc; i++)
{
//处理每个像素--------------------------------------------
*data++ = *data&mask + div / ;
*data++ = *data&mask + div / ;
*data++ = *data&mask + div / ;
//像素处理结束
}
}
}
代码中同时加入了图像是否连续存储的检测,可以将原本的行列双重循环精简为单层循环。
2.6 遍历图像和领域操作
在图像处理中,通过当前位置的相邻像素计算新的像素值是很常见的操作。当邻域包含图像的前几行和下几行时,你就需要同时扫描图像的若干行。
准备工作
这个例子对图像进行锐化。它基于拉普拉斯算子。一幅图像减去它经过拉普拉斯滤波之后的图像,这幅图像的边缘部分将得到放大,即细节部分更加锐利。这个锐化算子的计算方式如下:
sharpened_pixel = *current - left - right - up - down;
实现方法
void sharpen(cv::Mat &image, cv::Mat &result)
{
result.create(image.size(), image.type());//分配图像内存
int nchannels = image.channels();//图像通道数
for (int i = ; i < image.rows - ; i++)//对于每个遍历行
{
const uchar* previous = image.ptr<const uchar>(i - );//上一行
const uchar* current = image.ptr<const uchar>(i);//当前行
const uchar* next = image.ptr<const uchar>(i + );//下一行
uchar* output = result.ptr<uchar>(i);//输出行
for (int j = nchannels; j < (image.cols - )*nchannels; j++)
{
*output++ = cv::saturate_cast<uchar>( * current[j]
- current[j - ] - current[j + ] - previous[j] - next[j]);
}
}
//将未处理的像素设置为0
result.row(0).setTo(cv::Scalar(0));
result.row(result.rows - 1).setTo(cv::Scalar(0));
result.col(0).setTo(cv::Scalar(0));
result.col(result.cols - 1).setTo(cv::Scalar(0));
} int main()
{
cv::Mat image = cv::imread("boldt.jpg");
cv::Mat result;
sharpen(image, result);
cv::imshow("Original", image);
cv::imshow("Laplace", result);
cv::waitKey();
return ;
}
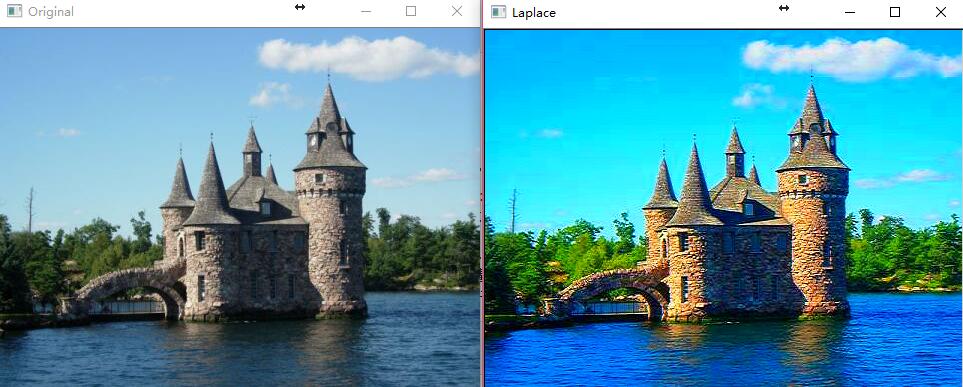
作用原理
为了读写当前像素的上下两个邻域像素,我们需要同时定义两个指向上、下两行的额外指针。在计算输出像素值是,模板函数 cv::saturate_cast 被用来对计算结果进行截断。这是因为对像素值进行数学运算时,经常会导致结果超出像素允许的取值范围,即小于0或者大于255。cv::saturate_cast<uchar>() 函数可以将负值截断为0,将大于255的值截断为255,另外,如果输入参数是浮点型的话,它会对其取整至最接近输入值的整数。很明显,我们还可以使用此函数不同类型的特化版本来将结果值限制在合理的范围之内。
边缘像素之所以不能这样处理是因为它们的邻域不完整,所有需要单独处理。这里我们只是简单地使用 row() 和 col() 方法将其设置为0。这两个方法会返回一个特殊的、仅包含一行(或一列)的cv::Mat 实例。这个过程中,没有任何形式的数据拷贝发生。如果这个一维矩阵的元素遭到了修改,那么原始图像的对应元素也会相应改变。我们正是利用这个特性来修改原始矩阵的值。我们使用 setTo() 函数来设置矩阵的值,这个函数会将矩阵的所有元素设置为指定的值。因此这条语句:
result.row(0).setTo(cv::Scalar(0));
将结果图像的第一行的所有像素值设置为0.对于一个三通道的彩色图像,你需要使用 cv::Scalar(a,b,c) 来指定像素三个通道的目标值。
拓展阅读
实际上,上述操作完全可以用滤波器相卷积的形式完成。卷积核如下图:
由于滤波器是一种常规的图像处理方法,OpenCV定义了一个特殊的函数来完成滤波器处理:cv::filter2D。
void sharpen2D(const cv::Mat &image, cv::Mat &result) {
// Construct kernel (all entries initialized to 0)
cv::Mat kernel(,,CV_32F,cv::Scalar());
// assigns kernel values
kernel.at<float>(,)= 5.0;
kernel.at<float>(,)= -1.0;
kernel.at<float>(,)= -1.0;
kernel.at<float>(,)= -1.0;
kernel.at<float>(,)= -1.0;
//filter the image
cv::filter2D(image,result,image.depth(),kernel);
}
在opencv的Mat.depth()中得到的是一个 0 – 6 的数字,分别代表不同的位数:enum { CV_8U=0, CV_8S=1, CV_16U=2, CV_16S=3, CV_32S=4, CV_32F=5, CV_64F=6 }; 可见 0和1都代表8位, 2和3都代表16位,4和5代表32位,6代表64位;
2.7 进行简单的图像算术
图像间可以进行不同方式组合。因为它们只是一般的矩阵,所以它们可以做加减乘除运算。
实现方法
首先是图像相加。我们通过调用函数 cv::add() ,更准确的说是函数 cv::addWeighted() 函数来完成图像加法,因为我们可能需要的是加权和。函数调用如下:
cv::addWeighted(image, 0.7, image2, 0.9, , result);
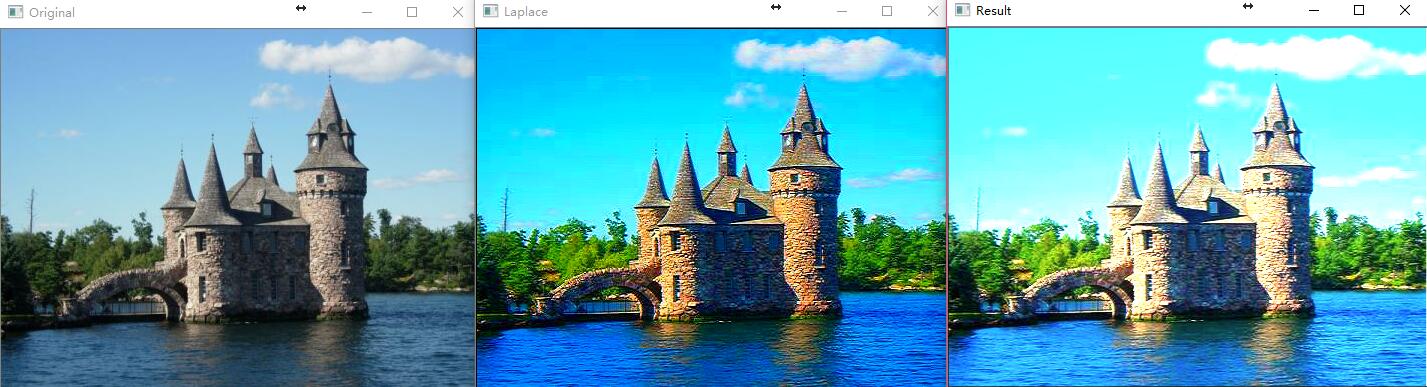
作用原理
所有的二元算术函数工作方式都是一样的,它接受两个输入变量和一个输出变量。在一些情况下,还需要指定权重作为运算中的标量因子。每种函数都有几个不同的形式,cv::add() 是一个很好的例子:
//c[i] = a[i] + b[i];
cv::add(imageA, imageB, resultC);
//c[i] = a[i] + k;
cv::add(imageA, cv::Scalar(k), resultC);
//c[i] = k1*a[i] + k2*b[i] + k3;
cv::addWeighted(imageA, k1, imageB, k2, k3, result);
//c[i] = k*a[i] + b[i];
cv::scaleAdd(imageA, k, imageB, resultC);
对某些函数,你可以指定一个图像掩模:
//if(mask[i]) c[i] = a[i] + b[i]
cv::add(imageA, imageB, result, mask);
如果指定了图像掩模,那么运算会只在掩模对应像素不为 null 的像素上进行(掩模必须是单通道的)。除了add之外, cv::subtract、cv::absdiff(矩阵差的绝对值)、cv::multiply 和 cv::divide 函数也有几种不同的变形。OpenCV 还提供了位运算函数:cv::bitwise_and、cv::bitwise_or、cv::bitwaise_xor、cv::bitwise_not。cv::min 和 cv::max 也非常有用,它们用来找到矩阵中最小或最大的像素值。所有的这些运算都使用了 cv::saturate_cast 来保证输出图像的像素值在合理的范围内。参与运算的图像必须大小和类型相同,由于运算是逐像素进行的,输入图像之一也可以作为输出图像。另外还有一些只接受一个输入的操作符,如 cv::sqrt、cv::pow、cv::abs、cv::cuberoot、cv::exp和cv::log。事实上,OpenCV几乎拥有所有你需要的图像操作符。
扩展阅读
我们同样可以在cv::Mat的实例,甚至cv::Mat实例的通道上使用C++的算术操作符。
重载图像操作符
方便的是,大多数算术函数在Opencv2中都有对应重载的操作符。因此,前面对 cv::addWeighted 的调用可以直接写成:
result = 0.7 * image1 + 0.9*image2;
Most C++ operators have been overloaded. Among them are the bitwise operators &, |, ^,and ~; the min, max, and abs functions. The comparison operators <, <=, ==,!=, >, and >=have also been overloaded, and they return an 8-bit binary image. You will also find the m1*m2 matrix multiplication (where m1 and m2 are both cv::Mat instances), the m1.inv() matrix inversion, the m1.t() transpose, the m1.determinant() determinant, the v1.norm() vector norm, the v1.cross(v2) cross-product, the v1.dot(v2) dot product, and so on. When this makes sense, you also have the corresponding compound assignment operator defined (the += operator, as an example).
有的时候我们可能需要分别或单独处理一幅图像的不同通道。例如:你想只在图像的一个通道上进行一项运算。当然你可以像之前一样使用图像遍历完成这项操作,但是你也可以先使用函数 cv::split 将彩色图像的三个通道分别拷贝到三个独立的 cv::Mat 实例中,然后再对这个通道单独处理。假如我们想把前面使用到的雨滴图像只叠加到蓝色通道上:
// create vector of 3 images
std::vector<cv::Mat> planes;
// split 1 3-channel image into 3 1-channel images
cv::split(image1,planes);
// add to blue channel
planes[]+= image2;
// merge the 3 1-channel images into 1 3-channel image
cv::merge(planes,result);
函数 cv::merge 是 cv::split的对偶运算,它将三个单通道图像合并为一个彩色三通道图像。
2.8 定义感兴趣
假设我们想合并两个不同大小的图像。例如:我们想把下面这个小小的Logo合并到我们的测试图像上。
由于cv::add 要求两个输入图像具有相同的尺寸,所以我们不能直接使用 cv::add,而是需要在使用之前先定义感兴趣区域(ROI)。只要感兴趣区域的大小与Logo图像的大小相同,cv::add 就能工作了。ROI 的位置决定了Logo图像被插入的位置。
实现方法
首先要定义ROI。一旦定义后,ROI就可以被当做一个普通的 cv::Mat 实例来处理。插入Logo的操作可以通过如下代码完成:
int main()
{
cv::Mat image = cv::imread("boldt.jpg");
cv::Mat logo = cv::imread("logo.bmp");
//定义图像ROI
cv::Mat imageROI;
imageROI = image(cv::Rect(, , logo.cols, logo.rows));
//插入logo
cv::addWeighted(imageROI, 1.0, logo, 0.3, , imageROI);
cv::imshow("ROI", image);
cv::waitKey();
return ;
}

由于Logo 图像是直接和原始图像相加的(同时可能会伴随着像素饱和),视觉效果不是很令人满意。所有直接将插入处的像素设置为Logo图像的像素值效果会好一点。
你可以通过使用一个图像掩模来完成:
int main()
{
cv::Mat image = cv::imread("boldt.jpg");
//定义图像ROI
cv::Mat imageROI2;
imageROI2 = image(cv::Rect(, , logo.cols, logo.rows));
//加载掩模(必须是灰度图)
cv::Mat mask = cv::imread("logo.bmp", );
//通过掩模拷贝ROI
logo.copyTo(imageROI2, mask);
cv::imshow("ROI", image);
cv::waitKey();
return ;
}

作用原理
定义ROI的一种方法是使用cv::Rect(x, y, W, H) 来表示一个矩形区域。
另一种定义ROI的方式是指感兴趣行或列的范围(Range)。cv::Range(r1, r2, c1, c2) 是指从起始索引到终止索引(不包含终止索引)的一段连续序列。这样前面的代码可以重写为:
cv::Mat imageRoi = image(cv::Range(, +logo.rows),
cv::Range(, +logo.cols));//行、列范围
cv::Mat 的 ()操作符返回另一个 cv::Mat 实例可以用在接下来的函数调用中。因为ROI和原始图像共享数据缓冲区,对ROI的任何变换都会影响到原始图像的对应区域。
如果想创建原始图像特定行的ROI,可以使用如下代码:
cv::Mat imageROI = image.rowRange(start, end);//不包含end行
类似地,对于列:
cv::Mat imageROI = image.colRange(start, end);//不包含end列
在之前“遍历图像和邻域操作”中的 row 和 col 方法其实是rowRange 和 colRange方法的特例,即end=start+1。
最新文章
- SharePoint 2013 工作流平台的选项不可用
- 作业三:WC项目
- coalesce函数用法
- python学习笔记-(六)深copy&浅copy
- PHP内置函数file_put_content(),将数据写入文件,使用FILE_APPEND 参数进行内容追加
- 转载:用Dreamweave cs 5.5+PhoneGap+Jquery Mobile搭建移动开发
- 关于popupwindow的两种实现方式
- [Linux] PHP程序员玩转Linux系列-怎么安装使用
- [Luogu 1559]运动员最佳匹配问题
- maven向本地仓库导入jar包
- Go 语言 map (映射)
- go 通过http发送图片file内容
- 如何写一个好的缺陷(Defect)报告
- oracle 11g(64位)datebase 安装流程
- 胜利大逃亡(杭电hdu1253)bfs简单题
- NOIp模拟赛 巨神兵(状压DP 容斥)
- Revit API通过相交过滤器找到与风管相交的对象。
- POJ 1679 The Unique MST (次小生成树kruskal算法)
- Python文件遍历二种方法
- LeetCode: Symmetric Tree 解题报告